

A forza da curiosidade
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea
Os experimentos e ensaios realizados nos últimos 15 anos sobre o funcionamento do cerebro humano lévannos a unha conclusión similar: os cerebros son máquinas predictoras do futuro. Uno dos que mellor explica esta corrente é o filósofo Andy Clark [1]. Segundo el, a percepción humana non é máis que una alucinación controlada. É dicir, non percibimos a realidade como é; o noso cerebro represéntaa, alucina.
Tomemos un pelotari. Por exemplo, cando ten que queimar un saque, a pelota adoita ir a 100 km/h. Así que o pelotari ten uns milisegundos paira decidir como golpear a pelota. Son malas obras porque tarda máis en chegar os sinais desde os ollos ao cerebro. Pero o cerebro do pelotari, baseándose na experiencia, pode predicir onde estará a pelota en todo momento. O seu corpo móvese a partir desa estimación do cerebro e pode golpear ben a pelota.
Andy Clark defende que os nosos cerebros se forman desde o nacemento paira predicir o futuro. Así, creamos modelos da realidade, modelos que comprendan a dinámica do mundo. E utilizamos estes modelos paira tomar decisións.
Paira comprobar a validez destas ideas pódese utilizar, entre outras cousas, a intelixencia artificial. Así o pensaron os investigadores David Ha e Jürgen Schmidhuber [2].
Modelos de mundo e aprendizaxe por reforzo
A aprendizaxe por reforzo é una forma de aprendizaxe con animais. As súas bases son moi sinxelas. Por exemplo, se queremos que senta a un can ao dicir “sentarse”, debemos ensinalo. Así, se di “sentar” e non fai o que queremos, castigarémolo. Pero si senta, dámoslle un premio. Recibindo premios e castigos, o can aprende que facer cando escoita a orde de “sentar”.
No mundo da intelixencia artificial tamén se utiliza a aprendizaxe por reforzo, ás veces con gran éxito [3]. De forma moi breve pódese observar na figura 1 como funciona un sistema de reforzo.
Pero as solucións de reforzo clásicas teñen dous problemas principais:
1. Só serven paira una tarefa concreta. O apreso na realización dunha tarefa non é aplicable a outra, aínda que haxa grandes similitudes entre ambas as tarefas.
2. Teñen que recibir reforzo case en todo momento. En moitas das tarefas do mundo real non se pode recibir o reforzo ata que finalice a tarefa. Por exemplo, se queremos adestrar a unha máquina paira construír un castelo cunhas cartas, non podemos darlle reforzos ata que o castelo estea terminado.
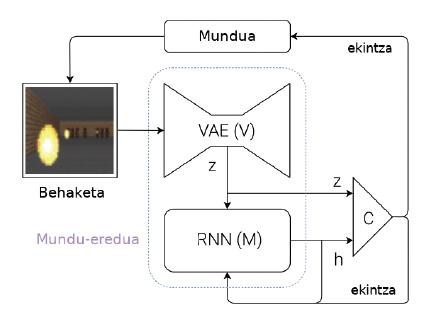
Paira superar estes problemas, Ha e Schmidhuber propoñen un sistema capaz de aprender modelos de mundo (figura 2). Explicemos brevemente cal é a súa idea: cada vez que una máquina recibe una observación (por exemplo, una imaxe con cámara), debe representar primeiro a información que recibiu. Paira iso utilizan unhas redes neuronais especiais, denominadas en inglés Variational Auto-Encoders (VAE) (módulo V da figura 2). Pensemos que este VAE xera un resumo das características máis importantes que aparecen nunha imaxe por cámara (Z da figura 2, onde Z é un vector de números). Esta observación obtida nese momento convértese nunha das entradas do módulo M. O módulo M é outra rede neuronal (neste caso, una rede recursiva: RNN). O módulo M ten como obxectivo predicir cal será a próxima observación (Z) que verá a máquina utilizando a última acción executada e a memoria (h). No caso do pelotari, o módulo M diría onde estará a pelota no futuro, tendo en conta os últimos movementos do pelotari e a dinámica do mundo.
Paira finalizar, partindo da observación actual (Z) e da observación esperada paira o futuro (h), utilízase un controlador simple (C) paira decidir cal será o seguinte movemento da máquina. O controlador, neste caso, é una rede neuronal simple que aprende por reforzo. Pero o modelo mundial (módulos V e M) non se adestra por reforzo, polo que non ten relación cunha tarefa concreta. En teoría, os seres humanos construímos modelos de mundo de forma independente das tarefas que queremos realizar e son útiles paira todas as tarefas. Cando aprendemos a dinámica dunha pelota, é dicir, cando o noso cerebro crea o modelo do movemento da pelota, somos capaces de utilizar este modelo en moitos deportes como a pelota, o tenis, o fútbol ou o baloncesto. As accións a executar en cada deporte son diferentes, xa que teñen normas e obxectivos diferentes, pero a dinámica do balón ou a pelota é a mesma. Por tanto, paira cada deporte pódense aprender controladores mediante reforzos pero compartindo modelos de mundo.
Como se forman estes modelos de mundo? Simplemente anticipando observacións futuras. No caso das redes neuronais, dariamos una observación momentánea aos módulos V e M e deberían predicir a observación do momento seguinte. É dicir, o seu obxectivo é minimizar a diferenza entre o que predín e o que ven a continuación. E así aprenden a facer mellores predicións. Ten en conta que esta aprendizaxe non ten nada que ver cunha tarefa concreta.
Formulando curiosidade
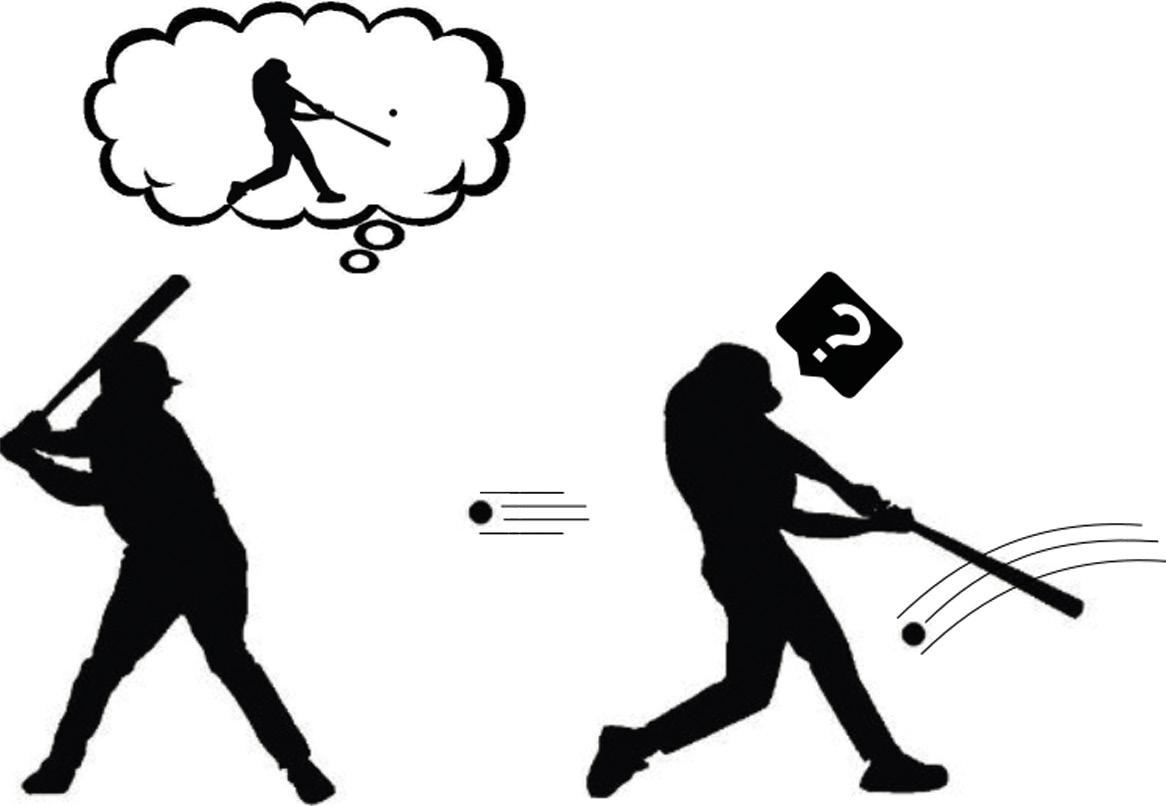
Supoñamos entón que xa sabemos como crear un modelo de mundo paira calquera tarefa. Axúdanos a entender a curiosidade ese modelo de mundo capaz de predicir o futuro? Segundo Andy Clark, o noso cerebro predí o futuro, pero leva una gran sorpresa cando ese futuro que predí non ten nada que ver co que realmente observa. Estes desacordos demostran que o noso modelo de mundo non é o suficientemente bo. Por tanto, o noso cerebro presta especial atención a estes momentos. Analiza estas estrañas observacións, executa diversas accións e busca o porqué da súa sorpresa (Figura 3). Non é esa curiosidade? Bingo!
Dito desta maneira, parece que non é tan difícil formular a curiosidade: comparemos a predición que xera o modelo mundial coa que realmente se viu; si son similares, esa situación é coñecida e, por tanto, non temos que estudala máis; pero si son moi diferentes, encaixe a nosa curiosidade. Seguindo as ideas da aprendizaxe por reforzo, que a máquina recolla o premio cada vez que atope situacións que non poida predicir ben polas súas accións. E así, a máquina aprenderá xogando coa súa contorna, como o fan os nenos pequenos. O reforzo así formulado coñécese como reforzo espontáneo ou motivación.
Aprendizaxe guiada pola curiosidade
O centro de investigación OpenAI quixo analizar a forza da curiosidade [4]. Paira iso tomaron unha chea de videoxogos clásicos cos que adestraron as súas máquinas. Estas máquinas baseábanse en modelos de mundo capaces de predicir o futuro. E como dixemos antes, formulaban a curiosidade. É dicir, tendo en conta as diferenzas entre o anunciado e o efectivamente observado.
Estes xogos teñen diferentes obxectivos que se reflicten na función de reforzo. Pero este reforzo foi descartado polos investigadores de Openai, utilizando só a curiosidade. Por tanto, as máquinas recibían premios cando as súas accións levábanas a novas situacións, difíciles de predicir. Pódese dicir que se trata de máquinas formadas por pura motivación.
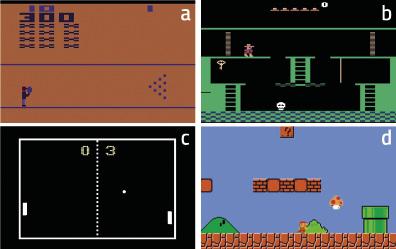
Os resultados foron sorprendentes. Por exemplo, a máquina aprendeu a superar con curiosidade o xogo Bowling (figura 4.a). Segundo os investigadores, a clave paira explicar este resultado é que apareza a puntuación na pantalla. Se a máquina tira moitas bólas, a puntuación cambia moito. Por tanto, en principio, estas situacións son as máis difíciles de predicir, é dicir, as que provocan maiores cambios na observación. No caso de Pong, figura 4.c, a máquina aprende a manter a pelota xogando durante moito tempo, pero non a gañar. Con todo, está claro que estuda perfectamente a dinámica do mundo. Tamén no caso de Super Mario Bros (Figura 4.d) aprende a superar o xogo por pura curiosidade.
O máis sorprendente, con todo, ocorreu no Montezuma’s Revenge (Figura 4.b). Este xogo é hoxe moi complexo paira as máquinas, xa que require grandes capacidades exploratorias e os reforzos son moi raros. Este xogo é similar aos scape room que están tan de moda na actualidade: hai que ir completando os puzzles paira completar as distintas estancias e superar o xogo. Os reforzos chegan cando salguen de cada habitación (se salguen, premio; se non, castigo). As máquinas até agora non puideron achegarse ás puntuacións dos seres humanos, xa que non recibían reforzos ao tentar explorar os diferentes obxectos de cada aula e liberar os puzzles. A máquina, que se formou só con curiosidade, tivo resultados similares aos humanos! En definitiva, a curiosidade impulsa á máquina a explorar obxectos e recunchos raros de cada clase, e aí está a clave.
Paira terminar
O noso cerebro é moi complexo. A percepción, a capacidade de predicir o futuro e a curiosidade non son máis que uns poucos elementos da paisaxe cerebral. Pero xa foron capaces de xerar importantes avances no campo da intelixencia artificial. Parece que detrás destas atractivas ideas pódese apreciar trázaa da verdade. Por tanto, teremos que seguir investigando paira comprender correctamente esas ideas que parecen tan poderosas e poder buscar novas solucións. A memoria a curto e longo prazo, a aprendizaxe interactiva ou a aprendizaxe cooperativa son liñas de investigación xa abertas [5]. Hai que seguir traballando, porque a curiosidade impúlsanos.
Bibliografía
Zu idazle
Zientzia aldizkaria

- Babesleak
-

-

Elhuyar
Nor gara | Kontaktua |
Publizitatea
| Laguntza
Pribatutasun politika | Cookien politika
ISSN-2603-6614 Elhuyar