

The strength of curiosity
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea
The experiments and tests carried out in the last 15 years on the functioning of the human brain lead to a similar conclusion: the brains are predictors of the future. One of those who best explains this current is the philosopher Andy Clark [1]. According to him, human perception is nothing more than a controlled hallucination. That is, we do not perceive reality as it is; our brain represents it, it alludes.
Take a pelotari. For example, when you have to burn a spray, the ball is usually 100 km/h. So the pelotari has a few milliseconds to decide how to hit the ball. They are bad works because it takes longer to get signals from the eyes to the brain. But the brain of the pelotari, based on experience, can predict where the ball will be at all times. Your body moves from that estimate of the brain and can hit the ball well.
Andy Clark defends that our brains are formed from birth to predict the future. Thus, we create models of reality, models that understand the dynamics of the world. And we use these models to make decisions.
To verify the validity of these ideas, artificial intelligence can be used, among other things. This was thought by researchers David Ha and Jürgen Schmidhuber [2].
World models and learning by reinforcement
Reinforcement learning is a form of animal learning. Its bases are very simple. For example, if we want a dog to sit down when saying “sit down”, we must teach it. So, if he says “sit” and does not do what we want, we will punish him. But if you feel, we give you a prize. Receiving prizes and punishments, the dog learns what to do when listening to the order of “sitting”.
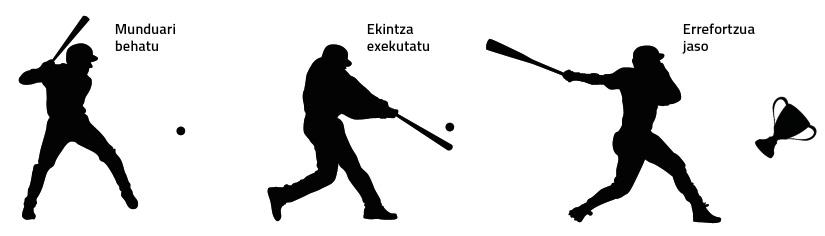
In the world of artificial intelligence, reinforcement learning is also used, sometimes with great success [3]. In very brief, figure 1 shows how a reinforcement system works.
But classic reinforcement solutions have two main problems:
1. They only serve for a specific task. What is learned in carrying out a task is not applicable to another task, although there are great similarities between both tasks.
2. They have to receive reinforcement almost at all times. In many of the real-world tasks, reinforcement cannot be received until the task is finished. For example, if we want to train a machine to build a castle with cards, we can't give you reinforcements until the castle is finished.
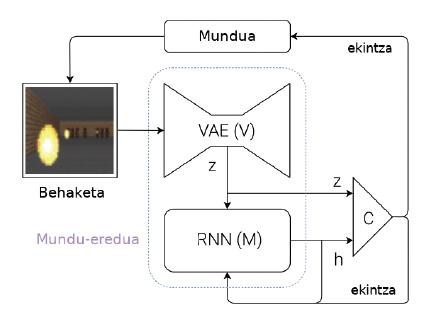
To overcome these problems, Ha and Schmidhuber propose a system capable of learning world models (Figure 2). Let's briefly explain what your idea is: whenever a machine receives an observation (for example, a camera image), it must first represent the information it has received. For this purpose they use special neural networks, called Variational Auto-Encoders (VAE) (V module of figure 2). Let's think that this VAE generates a summary of the most important features that appear in a camera image (Z figure 2, where Z is a number vector). This observation obtained at that time becomes one of the inputs of the M module. The M module is another neuronal network (in this case, a recursive network: RNN). The M module aims to predict what will be the next observation (Z) that will see the machine using the last executed action and memory (h). In the case of the pelotari, the M module would say where the ball will be in the future, taking into account the last movements of the pelotari and the dynamics of the world.
To finish, starting from the current observation (Z) and the expected observation for the future (h), a simple controller (C) is used to decide which will be the next movement of the machine. The controller, in this case, is a simple neuronal network that learns by reinforcement. But the world model (modules V and M) is not trained by reinforcement, so it is not related to a specific task. In theory, human beings build world models independently of the tasks we want to perform and are useful for all tasks. When we learn the dynamics of a ball, that is, when our brain creates the model of the movement of the ball, we are able to use this model in many sports such as ball, tennis, football or basketball. The actions to be performed in each sport are different, since they have different rules and objectives, but the dynamics of the ball or ball is the same. Therefore, for each sport, controllers can be learned through reinforcements, but sharing models of the world.
How are these world models formed? Simply anticipating future observations. In the case of neuronal networks, we would give a momentary observation to modules V and M and should predict the observation of the next moment. That is, your goal is to minimize the difference between what you preach and what you see below. And so they learn to make better predictions. Note that this learning has nothing to do with a specific task.
Making curiosity
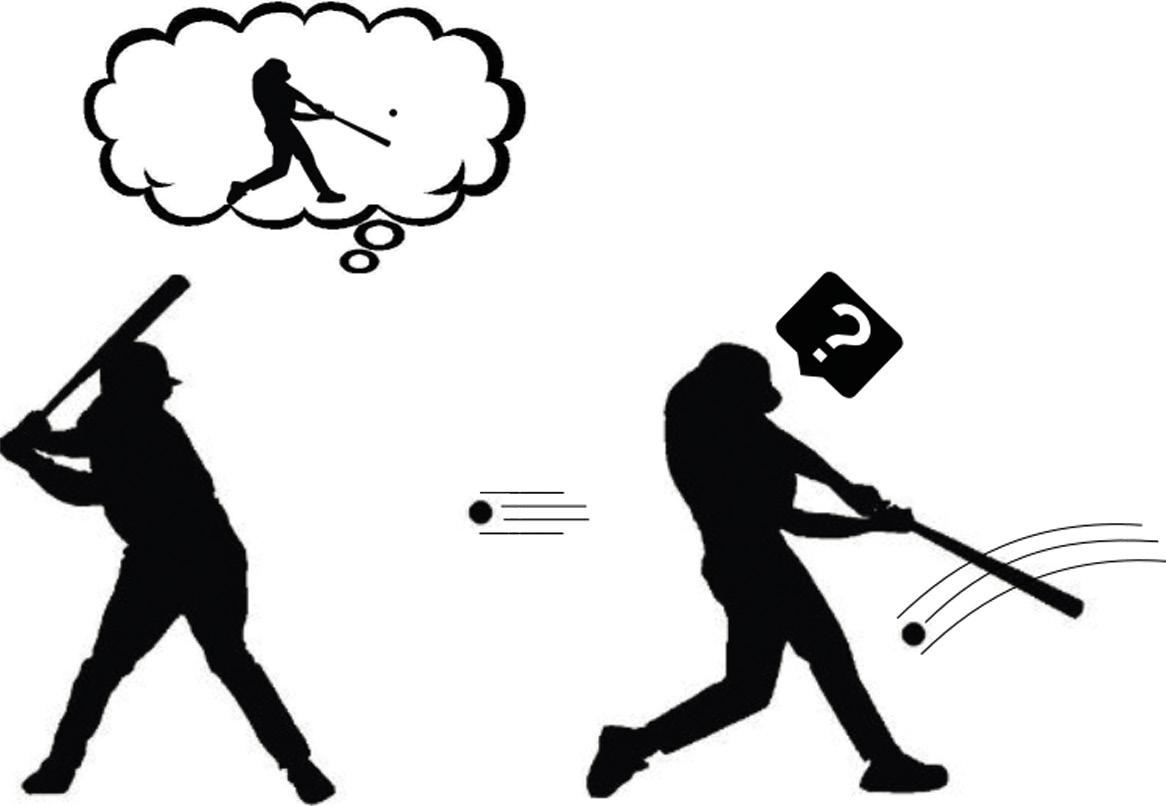
Suppose then that we already know how to create a world model for any task. Does it help us to understand curiosity that model of world capable of predicting the future? According to Andy Clark, our brain predicts the future, but it takes a big surprise when that predictive future has nothing to do with what it really observes. These disagreements show that our world model is not good enough. Therefore, our brain pays special attention to these moments. He analyzes these strange observations, executes various actions and seeks the reason for his surprise (Figure 3). Is it not that curiosity? Bingo!
Put this way, it seems that it is not so difficult to formulate curiosity: let's compare the prediction that generates the world model with which it has really been seen; if they are similar, that situation is known and, therefore, we do not have to study it anymore; but if they are very different, it fits our curiosity. Following the ideas of reinforcement learning, the machine picks up the prize whenever it finds situations that it can not predict well for its actions. And so, the machine will learn by playing with its environment, as young children do. The reinforcement so formulated is known as spontaneous reinforcement or motivation.
Learning guided by curiosity
The OpenAI research center wanted to analyze the strength of curiosity [4]. To do this they took a lot of classic video games with which they trained their machines. These machines were based on world models capable of predicting the future. And, as we said before, they formulated curiosity. That is, taking into account the differences between the announced and the effectively observed.
These games have different objectives that are reflected in the reinforcement function. But this reinforcement was ruled out by Openai researchers, using only curiosity. Therefore, the machines received prizes when their actions took them to new situations, difficult to predict. It can be said that these are machines formed by pure motivation.
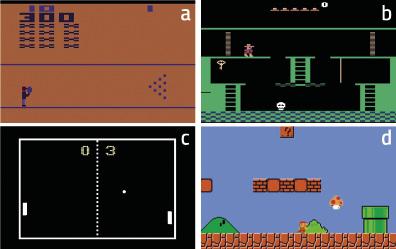
The results were surprising. For example, the machine learned to overcome with curiosity the game Bowling (figure 4.a). According to the researchers, the key to explaining this result is that the score appears on the screen. If the machine pulls many balls, the score changes a lot. Therefore, in principle, these situations are the most difficult to predict, that is, those that cause major changes in observation. In the case of Pong, figure 4.c, the machine learns to keep the ball playing for a long time, but not to win. However, it is clear that he studies perfectly the dynamics of the world. Also in the case of Super Mario Bros (Figure 4.d) learns to overcome the game by pure curiosity.
The most surprising, however, occurred in the Montezuma’s Revenge (Figure 4.b). This game is today very complex for machines, as it requires great exploratory capabilities and reinforcements are very rare. This game is similar to the scape room that are so fashionable today: you have to go completing the puzzles to complete the different rooms and overcome the game. Reinforcements come when they leave each room (if they leave, prize; if not, punishment). The machines so far have not been able to approach the scores of human beings, since they did not receive reinforcements when trying to explore the different objects of each classroom and release the puzzles. The machine, which was formed only with curiosity, had similar results to humans! In short, curiosity drives the machine to explore rare objects and corners of each class, and there is the key.
To finish
Our brain is very complex. Perception, the ability to predict the future and curiosity are just a few elements of the cerebral landscape. But they have already been able to generate important advances in the field of artificial intelligence. It seems that behind these attractive ideas you can appreciate the trace of truth. Therefore, we will have to continue investigating to correctly understand those ideas that seem so powerful and to be able to seek new solutions. Short-term and long-term memory, interactive learning or cooperative learning are already open lines of research [5]. We must continue to work, because curiosity drives us.
Bibliography Bibliography Bibliography
Zu idazle
Zientzia aldizkaria

- Babesleak
-

-

Elhuyar
Nor gara | Kontaktua |
Publizitatea
| Laguntza
Pribatutasun politika | Cookien politika
ISSN-2603-6614 Elhuyar