

La força de la curiositat
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea
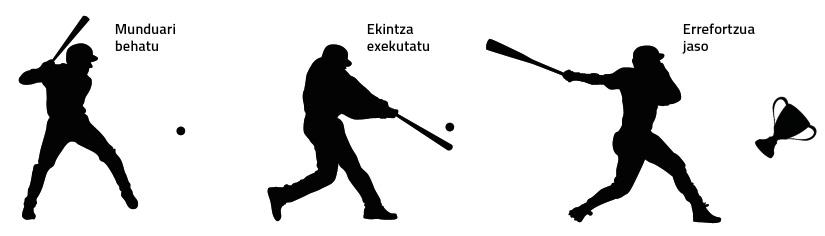
Els experiments i assajos realitzats en els últims 15 anys sobre el funcionament del cervell humà ens porten a una conclusió similar: els cervells són màquines predictores del futur. Un dels quals millor explica aquest corrent és el filòsof Andy Clark [1]. Segons ell, la percepció humana no és més que una al·lucinació controlada. És a dir, no percebem la realitat com és; el nostre cervell la representa, al·lucina.
Prenguem un pilotari. Per exemple, quan ha de cremar un servei, la pilota sol anar a 100 km/h. Així que el pilotari té uns mil·lisegons per a decidir com colpejar la pilota. Són males obres perquè triga més a arribar els senyals des dels ulls al cervell. Però el cervell del pilotari, basant-se en l'experiència, pot predir on estarà la pilota en tot moment. El seu cos es mou a partir d'aquesta estimació del cervell i pot colpejar bé la pilota.
Andy Clark defensa que els nostres cervells es formen des del naixement per a predir el futur. Així, creem models de la realitat, models que comprenguin la dinàmica del món. I utilitzem aquests models per a prendre decisions.
Per a comprovar la validesa d'aquestes idees es pot utilitzar, entre altres coses, la intel·ligència artificial. Així ho van pensar els investigadors David Ha i Jürgen Schmidhuber [2].
Models de món i aprenentatge per reforç
L'aprenentatge per reforç és una forma d'aprenentatge amb animals. Les seves bases són molt senzilles. Per exemple, si volem que se senti a un gos en dir “asseure's”, hem d'ensenyar-lo. Així, si diu “asseure's” i no fa el que volem, ho castigarem. Però si se senti, li donem un premi. Rebent premis i càstigs, el gos aprèn què fer quan escolta l'ordre de “asseure's”.
En el món de la intel·ligència artificial també s'utilitza l'aprenentatge per reforç, a vegades amb gran èxit [3]. De forma molt breu es pot observar en la figura 1 com funciona un sistema de reforç.
Però les solucions de reforç clàssiques tenen dos problemes principals:
1. Només serveixen per a una tasca concreta. L'après en la realització d'una tasca no és aplicable a una altra, encara que hi hagi grans similituds entre totes dues tasques.
2. Han de rebre reforç gairebé en tot moment. En moltes de les tasques del món real no es pot rebre el reforç fins que finalitzi la tasca. Per exemple, si volem entrenar a una màquina per a construir un castell amb unes cartes, no podem donar-li reforços fins que el castell estigui acabat.
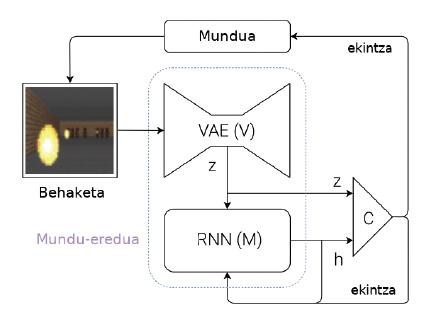
Per a superar aquests problemes, Ha i Schmidhuber proposen un sistema capaç d'aprendre models de món (figura 2). Explicemos breument quina és la seva idea: cada vegada que una màquina rep una observació (per exemple, una imatge amb cambra), ha de representar primer la informació que ha rebut. Per a això utilitzen unes xarxes neuronals especials, denominades en anglès Variational Acte-Encoders (VAE) (mòdul V de la figura 2). Pensem que aquest VAE genera un resum de les característiques més importants que apareixen en una imatge per cambra (Z de la figura 2, on Z és un vector de números). Aquesta observació obtinguda en aquest moment es converteix en una de les entrades del mòdul M. El mòdul M és una altra xarxa neuronal (en aquest cas, una xarxa recursiva: RNN). El mòdul M té com a objectiu predir quina serà la pròxima observació (Z) que veurà la màquina utilitzant l'última acció executada i la memòria (h). En el cas del pilotari, el mòdul M diria on estarà la pilota en el futur, tenint en compte els últims moviments del pilotari i la dinàmica del món.
Per a finalitzar, partint de l'observació actual (Z) i de l'observació esperada per al futur (h), s'utilitza un controlador simple (C) per a decidir quin serà el següent moviment de la màquina. El controlador, en aquest cas, és una xarxa neuronal simple que aprèn per reforç. Però el model mundial (mòduls V i M) no s'entrena per reforç, per la qual cosa no té relació amb una tasca concreta. En teoria, els éssers humans construïm models de món de manera independent de les tasques que volem realitzar i són útils per a totes les tasques. Quan aprenem la dinàmica d'una pilota, és a dir, quan el nostre cervell crea el model del moviment de la pilota, som capaces d'utilitzar aquest model en molts esports com la pilota, el tennis, el futbol o el bàsquet. Les accions a executar en cada esport són diferents, ja que tenen normes i objectius diferents, però la dinàmica de la pilota o la pilota és la mateixa. Per tant, per a cada esport es poden aprendre controladors mitjançant reforços però compartint models de món.
Com es formen aquests models de món? Simplement anticipant observacions futures. En el cas de les xarxes neuronals, donaríem una observació momentània als mòduls V i M i haurien de predir l'observació del moment següent. És a dir, el seu objectiu és minimitzar la diferència entre el que prediuen i el que veuen a continuació. I així aprenen a fer millors prediccions. Tingues en compte que aquest aprenentatge no té res a veure amb una tasca concreta.
Formulant curiositat
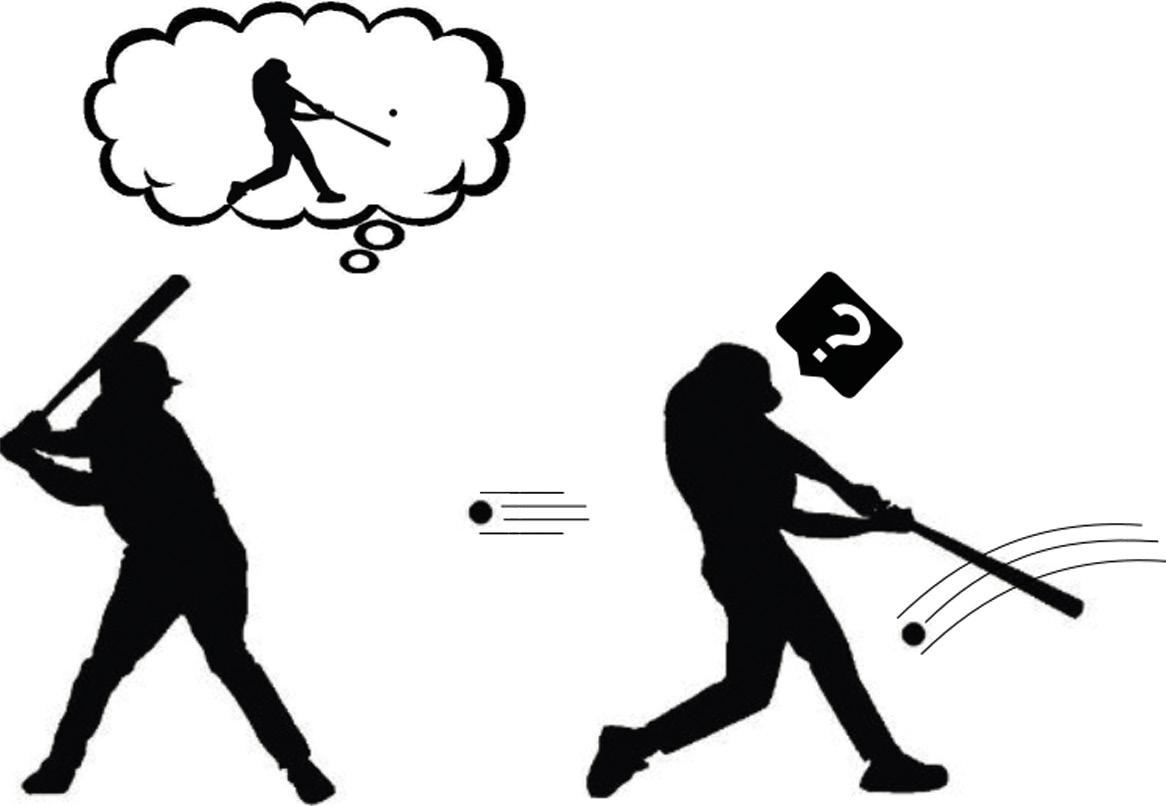
Suposem llavors que ja sabem com crear un model de món per a qualsevol tasca. Ens ajuda a entendre la curiositat aquest model de món capaç de predir el futur? Segons Andy Clark, el nostre cervell prediu el futur, però s'emporta una gran sorpresa quan aquest futur que prediu no té res a veure amb el que realment observa. Aquests desacords demostren que el nostre model de món no és prou bo. Per tant, el nostre cervell presta especial atenció a aquests moments. Analitza aquestes estranyes observacions, executa diverses accions i cerca el perquè de la seva sorpresa (Figura 3). No és aquesta curiositat? Bingo!
Dit d'aquesta manera, sembla que no és tan difícil formular la curiositat: comparem la predicció que genera el model mundial amb la qual realment s'ha vist; si són similars, aquesta situació és coneguda i, per tant, no hem d'estudiar-la més; però si són molt diferents, encaixi la nostra curiositat. Seguint les idees de l'aprenentatge per reforç, que la màquina reculli el premi cada vegada que trobi situacions que no pugui predir bé per les seves accions. I així, la màquina aprendrà jugant amb el seu entorn, com ho fan els nens petits. El reforç així formulat es coneix com a reforç espontani o motivació.
Aprenentatge guiat per la curiositat
El centre de recerca OpenAI va voler analitzar la força de la curiositat [4]. Per a això van prendre un munt de videojocs clàssics amb els quals van entrenar les seves màquines. Aquestes màquines es basaven en models de món capaços de predir el futur. I com hem dit abans, formulaven la curiositat. És a dir, tenint en compte les diferències entre l'anunciat i l'efectivament observat.
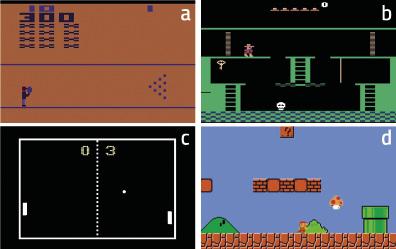
Aquests jocs tenen diferents objectius que es reflecteixen en la funció de reforç. Però aquest reforç va ser descartat pels investigadors d'Openai, utilitzant només la curiositat. Per tant, les màquines rebien premis quan les seves accions les portaven a noves situacions, difícils de predir. Es pot dir que es tracta de màquines formades per pura motivació.
Els resultats van ser sorprenents. Per exemple, la màquina va aprendre a superar amb curiositat el joc Bowling (figura 4.a). Segons els investigadors, la clau per a explicar aquest resultat és que aparegui la puntuació en la pantalla. Si la màquina tira moltes boles, la puntuació canvia molt. Per tant, en principi, aquestes situacions són les més difícils de predir, és a dir, les que provoquen majors canvis en l'observació. En el cas de Pong, figura 4.c, la màquina aprèn a mantenir la pilota jugant durant molt de temps, però no a guanyar. No obstant això, és clar que estudia perfectament la dinàmica del món. També en el cas de Super Mario Bros (Figura 4.d) aprèn a superar el joc per pura curiositat.
El més sorprenent, no obstant això, va ocórrer en el Montezuma’s Revenge (Figura 4.b). Aquest joc és avui molt complex per a les màquines, ja que requereix grans capacitats exploratòries i els reforços són molt estranys. Aquest joc és similar als scape room que estan tan de moda en l'actualitat: cal anar completant els puzles per a completar les diferents estades i superar el joc. Els reforços arriben quan salin de cada habitació (si surten, premi; si no, càstig). Les màquines fins ara no han pogut acostar-se a les puntuacions dels éssers humans, ja que no rebien reforços en intentar explorar els diferents objectes de cada aula i alliberar els puzles. La màquina, que es va formar només amb curiositat, va tenir resultats similars als humans! En definitiva, la curiositat impulsa a la màquina a explorar objectes i racons estranys de cada classe, i aquí està la clau.
Per a acabar
El nostre cervell és molt complex. La percepció, la capacitat de predir el futur i la curiositat no són més que uns pocs elements del paisatge cerebral. Però ja han estat capaços de generar importants avanços en el camp de la intel·ligència artificial. Sembla que darrere d'aquestes atractives idees es pot apreciar la traça de la veritat. Per tant, haurem de continuar investigant per a comprendre correctament aquestes idees que semblen tan poderoses i poder buscar noves solucions. La memòria a curt i llarg termini, l'aprenentatge interactiu o l'aprenentatge cooperatiu són línies de recerca ja obertes [5]. Cal continuar treballant, perquè la curiositat ens impulsa.
Bibliografia
Zu idazle
Zientzia aldizkaria

- Babesleak
-

-

Elhuyar
Nor gara | Kontaktua |
Publizitatea
| Laguntza
Pribatutasun politika | Cookien politika
ISSN-2603-6614 Elhuyar