

La fuerza de la curiosidad
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea
Los experimentos y ensayos realizados en los últimos 15 años sobre el funcionamiento del cerebro humano nos llevan a una conclusión similar: los cerebros son máquinas predictoras del futuro. Uno de los que mejor explica esta corriente es el filósofo Andy Clark [1]. Según él, la percepción humana no es más que una alucinación controlada. Es decir, no percibimos la realidad como es; nuestro cerebro la representa, alucina.
Tomemos un pelotari. Por ejemplo, cuando tiene que quemar un saque, la pelota suele ir a 100 km/h. Así que el pelotari tiene unos milisegundos para decidir cómo golpear la pelota. Son malas obras porque tarda más en llegar las señales desde los ojos al cerebro. Pero el cerebro del pelotari, basándose en la experiencia, puede predecir dónde estará la pelota en todo momento. Su cuerpo se mueve a partir de esa estimación del cerebro y puede golpear bien la pelota.
Andy Clark defiende que nuestros cerebros se forman desde el nacimiento para predecir el futuro. Así, creamos modelos de la realidad, modelos que comprendan la dinámica del mundo. Y utilizamos estos modelos para tomar decisiones.
Para comprobar la validez de estas ideas se puede utilizar, entre otras cosas, la inteligencia artificial. Así lo pensaron los investigadores David Ha y Jürgen Schmidhuber [2].
Modelos de mundo y aprendizaje por refuerzo
El aprendizaje por refuerzo es una forma de aprendizaje con animales. Sus bases son muy sencillas. Por ejemplo, si queremos que se sienta a un perro al decir “sentarse”, debemos enseñarlo. Así, si dice “sentarse” y no hace lo que queremos, lo castigaremos. Pero si se sienta, le damos un premio. Recibiendo premios y castigos, el perro aprende qué hacer cuando escucha la orden de “sentarse”.
En el mundo de la inteligencia artificial también se utiliza el aprendizaje por refuerzo, a veces con gran éxito [3]. De forma muy breve se puede observar en la figura 1 cómo funciona un sistema de refuerzo.
Pero las soluciones de refuerzo clásicas tienen dos problemas principales:
1. Sólo sirven para una tarea concreta. Lo aprendido en la realización de una tarea no es aplicable a otra, aunque haya grandes similitudes entre ambas tareas.
2. Tienen que recibir refuerzo casi en todo momento. En muchas de las tareas del mundo real no se puede recibir el refuerzo hasta que finalice la tarea. Por ejemplo, si queremos entrenar a una máquina para construir un castillo con unas cartas, no podemos darle refuerzos hasta que el castillo esté terminado.
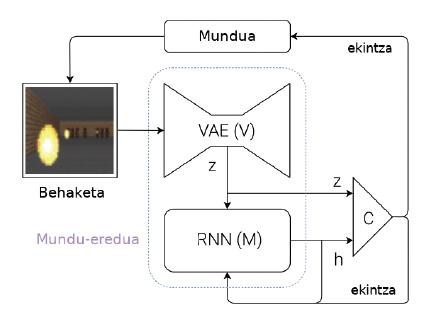
Para superar estos problemas, Ha y Schmidhuber proponen un sistema capaz de aprender modelos de mundo (figura 2). Explicemos brevemente cuál es su idea: cada vez que una máquina recibe una observación (por ejemplo, una imagen con cámara), debe representar primero la información que ha recibido. Para ello utilizan unas redes neuronales especiales, denominadas en inglés Variational Auto-Encoders (VAE) (módulo V de la figura 2). Pensemos que este VAE genera un resumen de las características más importantes que aparecen en una imagen por cámara (Z de la figura 2, donde Z es un vector de números). Esta observación obtenida en ese momento se convierte en una de las entradas del módulo M. El módulo M es otra red neuronal (en este caso, una red recursiva: RNN). El módulo M tiene como objetivo predecir cuál será la próxima observación (Z) que verá la máquina utilizando la última acción ejecutada y la memoria (h). En el caso del pelotari, el módulo M diría dónde estará la pelota en el futuro, teniendo en cuenta los últimos movimientos del pelotari y la dinámica del mundo.
Para finalizar, partiendo de la observación actual (Z) y de la observación esperada para el futuro (h), se utiliza un controlador simple (C) para decidir cuál será el siguiente movimiento de la máquina. El controlador, en este caso, es una red neuronal simple que aprende por refuerzo. Pero el modelo mundial (módulos V y M) no se entrena por refuerzo, por lo que no tiene relación con una tarea concreta. En teoría, los seres humanos construimos modelos de mundo de forma independiente de las tareas que queremos realizar y son útiles para todas las tareas. Cuando aprendemos la dinámica de una pelota, es decir, cuando nuestro cerebro crea el modelo del movimiento de la pelota, somos capaces de utilizar este modelo en muchos deportes como la pelota, el tenis, el fútbol o el baloncesto. Las acciones a ejecutar en cada deporte son diferentes, ya que tienen normas y objetivos diferentes, pero la dinámica del balón o la pelota es la misma. Por tanto, para cada deporte se pueden aprender controladores mediante refuerzos pero compartiendo modelos de mundo.
¿Cómo se forman estos modelos de mundo? Simplemente anticipando observaciones futuras. En el caso de las redes neuronales, daríamos una observación momentánea a los módulos V y M y deberían predecir la observación del momento siguiente. Es decir, su objetivo es minimizar la diferencia entre lo que predicen y lo que ven a continuación. Y así aprenden a hacer mejores predicciones. Ten en cuenta que este aprendizaje no tiene nada que ver con una tarea concreta.
Formulando curiosidad
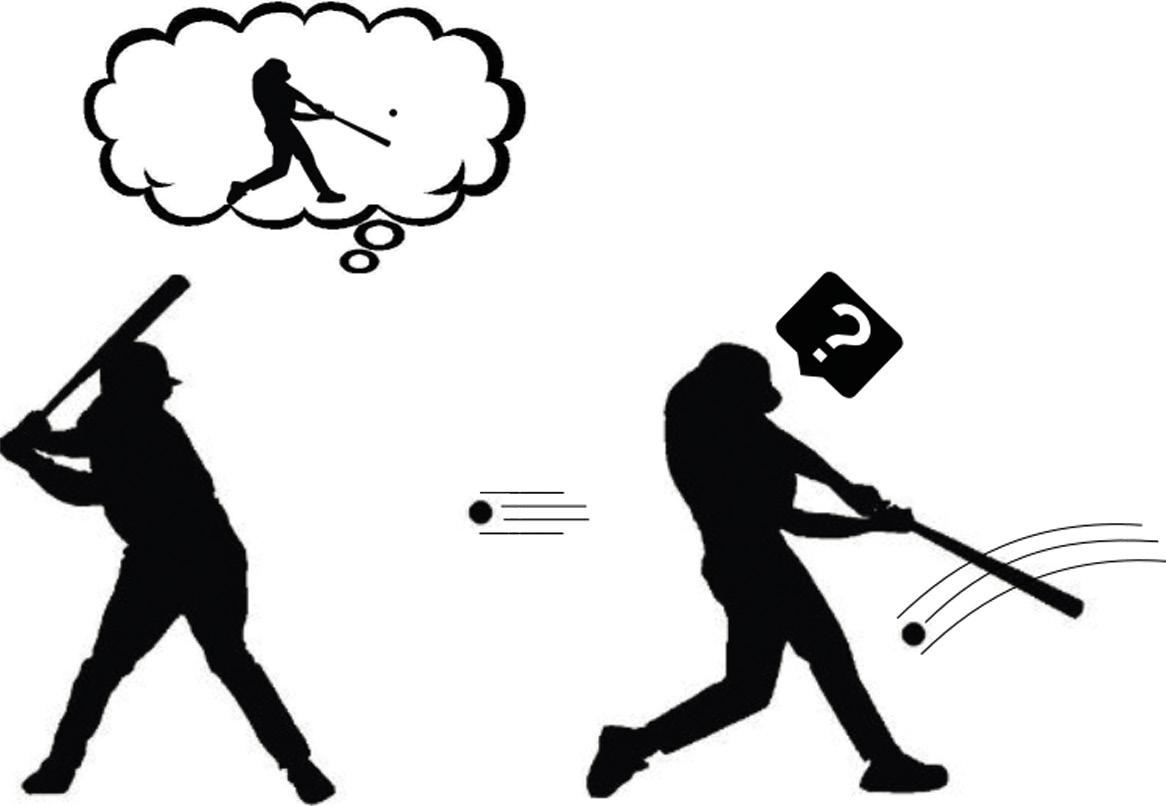
Supongamos entonces que ya sabemos cómo crear un modelo de mundo para cualquier tarea. ¿Nos ayuda a entender la curiosidad ese modelo de mundo capaz de predecir el futuro? Según Andy Clark, nuestro cerebro predice el futuro, pero se lleva una gran sorpresa cuando ese futuro que predice no tiene nada que ver con lo que realmente observa. Estos desacuerdos demuestran que nuestro modelo de mundo no es lo suficientemente bueno. Por lo tanto, nuestro cerebro presta especial atención a estos momentos. Analiza estas extrañas observaciones, ejecuta diversas acciones y busca el porqué de su sorpresa (Figura 3). ¿No es esa curiosidad? ¡Bingo!
Dicho de esta manera, parece que no es tan difícil formular la curiosidad: comparemos la predicción que genera el modelo mundial con la que realmente se ha visto; si son similares, esa situación es conocida y, por tanto, no tenemos que estudiarla más; pero si son muy diferentes, encaje nuestra curiosidad. Siguiendo las ideas del aprendizaje por refuerzo, que la máquina recoja el premio cada vez que encuentre situaciones que no pueda predecir bien por sus acciones. Y así, la máquina aprenderá jugando con su entorno, como lo hacen los niños pequeños. El refuerzo así formulado se conoce como refuerzo espontáneo o motivación.
Aprendizaje guiado por la curiosidad
El centro de investigación OpenAI quiso analizar la fuerza de la curiosidad [4]. Para ello tomaron un montón de videojuegos clásicos con los que entrenaron sus máquinas. Estas máquinas se basaban en modelos de mundo capaces de predecir el futuro. Y como hemos dicho antes, formulaban la curiosidad. Es decir, teniendo en cuenta las diferencias entre lo anunciado y lo efectivamente observado.
Estos juegos tienen diferentes objetivos que se reflejan en la función de refuerzo. Pero este refuerzo fue descartado por los investigadores de Openai, utilizando sólo la curiosidad. Por lo tanto, las máquinas recibían premios cuando sus acciones las llevaban a nuevas situaciones, difíciles de predecir. Se puede decir que se trata de máquinas formadas por pura motivación.
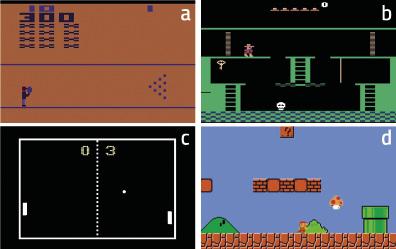
Los resultados fueron sorprendentes. Por ejemplo, la máquina aprendió a superar con curiosidad el juego Bowling (figura 4.a). Según los investigadores, la clave para explicar este resultado es que aparezca la puntuación en la pantalla. Si la máquina tira muchas bolas, la puntuación cambia mucho. Por lo tanto, en principio, estas situaciones son las más difíciles de predecir, es decir, las que provocan mayores cambios en la observación. En el caso de Pong, figura 4.c, la máquina aprende a mantener la pelota jugando durante mucho tiempo, pero no a ganar. Sin embargo, está claro que estudia perfectamente la dinámica del mundo. También en el caso de Super Mario Bros (Figura 4.d) aprende a superar el juego por pura curiosidad.
Lo más sorprendente, sin embargo, ocurrió en el Montezuma’s Revenge (Figura 4.b). Este juego es hoy muy complejo para las máquinas, ya que requiere grandes capacidades exploratorias y los refuerzos son muy raros. Este juego es similar a los scape room que están tan de moda en la actualidad: hay que ir completando los puzzles para completar las distintas estancias y superar el juego. Los refuerzos llegan cuando salen de cada habitación (si salen, premio; si no, castigo). Las máquinas hasta ahora no han podido acercarse a las puntuaciones de los seres humanos, ya que no recibían refuerzos al intentar explorar los diferentes objetos de cada aula y liberar los puzzles. La máquina, que se formó sólo con curiosidad, ¡tuvo resultados similares a los humanos! En definitiva, la curiosidad impulsa a la máquina a explorar objetos y rincones raros de cada clase, y ahí está la clave.
Para terminar
Nuestro cerebro es muy complejo. La percepción, la capacidad de predecir el futuro y la curiosidad no son más que unos pocos elementos del paisaje cerebral. Pero ya han sido capaces de generar importantes avances en el campo de la inteligencia artificial. Parece que detrás de estas atractivas ideas se puede apreciar la traza de la verdad. Por lo tanto, tendremos que seguir investigando para comprender correctamente esas ideas que parecen tan poderosas y poder buscar nuevas soluciones. La memoria a corto y largo plazo, el aprendizaje interactivo o el aprendizaje cooperativo son líneas de investigación ya abiertas [5]. Hay que seguir trabajando, porque la curiosidad nos impulsa.
Bibliografía
Zu idazle
Zientzia aldizkaria

- Babesleak
-

-

Elhuyar
Nor gara | Kontaktua |
Publizitatea
| Laguntza
Pribatutasun politika | Cookien politika
ISSN-2603-6614 Elhuyar