

Jakin-minaren indarra
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea
Azken 15 urteotan giza garunaren funtzionamenduaren inguruan egin diren hainbat esperimentu eta saiakerek antzeko ondorio bat ateratzera garamatzate: etorkizuna aurresateko makinak dira garunak. Korronte hori ongien azaltzen duenetariko bat Andy Clark filosofoa da [1]. Haren arabera, giza pertzepzioa kontrolpean gertatzen den haluzinazioa besterik ez da. Hots, ez dugu errealitatea den bezala hautematen; gure garunak irudikatu egiten du, haluzinatu.
Har dezagun pilotari bat. Sake bat errestatu behar duenean, adibidez, pilota 100 km/h-ko abiaduran joan ohi da. Beraz, pilotariak milisegundo batzuk ditu erabakitzeko nola jo behar duen pilota. Lan txarrak dira horiek, begietatik garunera seinaleak iristeko denbora gehiago behar baitu. Baina pilotariaren garunak, esperientzian oinarrituta, aurresan dezake pilota non egongo den une oro. Garunaren estimazio horretan oinarrituta mugitzen da bere gorputza, eta behar bezala jo dezake pilota.
Andy Clarkek defendatzen duenaren arabera, gure garunak jaiotzetik trebatzen dira etorkizuna aurresateko. Hala, errealitatearen ereduak sortzen ditugu, munduaren dinamika ulertzen duten ereduak. Eta eredu horiek erabiltzen ditugu erabakiak hartzeko.
Ideia horiek baliozkoak direnetz ikusteko, besteak beste, adimen artifiziala erabil daiteke. Hori bera pentsatu zuten David Ha eta Jürgen Schmidhuber ikertzaileek [2].
Mundu-ereduak eta errefortzu bidezko ikasketa
Errefortzu bidezko ikasketa animaliekin erabiltzen den ikasketa-modu bat da. Oso oinarri sinpleak ditu. Adibidez, zakur bati “eseri” esatean eser dadin nahi badugu, irakatsi egin beharko diogu. Horrela, “eseri” esan eta ez badu egiten guk nahi duguna, zigortu egingo dugu. Baina esertzen bada, sari bat emango diogu. Sariak eta zigorrak jasoz, zakurrak ikasi egiten du zer egin behar duen “eseri” agindua entzuten duenean.
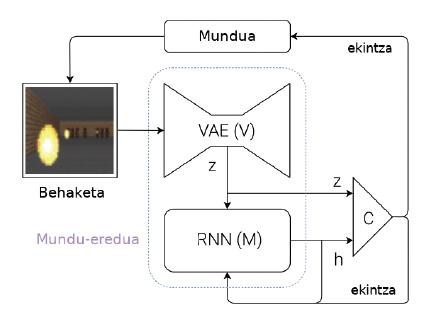
Adimen artifizialaren munduan ere errefortzu bidezko ikasketa erabiltzen da, batzuetan arrakasta handiz, gainera [3]. Oso modu laburrean, 1. irudian ikus daiteke errefortzu bidezko sistema batek nola funtzionatzen duen.
Baina errefortzu bidezko soluzio klasikoek bi arazo nagusi izaten dituzte:
1. Ataza jakin baterako bakarrik balio dute. Ataza bat egiten ikasitakoa ezin da beste ataza batean aplikatu, nahiz eta bi atazen artean antzekotasun handiak egon.
2. Errefortzua jaso behar izaten dute ia une oro. Mundu errealeko ataza askotan, ezin da errefortzua jaso ataza amaitu arte. Esaterako, makina bat trebatu nahi badugu karta batzuekin gaztelu bat eraikitzeko, ezin diogu errefortzurik eman gaztelua bukatu artean.
Arazo horiek gainditzeko, mundu-ereduak ikasteko gai den sistema bat proposatzen dute Hak eta Schmidhuberrek (2. irudia). Azal dezagun labur haien ideia zein den: makina batek behaketa bat jasotzen duen bakoitzean (kamera bidezko irudi bat, adibidez), jaso duen informazio hori errepresentatu behar du lehendabizi. Horretarako, sare neuronal berezi batzuk erabiltzen dituzte: ingelesez, Variational Auto-Encoders (VAE) deitzen zaie (2. irudiko V modulua). Pentsa dezagun kamera bidezko irudi batean agertzen diren ezaugarri garrantzitsuenen laburpen bat sortzen duela VAE horrek (2. irudiko Z, non Z zenbakien bektore bat den). Une horretan jasotako behaketa hori M moduluaren sarreretako bat bilakatzen da. M modulua beste sare neuronal bat da (kasu honetan, sare errekurtsibo bat: RNN). Une honetako behaketa (Z), exekutatutako azken ekintza eta memoria erabiliz (h), makinak ikusiko duen hurrengo behaketa zein izango den aurresatea du helburu M moduluak. Pilotariaren kasuan, M moduluak esango luke pilota non egongo den etorkizunean, pilotariaren azken mugimenduak eta munduaren dinamika kontuan hartuz.
Amaitzeko, une honetako behaketa (Z) eta etorkizunerako espero dugun behaketa (h) abiapuntu harturik, kontrolagailu sinple bat erabiltzen da (C) makinaren hurrengo mugimendua zein izango den erabakitzeko. Kontrolagailua, kasu honetan, sare neuronal sinple bat da, eta errefortzu bidez ikasten du. Baina mundu-eredua (V eta M moduluak) ez da errefortzu bidez entrenatzen, eta, beraz, ez du loturarik ataza jakin batekiko. Teorian, egin nahi ditugun atazekiko modu independentean eraikitzen ditugu gizakiok mundu-ereduak, eta baliagarriak dira ataza guztietarako. Pilota baten dinamika ikasten dugunean, hots, pilotaren mugimenduaren eredua sortzen duenenean gure garunak, gai gara eredu hori kirol askotan erabiltzeko: pilotan, tenisean, futbolean eta saskibaloian, esaterako. Kirol bakoitzean exekutatu beharreko ekintzak ezberdinak dira, arau eta helburu ezberdinak baitituzte, baina baloiaren ala pilotaren dinamika bera da. Beraz, kirol bakoitzerako kontrolagailuak ikas daitezke errefortzu bidez, baina mundu-ereduak partekatuz.
Nola trebatzen dira, bada, mundu-eredu horiek? Etorkizuneko behaketak aurresaten, besterik gabe. Sare neuronalen kasuan, une bateko behaketa bat emango genieke V eta M moduluei, eta hurrengo uneko behaketa iragarri beharko lukete. Hau da, haien helburua da aurresaten duten behaketa eta ondoren ikusten dutenaren arteko aldea minimizatzea. Eta horrela ikasten dute geroz eta iragarpen hobeak egiten. Kontu egin ikasketa horrek ez duela zerikusirik ataza jakin batekin.
Jakin-mina formulatzen
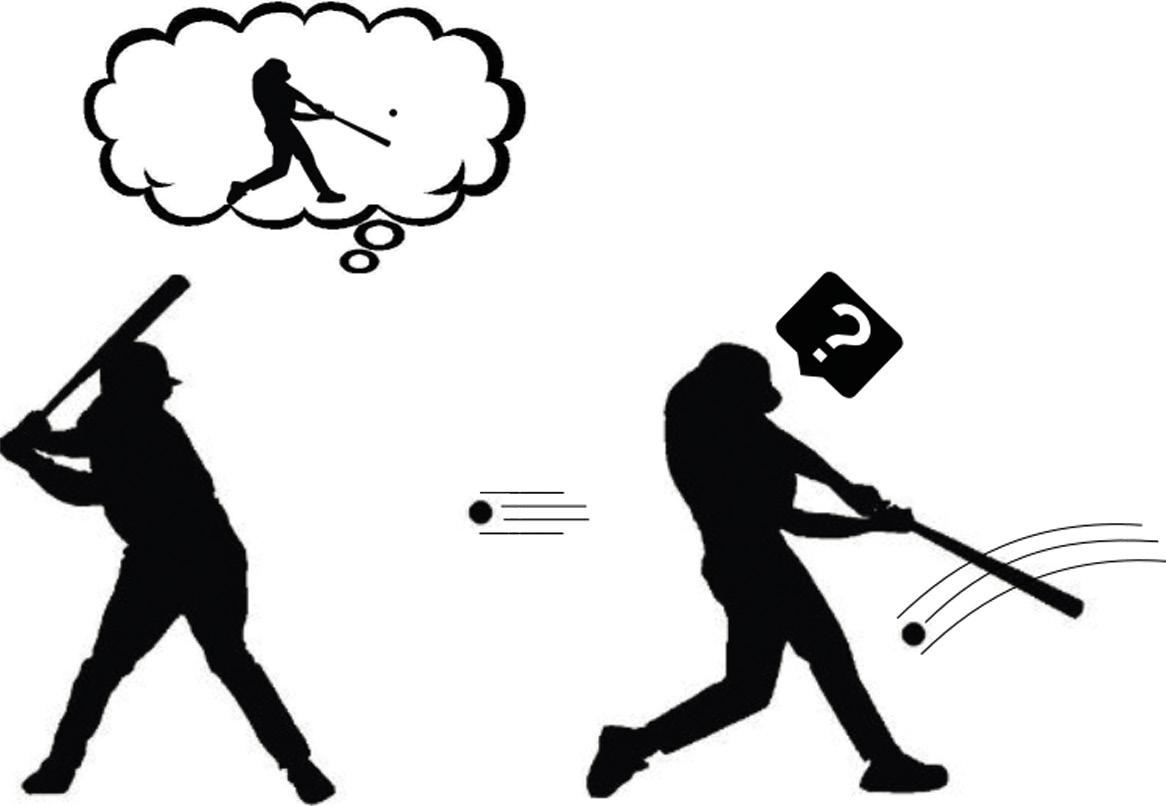
Demagun, beraz, badakigula jada nola sortu mundu-eredu bat edozein atazatarako. Laguntzen al digu jakin-mina ulertzen etorkizuna aurresateko gai den mundu-eredu horrek? Andy Clarken arabera, gure garunak etorkizuna aurresaten du, baina ezusteko handia hartzen du aurresandako etorkizun horrek ez badu zerikusirik benetan behatzen duenarekin. Ezuste horiek adierazten dute gure mundu-eredua ez dela behar bezain ona. Beraz, gure garunak arreta berezia eskaintzen die une horiei. Behaketa arraro horiek aztertzen ditu, hainbat ekintza exekutatzen ditu, eta bere ezustearen zergatia bilatu nahi izaten du (3. irudia). Ez al da, bada, hori jakin-mina? Bingo!
Era horretara esanda, badirudi ez dela hain zaila jakin-mina formulatzea: konpara dezagun mundu-ereduak sortzen duen iragarpena benetan ikusitakoarekin; antzekoak badira, egoera hori ezaguna da eta, beraz, ez dugu gehiago aztertu behar; baina oso ezberdinak badira, piz dezagun gure jakin-mina. Errefortzu bidezko ikasketaren ideiak jarraituz, jaso dezala makinak saria bere ekintzen ondorioz ongi aurresan ezin dituen egoerak topatzen dituen bakoitzean. Eta horrela, makinak bere ingurunearekin jolastuz ikasiko du, ume txikiek egiten duten antzera. Era honetara formulatzen den errefortzua berezko errefortzu ala motibazio gisa ezagutzen da.
Jakin-minak gidatutako ikasketa
OpenAI ikerketa-zentroak jakin-minaren indarra aztertu nahi izan zuen [4]. Horretarako, bideo-joko klasiko pilo bat hartu zituzten, eta haiekin entrenatu zituzten beren makinak. Etorkizuna aurresateko gai diren mundu-ereduak zituzten oinarritzat makina horiek. Eta lehen esan dugun bezala formulatzen zuten jakin-mina. Hots, iragarritakoa eta benetan behatutakoaren arteko aldeak kontuan hartuta.
Aipatutako joko horiek helburu ezberdinak dituzte, eta errefortzu-funtzioan islatzen dira helburuak. Baina errefortzu hori alde batera utzi zuten OpenAI-ko ikertzaileek, jakin-mina bakarrik erabiliz. Beraz, makinek sariak jasotzen zituzten beren ekintzek egoera berrietara eramaten zituztenean: aurresateko zailak ziren egoeretara, hain zuzen. Esan daiteke motibazio hutsez trebatutako makinak zirela.
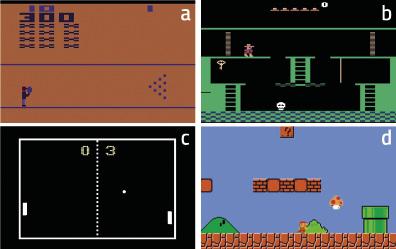
Emaitza txundigarriak lortu zituzten. Adibidez, Bowling jokoa (4.a irudia) jakin-min hutsez gainditzen ikasi zuen makinak. Ikertzaileen arabera, pantailan puntuazioa agertzea da emaitza hori azaltzeko gakoa. Birla asko botatzen baditu makinak, puntuazioa asko aldatzen da. Beraz, hasiera batean, egoera horiek dira aurresaten zailenak, hots, behaketan aldaketa handienak eragiten dituztenak. Pong-en kasuan, bestalde (4.c irudia), pilota denbora luzez jokoan mantentzen ikasten du makinak, baina ez irabazten. Hala ere, argi dago bikain ikasten duela munduaren dinamika. Super Mario Brosen kasuan ere (4.d irudia), jokoa gainditzen ikasten du jakin-min hutsez.
Harrigarriena, hala ere, Montezuma’s Revenge jokoan gertatu zen (4.b irudia). Joko hori oso konplexua da makinentzat gaur egun, esplorazio-gaitasun handiak eskatzen baititu eta errefortzuak oso gutxitan jasotzen baitira. Gaur egun hain modan dauden scape room-en antzekoa da joko hori: puzzleak osatzen joan behar da, gela ezberdinak osatu eta jokoa gainditzeko. Errefortzuak gela bakoitzetik irtetean iristen dira (irtenez gero, saria; bestela, zigorra). Orain arteko makinek ezin izan dute gizakion puntuazioetara hurbildu, ez baitzuten errefortzurik jasotzen gela bakoitzeko objektu ezberdinak esploratu eta puzzleak askatzen saiatzeagatik. Jakin-min hutsez trebatutako makinak, berriz, gizakion antzeko emaitzak lortu ahal izan zituen! Azken batean, objektuak eta gela bakoitzeko txoko arraroak esploratzera bultzatzen du jakin-minak makina, eta hor dago gakoa.
Bukatzeko
Gure garuna oso konplexua da. Pertzepzioa, etorkizuna aurresateko gaitasuna eta jakin-mina garunaren paisaiako elementu bakan batzuk besterik ez dira. Baina adimen artifizialaren esparruan aurrerapen garrantzitsuak eragiteko gai izan dira jada. Badirudi ideia erakargarri horien atzean hauteman daitekeela egiaren traza. Beraz, ikertzen jarraitu beharko dugu hain boteretsuak diruditen ideia horiek behar bezala ulertzeko, eta soluzio berriak bilatu ahal izateko. Epe motzeko eta luzeko memoria, ikasketa interaktiboa ala ikasketa kooperatiboa jada irekita dauden ikerketa lerroak dira [5]. Lanean jarraitu beharko, jakin-minak bultzatzen gaitu eta.
Bibliografia
Idatzi zuk zeuk Gai librean atalean
Gai librean aritzeko, bidali zure artikulua aldizkaria@elhuyar.eus helbidera
Hauek dira Gai librean atalean Idazteko arauak
Zu idazle
Zientzia aldizkaria

