

Tendance à la différenciation des genres dans l'intelligence artificielle
— Dans la figure 1, il y a deux robots intelligents, garçon ou fille? Qu'est-ce que c'est ?
— Mais de quoi parlons-nous ? Comment est-il possible que l'intelligence artificielle tente de différencier les genres ? Les machines n'ont pas de sexe, n'est-ce pas?”

Effectivement. L'intelligence des machines est l'intelligence artificielle (IA) ou la machine. Ce n'est pas nouveau, parce que de nombreuses années se sont écoulées depuis 1956, lorsque Samuel, Simmons, Newell, MacArthy et Minsky ont déclaré l'intelligence artificielle comme ligne de recherche. Depuis, la technologie a énormément progressé. Comprendre le langage naturel, jouer avec succès dans des jeux nécessitant des stratégies complexes (échecs, jeu Go), développer des systèmes autonomes de conduite et planifier de manière optimale les canaux en réseaux de distribution multipoint sont quelques-uns des progrès qui ont été possibles grâce à l'AA. Pour cela, on utilise des méthodes statistiques et des formalismes symboliques, entre autres. Et c'est que l'apprentissage automatique est celui qui soutient la révolution actuelle de l'AA. Ces études sont des méthodes qui découlent de la connaissance de bases de données épaisses et qui sont utilisées par des agences de compagnies et gouvernements, des hôpitaux et d'autres entreprises [2] pour des applications diverses. Par exemple, identifier des objets dans des séquences vidéo, évaluer la crédibilité des demandes de prêt, rechercher des erreurs dans les contrats légaux ou trouver le traitement le plus approprié pour une personne cancéreuse [1] [2].
AA est déjà à nos jours, beaucoup des applications que nous utilisons sur nos mobiles sont basées sur des techniques d'intelligence artificielle (solutions) et nous les utilisons normalement. Par exemple, il est de plus en plus fréquent d'utiliser la communication orale pour communiquer avec les téléphones et les ordinateurs: Amazon offre Alex, Google Home, Apple offre Siri et Microsoft Cortana. Ce sont les serveurs vocaux, les outils qui nous permettent de connaître, traiter et répondre à la question ou demande faite, une fois la recherche sur Internet effectuée, par la synthèse vocale.
Nous sommes conscients que, en raison des tendances des années, la société elle-même n'est pas neutre et que les tendances dans la différenciation des genres (et autres) sont souvent brevets. Par exemple, le rôle des soins est attaché aux femmes et aux rôles liés à la force aux hommes. Mais qu'en est-il de l'intelligence artificielle? Si l'intelligence artificielle et l'apprentissage automatique évoluent, vous risquez d'intégrer ces tendances dans les outils du futur. Et c'est que cela se passe déjà.
Données source de problèmes
Les algorithmes d'apprentissage automatique effectuent des prédictions comme appris. Les algorithmes eux-mêmes n'ont aucune tendance, ni de genre, ni de race, ni d'autre nature. Mais comme mentionné, ils sont basés sur les données, les mathématiques et les statistiques. La tendance est dans les données, qui sont le reflet de la société et qui sont le fruit de nos décisions. Dans les critères que nous utilisons les personnes pour recruter des candidats, dans l'évaluation des rapports des élèves, dans la réalisation de diagnostics médicaux, dans la description des objets, dans tous nous avons des tendances de différenciation entre culture, race, éducation et autres [5], et parmi eux, bien sûr, la différenciation des genres. En bref, les modèles créés seront aussi bons ou neutres que les données utilisées pour la formation au mieux. Nous recueillons et étiquetons les données, reflètent notre subjectivité dans les données, ce qui provoque des tendances dans les systèmes développés par l'apprentissage automatique. De plus, l'intelligence artificielle amplifie les stéréotypes ! [2]. En fait, lorsque nous sélectionnons le modèle le plus approprié à partir d'algorithmes d'apprentissage automatique, nous choisissons celui qui convient le mieux aux données ou celui qui a le plus grand taux d'invention, laissant de côté d'autres critères.
Le problème est grave, surtout dans les cas où il est utilisé pour la prise de décision comme proposé par les machines, ce qui arrive souvent dans la vie quotidienne, puisque les outils basés sur l'intelligence artificielle sont très répandus [4].
Quelques exemples de tendance à la différenciation des genres
Si nous reculons une quinzaine d'années, lorsque les premiers développements pour connaître la parole ont été mis en place dans les voitures, les systèmes ne comprenaient pas les voix féminines, car ils ont été formés avec celles des hommes. Même si ces dernières années, on a énormément progressé dans ce type de système, et qu'on connaît les voix des femmes et des hommes, la tendance du genre reste évidente. Au fil des serveurs vocaux que nous venons de mentionner, trois sur quatre ont un nom de femme et, plus encore, tous ont une voix de femme par défaut. Bien qu'aujourd'hui on puisse changer, par défaut les obéisseurs qui font des serviteurs sont féminins.
Pourquoi ? La raison est simple parce que nous attendons des femmes dans les tâches administratives et dans les soins ou les services. Faire un sondage ne serait pas surprenant que la plupart priorisent la voix féminine.
La tendance à la différenciation des genres apparaît non seulement dans des contextes liés à la voix. Dans le traitement du langage naturel, par exemple, pour effectuer des analyses sémantiques de textes, on utilise des dictionnaires grossiers, appelés word embedding, qui sont extraits de grands ensembles de textes et qui relient les mots entre eux. Une étude menée par des chercheurs de l’université de Boston [2] a montré qu’avec ces dictionnaires on peut produire des inférences du type «John écrit de meilleurs programmes que Mary». Logiquement, cela est la conséquence des textes utilisés pour les créer.
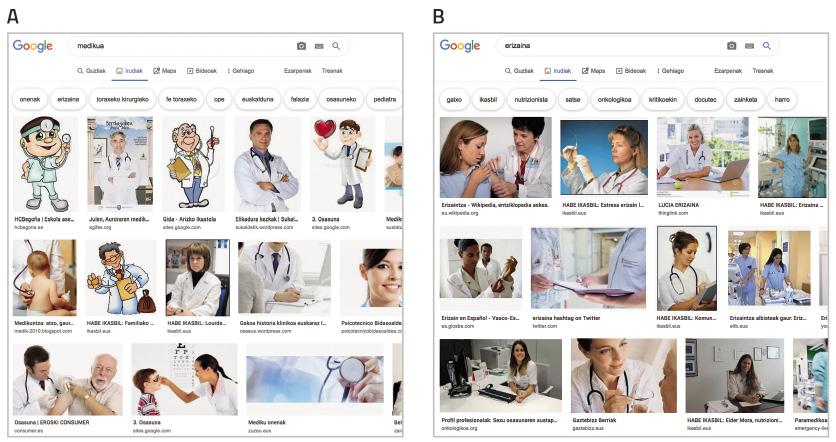
Dans une société dominée par l'image, les systèmes qui apprennent artificiellement se nourrissent de plus en plus de l'image. Les ensembles de données bien connus ImSitu (http://imsitu.org/) et COCO (http://cocodataset.org/) contiennent plus de 100.000 images provenant du réseau, étiquetées avec des explications de scènes complexes [3]. Dans l'un comme dans l'autre cas, ce sont plus les figures masculines, et on constate que les étiquettes d'objets et d'actions tendent à différencier les genres. Dans l'ensemble de données COCO, les ustensiles de cuisine (cuillères et fourchettes) sont décrits en relation avec les femmes, tandis que l'équipement pour les sports en plein air (planches de neige et raquettes de tennis) est associé aux hommes. Il en va de même pour la base de données ImageNet, créée entre 2002 et 2004 avec les images de Yahoo News et encore très utilisée. 78% des images sont représentées par des hommes et 84% d'entre elles avec écorce blanche, puisque George W. Bush est la personne qui apparaît le plus. Comme ces ensembles de données sont utilisés pour former un logiciel de reconnaissance d'image, le logiciel héritera de la tendance. Essayez, cherchez le “médecin” dans les images de Google et l'écran est rempli d'hommes vêtus de tabliers blancs. Au contraire, si vous cherchez une « infirmière », les femmes vous remarqueront (voir figure 2).
Voies pour éliminer la tendance
Pour que les propositions de systèmes d'intelligence artificielle soient fiables, nous devrions d'abord nous assurer que les propositions sont objectives. Les algorithmes n'ont pas conscience et ne peuvent donc pas changer leurs propositions.
La façon de l'affronter n'est pas la seule ; elle peut et doit être abordée sur de nombreux fronts.
D'une part, la participation active des femmes à toutes les étapes du développement technologique sera indispensable. Selon les statistiques, les femmes sont de plus en plus éloignées de 50% dans les postes de technologie informatique. Même si le changement va aider, cela ne garantit pas que les tendances de différenciation de genre disparaissent dans les systèmes à créer. Par exemple, AVA (Autodesk Virtual Agent), un agent logiciel qui fournit le service clientèle de produits Autodesk dans le monde entier. Il combine intelligence artificielle avec intelligence émotionnelle pour parler « face à face » avec le client. Bien qu'AVA ait été créée par une équipe de travail majoritairement féminine, elle a une voix et une apparence féminine. L'excuse est encore la même : les gens ressentent les voix féminines les plus amicales et collaboratives. Cet exemple montre donc qu'il ne suffit pas aux femmes d'adhérer aux groupes de travail.
Une façon d'éliminer les tendances des systèmes d'apprentissage automatique consiste à déboguer et à corriger les bases de données utilisées pour l'entraînement. Il y a des chercheurs qui s'y consacrent et qui ont éliminé des textes des relations qui ne sont pas légitimes, par exemple, hommes/ordinateurs et femmes/appareils [6]. D'autres chercheurs, en revanche, proposent de créer des classeurs différenciés pour classer chacun des groupes représentés dans un ensemble de données [7].
Il est donc clair que nous devons tous garder à l'esprit que si les données ont une tendance particulière, la tendance sera la même pour les systèmes qui apprennent d'eux sans effort, ce qui peut avoir des conséquences graves pour nous. Nous aurons besoin d'outils pour détecter et identifier les tendances et les principes pour la création de nouveaux ensembles de données. Il peut être nécessaire d'avoir des experts pour cela. Et pourquoi ne pas développer des outils d'intelligence artificielle pour cette tâche!
Références
Zu idazle
Zientzia aldizkaria

