

Tendència a la diferenciació de gèneres en la intel·ligència artificial
— En la figura 1 hi ha dos robots intel·ligents, noi o noia? Quin és?
— Però, de què parlem? Com és possible que la intel·ligència artificial botiga a diferenciar els gèneres? Les màquines no tenen gènere, no és així?”

Efectivament. La intel·ligència de les màquines és la intel·ligència artificial (IA) o la màquina. No és nou, perquè han passat molts anys des de 1956, quan Samuel, Simmons, Newell, MacArthy i Minsky van declarar la intel·ligència artificial com a línia de recerca. Des de llavors, la tecnologia s'ha avançat enormement. Comprendre el llenguatge natural, jugar amb èxit en jocs que requereixen estratègies complexes (escacs, joc Go), desenvolupar sistemes autònoms de conducció i planificar de manera òptima els canals en xarxes de distribució multipunto són alguns dels avanços que han estat possibles gràcies a l'AA. Per a això s'utilitzen mètodes estadístics i formalismes simbòlics, entre altres. I és que l'aprenentatge automàtic és el que sustenta l'actual revolució de l'AA. Aquests estudis són mètodes que deriven del coneixement de bases de dades gruixudes i que són utilitzats per agències de companyies i governs, hospitals i altres empreses [2] per a aplicacions diverses. Per exemple, identificar objectes en seqüències de vídeo, valorar la credibilitat de les sol·licituds de préstec, buscar errors en els contractes legals o trobar el tractament més adequat per a una persona amb càncer [1] [2].
AA ja està en el nostre dia a dia, moltes de les aplicacions que portem en els nostres mòbils estan basades en tècniques d'intel·ligència artificial (solucions) i les usem amb normalitat. Per exemple, és cada vegada més freqüent utilitzar la comunicació oral per a comunicar-se amb telèfons i ordinadors: Amazon ofereix Alex, Google Home, Apple ofereix Siri i Microsoft Cortana. Aquests són els servidors de veu, les eines que ens permeten conèixer, processar i respondre a la pregunta o sol·licitud realitzada, una vegada realitzada la cerca en Internet, mitjançant la síntesi de veu.
Som conscients que, a causa de les tendències dels anys, la pròpia societat no és neutra i que les tendències en la diferenciació de gèneres (i uns altres) són sovint patents. Per exemple, el rol de la cura s'adscriu a les dones i els rols relacionats amb la força als homes. Però què passa amb la intel·ligència artificial? Si la intel·ligència artificial i l'aprenentatge automàtic evolucionen, es corre el risc d'integrar aquestes tendències en les eines del futur. I és que ja està succeint.
Dades font de problemes
Els algorismes d'aprenentatge automàtic realitzen prediccions segons l'après. Els propis algorismes no tenen tendència ni de gènere, ni de raça, ni d'un altre tipus. Però com s'ha esmentat, es basen en dades, matemàtiques i estadística. La tendència està en les dades, que són reflex de la societat i que són fruit de les nostres decisions. En els criteris que utilitzem les persones per a la contractació de candidats, en l'avaluació dels informes dels alumnes, en la realització de diagnòstics mèdics, en la descripció dels objectes, en tots ells tenim tendències de diferenciació entre cultura, raça, educació i uns altres [5], i entre ells, per descomptat, la diferenciació de gèneres. En definitiva, els models creats seran tan bons o neutres com les dades utilitzades per a l'entrenament en el millor dels casos. Nosaltres recollim i etiquetem les dades, reflectim la nostra subjectivitat en les dades, la qual cosa provoca tendències en els sistemes desenvolupats mitjançant l'aprenentatge automàtic. És més, la intel·ligència artificial amplifica els estereotips! [2]. De fet, quan seleccionem el model més adequat a partir d'algorismes d'aprenentatge automàtic, triem el que millor s'adapta a les dades o el que té major taxa d'invenció, deixant de costat altres criteris.
El problema és greu, sobretot en aquells casos en els quals s'utilitza per a la presa de decisions el proposat per les màquines, alguna cosa que ocorre amb freqüència en la vida quotidiana, ja que les eines basades en la intel·ligència artificial estan molt esteses [4].
Alguns exemples de tendència a la diferenciació de gèneres
Si retrocedim uns quinze anys, quan els primers desenvolupaments per a conèixer la parla es van implantar en els cotxes, els sistemes no entenien les veus femenines, ja que es van entrenar amb les dels homes. A pesar que en els últims anys s'han avançat enormement en aquesta mena de sistemes, i que coneixen les veus de dones i homes, la tendència del gènere continua sent evident. Al fil dels servidors de veu que acabem d'esmentar, tres de cada quatre tenen nom de dona i, més encara, tots tenen veu de dona per defecte. Encara que avui dia es pot canviar, per defecte els obedecedores que fan de servidors són femenins.
Per què? La raó és senzilla perquè esperem dones en tasques administratives i en cures o serveis. Fer una enquesta no seria d'estranyar que la majoria prioritzés la veu femenina.
La tendència a la diferenciació de gèneres no sols apareix en contextos relacionats amb la veu. En el processament del llenguatge natural, per exemple, per a realitzar anàlisis semàntiques de textos, s'utilitzen diccionaris gruixuts, denominats word-embedding, que s'extreuen de grans conjunts de textos i que relacionen les paraules entre si. Un estudi realitzat per investigadors de la universitat de Boston [2] ha posat de manifest que amb aquests diccionaris es poden produir inferències del tipus “John escriu millors programes que Mary”. Lògicament, això és conseqüència dels textos utilitzats per a crear-los.
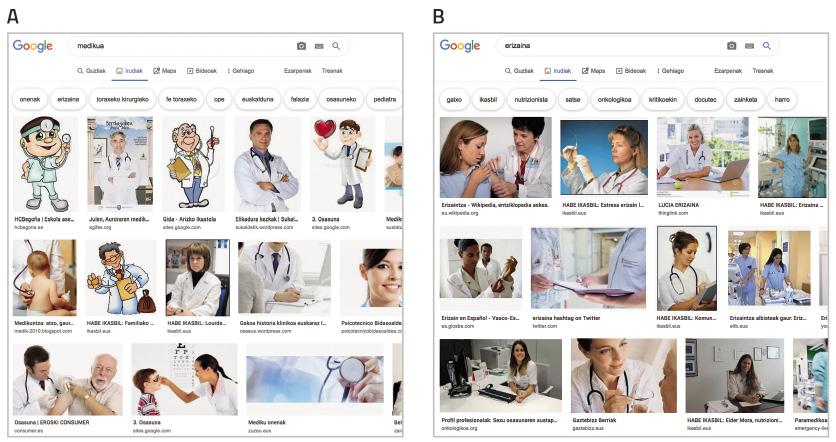
En una societat dominada per la imatge, els sistemes que aprenen artificialment s'alimenten cada vegada més de la imatge. Els coneguts conjunts de dades ImSitu (http://imsitu.org/) i COCO (http://cocodataset.org/) contenen més de 100.000 imatges procedents de la xarxa, etiquetades amb explicacions d'escenes complexes [3]. Tant en un com en un altre cas, són més les figures masculines, i es constata que les etiquetes d'objectes i accions tendeixen a diferenciar els gèneres. En el conjunt de dades COCO, els utensilis de cuina (culleres i forquilles) es descriuen relacionats amb les dones, mentre que l'equipament per a esports a l'aire lliure (taules de neu i raquetes de tennis) s'associen als homes. El mateix ocorre en la base de dades ImageNet, creada entre 2002 i 2004 amb les imatges de Yahoo News, i encara molt utilitzada. El 78% de les imatges estan representades per homes i el 84% d'elles amb escorça blanca, ja que George W. Bush és la persona que més apareix. Com aquests conjunts de dades s'utilitzen per a entrenar programari de reconeixement d'imatges, el programari heretarà la tendència. Prova, cerca el “metge” en les imatges de Google i la pantalla s'omple d'homes vestits amb davantals blancs. Per contra, si busques “infermera”, et destacaran les dones (veure figura 2).
Vies per a eliminar la tendència
Perquè les propostes de sistemes d'intel·ligència artificial siguin fiables, deuríem primer assegurar que les propostes són objectives. Els algorismes no tenen consciència i per tant no poden canviar les seves propostes.
La manera d'afrontar-ho no és l'única; pot i ha d'abordar-se des de molts fronts.
D'una banda, serà imprescindible la participació activa de les dones en tots els passos del desenvolupament tecnològic. Segons les estadístiques, les dones estan cada vegada més allunyades del 50% en llocs de tecnologia informàtica. A pesar que el canvi ajudarà, això no garanteix que en els sistemes que es vagin a crear desapareguin les tendències de diferenciació de gènere. Exemple d'això és AVA (Autodesk Virtual Agent), agent programari que ofereix el servei d'atenció al client de productes Autodesk a tot el món. Combina intel·ligència artificial amb intel·ligència emocional per a parlar “cara a cara” amb el client. Encara que AVA ha estat creada per un equip de treball majoritàriament femení, té veu i aparença femenina. L'excusa és una altra vegada la mateixa: les persones sentim les veus femenines més amigables i col·laboratives. Aquest exemple posa de manifest, per tant, que no n'hi ha prou que les dones s'incorporin als grups de treball.
Una manera d'eliminar les tendències dels sistemes d'aprenentatge automàtic és mitjançant una exhaustiva depuració i correcció de les bases de dades utilitzades per a l'entrenament. Hi ha investigadors que es dediquen a això i que han eliminat dels textos relacionis que no són legítimes, per exemple, homes/ordenadors i dones/electrodomèstics [6]. Altres investigadors, en canvi, proposen crear classificadors diferenciats per a classificar cadascun dels grups representats en un conjunt de dades [7].
És clar, per tant, que tots hem de tenir en compte que si les dades tenen una tendència determinada, la tendència serà la mateixa per als sistemes que aprenen d'ells sense esforç, la qual cosa pot tenir conseqüències greus per a nosaltres. Necessitarem eines per a detectar i identificar tendències i principis per a la creació de nous conjunts de dades. És possible que sigui necessari comptar amb experts per a això. I per què no desenvolupar eines d'intel·ligència artificial per a aquesta tasca!
Referències
Zu idazle
Zientzia aldizkaria

