

Tendencia a la diferenciación de géneros en la inteligencia artificial
— En la figura 1 hay dos robots inteligentes, ¿chico o chica? ¿Cuál es?
— Pero, ¿de qué hablamos? ¿Cómo es posible que la inteligencia artificial tienda a diferenciar los géneros? Las máquinas no tienen género, ¿no es así?”

Efectivamente. La inteligencia de las máquinas es la inteligencia artificial (IA) o la máquina. No es nuevo, porque han pasado muchos años desde 1956, cuando Samuel, Simmons, Newell, MacArthy y Minsky declararon la inteligencia artificial como línea de investigación. Desde entonces, la tecnología se ha avanzado enormemente. Comprender el lenguaje natural, jugar con éxito en juegos que requieren estrategias complejas (ajedrez, juego Go), desarrollar sistemas autónomos de conducción y planificar de forma óptima los canales en redes de distribución multipunto son algunos de los avances que han sido posibles gracias a la AA. Para ello se utilizan métodos estadísticos y formalismos simbólicos, entre otros. Y es que el aprendizaje automático es el que sustenta la actual revolución de la AA. Estos estudios son métodos que derivan del conocimiento de bases de datos gruesas y que son utilizados por agencias de compañías y gobiernos, hospitales y otras empresas [2] para aplicaciones diversas. Por ejemplo, identificar objetos en secuencias de vídeo, valorar la credibilidad de las solicitudes de préstamo, buscar errores en los contratos legales o encontrar el tratamiento más adecuado para una persona con cáncer [1] [2].
AA ya está en nuestro día a día, muchas de las aplicaciones que llevamos en nuestros móviles están basadas en técnicas de inteligencia artificial (soluciones) y las usamos con normalidad. Por ejemplo, es cada vez más frecuente utilizar la comunicación oral para comunicarse con teléfonos y ordenadores: Amazon ofrece Alex, Google Home, Apple ofrece Siri y Microsoft Cortana. Estos son los servidores de voz, las herramientas que nos permiten conocer, procesar y responder a la pregunta o solicitud realizada, una vez realizada la búsqueda en Internet, mediante la síntesis de voz.
Somos conscientes de que, debido a las tendencias de los años, la propia sociedad no es neutra y que las tendencias en la diferenciación de géneros (y otros) son a menudo patentes. Por ejemplo, el rol del cuidado se adscribe a las mujeres y los roles relacionados con la fuerza a los hombres. ¿Pero qué pasa con la inteligencia artificial? Si la inteligencia artificial y el aprendizaje automático evolucionan, se corre el riesgo de integrar estas tendencias en las herramientas del futuro. Y es que ya está sucediendo.
Datos fuente de problemas
Los algoritmos de aprendizaje automático realizan predicciones según lo aprendido. Los propios algoritmos no tienen tendencia ni de género, ni de raza, ni de otro tipo. Pero como se ha mencionado, se basan en datos, matemáticas y estadística. La tendencia está en los datos, que son reflejo de la sociedad y que son fruto de nuestras decisiones. En los criterios que utilizamos las personas para la contratación de candidatos, en la evaluación de los informes de los alumnos, en la realización de diagnósticos médicos, en la descripción de los objetos, en todos ellos tenemos tendencias de diferenciación entre cultura, raza, educación y otros [5], y entre ellos, por supuesto, la diferenciación de géneros. En definitiva, los modelos creados serán tan buenos o neutros como los datos utilizados para el entrenamiento en el mejor de los casos. Nosotros recogemos y etiquetamos los datos, reflejamos nuestra subjetividad en los datos, lo que provoca tendencias en los sistemas desarrollados mediante el aprendizaje automático. ¡Es más, la inteligencia artificial amplifica los estereotipos! [2]. De hecho, cuando seleccionamos el modelo más adecuado a partir de algoritmos de aprendizaje automático, elegimos el que mejor se adapta a los datos o el que tiene mayor tasa de invención, dejando de lado otros criterios.
El problema es grave, sobre todo en aquellos casos en los que se utiliza para la toma de decisiones lo propuesto por las máquinas, algo que ocurre con frecuencia en la vida cotidiana, ya que las herramientas basadas en la inteligencia artificial están muy extendidas [4].
Algunos ejemplos de tendencia a la diferenciación de géneros
Si retrocedemos unos quince años, cuando los primeros desarrollos para conocer el habla se implantaron en los coches, los sistemas no entendían las voces femeninas, ya que se entrenaron con las de los hombres. A pesar de que en los últimos años se han avanzado enormemente en este tipo de sistemas, y que conocen las voces de mujeres y hombres, la tendencia del género sigue siendo evidente. Al hilo de los servidores de voz que acabamos de mencionar, tres de cada cuatro tienen nombre de mujer y, más aún, todos tienen voz de mujer por defecto. Aunque hoy en día se puede cambiar, por defecto los obedecedores que hacen de servidores son femeninos.
¿Por qué? La razón es sencilla porque esperamos mujeres en tareas administrativas y en cuidados o servicios. Hacer una encuesta no sería de extrañar que la mayoría priorizara la voz femenina.
La tendencia a la diferenciación de géneros no sólo aparece en contextos relacionados con la voz. En el procesamiento del lenguaje natural, por ejemplo, para realizar análisis semánticos de textos, se utilizan diccionarios gruesos, denominados word-embedding, que se extraen de grandes conjuntos de textos y que relacionan las palabras entre sí. Un estudio realizado por investigadores de la universidad de Boston [2] ha puesto de manifiesto que con estos diccionarios se pueden producir inferencias del tipo “John escribe mejores programas que Mary”. Lógicamente, esto es consecuencia de los textos utilizados para crearlos.
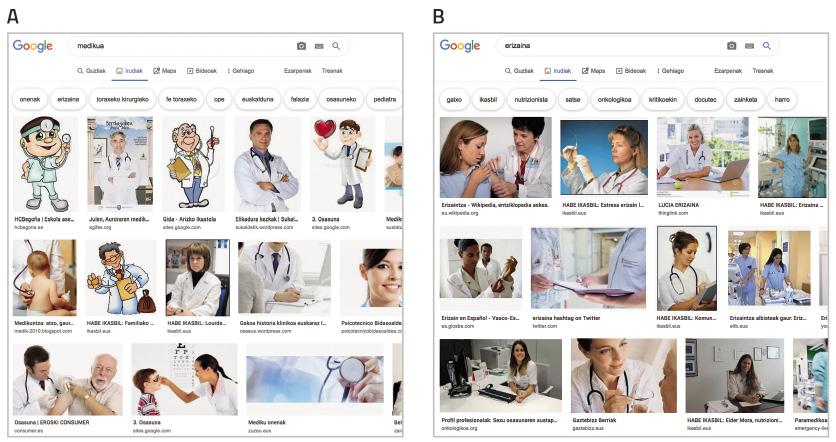
En una sociedad dominada por la imagen, los sistemas que aprenden artificialmente se alimentan cada vez más de la imagen. Los conocidos conjuntos de datos ImSitu (http://imsitu.org/) y COCO (http://cocodataset.org/) contienen más de 100.000 imágenes procedentes de la red, etiquetadas con explicaciones de escenas complejas [3]. Tanto en uno como en otro caso, son más las figuras masculinas, y se constata que las etiquetas de objetos y acciones tienden a diferenciar los géneros. En el conjunto de datos COCO, los utensilios de cocina (cucharas y tenedores) se describen relacionados con las mujeres, mientras que el equipamiento para deportes al aire libre (tablas de nieve y raquetas de tenis) se asocian a los hombres. Lo mismo ocurre en la base de datos ImageNet, creada entre 2002 y 2004 con las imágenes de Yahoo News, y todavía muy utilizada. El 78% de las imágenes están representadas por hombres y el 84% de ellas con corteza blanca, ya que George W. Bush es la persona que más aparece. Como estos conjuntos de datos se utilizan para entrenar software de reconocimiento de imágenes, el software heredará la tendencia. Prueba, busca el “médico” en las imágenes de Google y la pantalla se llena de hombres vestidos con delantales blancos. Por el contrario, si buscas “enfermera”, te destacarán las mujeres (ver figura 2).
Vías para eliminar la tendencia
Para que las propuestas de sistemas de inteligencia artificial sean fiables, deberíamos primero asegurar que las propuestas son objetivas. Los algoritmos no tienen conciencia y por tanto no pueden cambiar sus propuestas.
La forma de afrontarlo no es la única; puede y debe abordarse desde muchos frentes.
Por un lado, será imprescindible la participación activa de las mujeres en todos los pasos del desarrollo tecnológico. Según las estadísticas, las mujeres están cada vez más alejadas del 50% en puestos de tecnología informática. A pesar de que el cambio va a ayudar, esto no garantiza que en los sistemas que se vayan a crear desaparezcan las tendencias de diferenciación de género. Ejemplo de ello es AVA (Autodesk Virtual Agent), agente software que ofrece el servicio de atención al cliente de productos Autodesk en todo el mundo. Combina inteligencia artificial con inteligencia emocional para hablar “cara a cara” con el cliente. Aunque AVA ha sido creada por un equipo de trabajo mayoritariamente femenino, tiene voz y apariencia femenina. La excusa es otra vez la misma: las personas sentimos las voces femeninas más amigables y colaborativas. Este ejemplo pone de manifiesto, por tanto, que no basta con que las mujeres se incorporen a los grupos de trabajo.
Una forma de eliminar las tendencias de los sistemas de aprendizaje automático es mediante una exhaustiva depuración y corrección de las bases de datos utilizadas para el entrenamiento. Hay investigadores que se dedican a ello y que han eliminado de los textos relaciones que no son legítimas, por ejemplo, hombres/ordenadores y mujeres/electrodomésticos [6]. Otros investigadores, en cambio, proponen crear clasificadores diferenciados para clasificar cada uno de los grupos representados en un conjunto de datos [7].
Está claro, por tanto, que todos tenemos que tener en cuenta que si los datos tienen una tendencia determinada, la tendencia será la misma para los sistemas que aprenden de ellos sin esfuerzo, lo que puede tener consecuencias graves para nosotros. Necesitaremos herramientas para detectar e identificar tendencias y principios para la creación de nuevos conjuntos de datos. Es posible que sea necesario contar con expertos para ello. ¡Y por qué no desarrollar herramientas de inteligencia artificial para esa tarea!
Referencias
Zu idazle
Zientzia aldizkaria

