

Pequenos cerebros virtuais
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea

Grandes proxectos en marcha
As maiores potencias do mundo xa comezaron o estudo do cerebro con grandes proxectos. Por unha banda, cabe destacar dous proxectos que reciben fondos públicos: BRAIN Initiative de EEUU e Human Brain Project de Europa. Ambos os proxectos teñen diferentes perspectivas: os americanos buscan obter un mapa do cerebro concreto, analizando ben o funcionamento de cada neurona; os europeos, pola súa banda, teñen una visión máis informática, que ten como obxectivo conseguir un modelo computacional concreto do noso cerebro, paira desenvolver cerebros virtuais.
Tamén hai diñeiro privado. Con obxectivos moito máis prácticos, Google, Microsoft, Baidu (Google China), Facebook e outras grandes empresas crearon os seus propios proxectos de investigación. Dada a natureza destas empresas, detéctase de inmediato que a visión é moi “informática”: baséase no cerebro humano paira imitar artificialmente a nosa intelixencia e ofrecer así servizos moito máis intelixentes.

Este artigo pretende dar a coñecer o concepto innovador que está no centro dos proxectos destas grandes empresas: o deep learning (aprendizaxe profunda). Este concepto leva a outro nivel as redes neuronais artificiais que se inventaron nos anos 60 e 70 do século pasado. En 2006 o investigador Geoffrey Hinton publicou as bases do deep learning. Hinton traballa actualmente en Google.
Redes neuronais artificiais
A primeira parada desta viaxe é en redes neuronais artificiais. Do mesmo xeito que o cerebro humano, estas redes artificiais están baseadas en neuronas. Cada neurona ten unhas entradas e una saída. Tanto as entradas como as saídas son só números. Por tanto, o traballo dunha neurona consiste en tomar as entradas e calcular una saída utilizando paira iso unhas sinxelas funcións matemáticas. As neuronas organízanse en redes formando capas. Normalmente existe una capa de entrada. Si fixésemos una comparación co noso cerebro, a capa de entrada utilizaríase paira recoller información sensible. A continuación colócanse capas ocultas e finalmente capa de saída (por exemplo, neuronas que envían sinais aos nosos músculos). Na figura 1 pódese ver una estrutura sinxela da mesma.
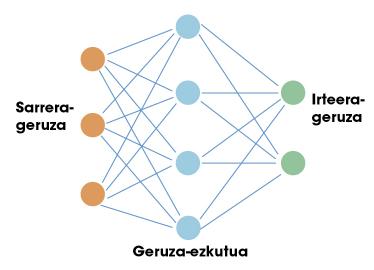
Éxito de redes neuronais no ámbito da intelixencia artificial. A clave está no teorema da aproximación universal. Algúns matemáticos demostraron que una rede neuronal cunha soa capa oculta pode aproximarse a calquera función non lineal. Noutras palabras, una rede neuronal pode aprender calquera relación posible entre os números de entrada e saída. No caso dun ser humano, pode aprender calquera reacción relacionada coa información que reciben os sentidos. Aí está precisamente o potencial destas redes.
É suficiente una soa capa?
Teoricamente pódese aprender calquera relación cunha capa oculta, pero na práctica as redes tan sinxelas non son moi útiles paira tarefas complexas. Por exemplo, supoñamos que queremos distinguir as caras dunha chea de imaxes. A entrada á rede sería una imaxe e a saída una cara ou non nesa imaxe. Debido á complexidade da información de entrada (en definitiva, una imaxe é unha chea de números), as redes dunha capa non alcanzan resultados moi satisfactorios. Os investigadores teñen que traballar moito nas imaxes, realizando algúns procesamientos e calculando algunhas características xeométricas, paira proporcionar á rede una menor e máis significativa información (Figura 2). Así, as redes neuronais separan ben as caras.
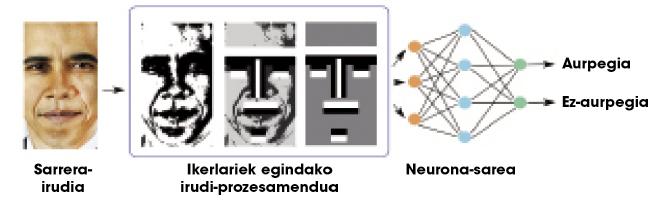
O noso cerebro realiza todos os cálculos correspondentes a calquera tarefa na propia rede neuronal, é dicir, non hai investigadores externos que realicen o procesamiento da figura 2. Paira iso, o noso cerebro organízase nunha chea de capas neuronais. Por iso, algúns investigadores pensaron que en lugar de usar una soa capa oculta, quizais habería que utilizar moitas capas paira facer fronte a tarefas complexas. As redes neuronais con moitas capas denomínanse “redes profundas”.
Problemas de adestramento en redes profundas
Para que una rede neuronal funcione correctamente é necesario adestrar. No caso da figura 2 que acabamos de ver, antes de solicitar á rede a separación de caras, hai que mostrar unha chea de imaxes indicando cales son as caras e cales non. Desta maneira, a rede aprende os parámetros de cada una das súas neuronas paira realizar correctamente esta tarefa concreta, é dicir, a función non lineal que diciamos inicialmente concrétase na fase de adestramento paira relacionar os datos de entrada coas saídas.

Aplicando técnicas de adestramento en redes monocapa en redes profundas, os resultados eran moi malos: as redes profundas non aprendían nada. Pronto se deron conta de que había grandes carencias nas técnicas de adestramento. Non podían entender como entraba una rede profunda. Por iso, até o ano 2006 as redes de máis de dúas capas ocultas nin sequera utilizábanse, xa que non podían adestrarse.
Que pasou no ano 2006? Geoffrey Hinton creou xunto ao seu equipo una revolucionaria técnica paira adestrar redes profundas. Era unha aprendizaxe profunda, deep learning, recentemente nado.
Google Brain sorprendente

Uno dos exemplos máis sorprendentes do uso do deep learning é Google Brain. Como se pode apreciar na figura 4, utiliza 1000 computadores paira manter en funcionamento una rede profunda. Nun artigo publicado en 2013, un grupo de investigadores de Google deu a coñecer un gran paso adiante. Aproveitando a capacidade de Google Brain, adestraron durante tres días una rede profunda con resultados tan sorprendentes como curiosos.
Como dixemos antes, paira aprender a diferenciar una cara hai que pasar una fase de adestramento na que se dá unha chea de imaxes á rede e dicir en que imaxe aparecen as caras e en que imaxe non. Este proceso denomínase “aprendizaxe supervisada”. Segundo algúns neurocientíficos, os seres humanos non aprendemos así a diferenciar as caras, senón que, como vemos moitas veces as caras, o noso cerebro aprende un modelo de rostro, sen que ninguén diga que ese modelo é una cara. É dicir, a aprendizaxe non é supervisado.
Os investigadores de Google sumáronse a estas teorías e preguntaron: “É posible que una rede profunda aprenda de forma non supervisada que é una cara?” Paira responder á pregunta, crearon una rede profunda baseada na estrutura do cerebro humano. A rede conta con mil millóns de parámetros paira adestrar. A pesar de que é terrible, a cortiza visual dun ser humano só ten 100 veces máis neuronas e sinapsis! Na figura 5 pódese ver una representación da rede.
Os investigadores xustificaron que nos vídeos que están en Youtube aparecen unha chea de caras humanas. Por tanto, se seleccionamos aleatoriamente unha chea de vídeos e utilizamos as imaxes paira adestrar a rede, a rede debería aprender o modelo dunha cara. Dicir e facer. Tras tres días de adestramento, mostraron á rede imaxes con caras. En porcentaxes moi altas (81,7%), a rede respondía fronte a estas imaxes co mesmo patrón de activación. Nas imaxes nas que non aparecían caras, non mostraba ningunha activación deste tipo. Quería dicir que a rede sabía que era una cara.
Mediante técnicas avanzadas de representación, os patróns de activación poden converterse en espectaculares características xeométricas. Os investigadores utilizaron estas técnicas paira representar o modelo da cara que a rede tiña “gardada”. Na figura 6 pódese ver un resultado de terrible aparencia.
Como sabedes, en Youtube aparecen en moitas ocasiones gatos ademais de humanos. É lóxico pensar, por tanto, que a rede tamén estudaría o que é un gato. Paira resolver a dúbida, os investigadores recolleron imaxes de gatos e pasáronas á rede. E si, a rede mostraba patróns de activación similares aos das caras. Aquí tedes o modelo de gato que aprendeu a rede (figura 7).

Por que funcionan tan ben as redes profundas? Parece que a razón é a súa estrutura xerárquica. As neuronas teñen a capacidade de gardar modelos abstractos da información da capa inferior por capa, desde as diferenzas de cor entre os píxeles dunha imaxe (primeira capa) até as características xeométricas (últimas capas). Ademais, todas estas características e modelos poden aprender ao seu caso segundo os datos que se lles faciliten.
E agora que?
Este traballo que acabamos de expor foi publicado en 2013, “onte”. O Deep Learning sigue sendo un campo moi “novo” e, por tanto, ten un gran futuro. Por exemplo, hai una coñecida base de datos cunha chea de imaxes, ImageNet, na que se organizan concursos de separación de obxectos en imaxes. Google foi o último vencedor. Esta base de datos calculou experimentalmente que os seres humanos temos una taxa de erro do 5,1%. A empresa chinesa Baidu publicou recentemente una taxa de erro do 5,98% co deep learning, aínda que aínda non se demostrou oficialmente.

O deep learning está a obter moi bos resultados na comprensión de linguaxes naturais e nas tarefas visuais, dúas das capacidades máis importantes que temos os seres humanos. Realizáronse traballos baseados nas neurociencias, aínda que os modelos que se utilizan aínda non son moi precisos. Seguramente as achegas dos proxectos Human Brain Project e BRAIN Initiative ensinarannos novos camiños. Nalgún momento, os avances en neurociencia e en intelixencia artificial atoparanse creando cerebros virtuais máis poderosos. Quen sabe...
Bibliografía

Zu idazle
Zientzia aldizkaria

