

Pequeños cerebros virtuales
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea

Grandes proyectos en marcha
Las mayores potencias del mundo ya han comenzado el estudio del cerebro con grandes proyectos. Por un lado, cabe destacar dos proyectos que reciben fondos públicos: BRAIN Initiative de EEUU y Human Brain Project de Europa. Ambos proyectos tienen diferentes perspectivas: los americanos buscan obtener un mapa del cerebro concreto, analizando bien el funcionamiento de cada neurona; los europeos, por su parte, tienen una visión más informática, que tiene como objetivo conseguir un modelo computacional concreto de nuestro cerebro, para desarrollar cerebros virtuales.
También hay dinero privado. Con objetivos mucho más prácticos, Google, Microsoft, Baidu (Google China), Facebook y otras grandes empresas han creado sus propios proyectos de investigación. Dada la naturaleza de estas empresas, se detecta de inmediato que la visión es muy “informática”: se basa en el cerebro humano para imitar artificialmente nuestra inteligencia y ofrecer así servicios mucho más inteligentes.

Este artículo pretende dar a conocer el concepto innovador que está en el centro de los proyectos de estas grandes empresas: el deep learning (aprendizaje profundo). Este concepto lleva a otro nivel las redes neuronales artificiales que se inventaron en los años 60 y 70 del siglo pasado. En 2006 el investigador Geoffrey Hinton publicó las bases del deep learning. Hinton trabaja actualmente en Google.
Redes neuronales artificiales
La primera parada de este viaje es en redes neuronales artificiales. Al igual que el cerebro humano, estas redes artificiales están basadas en neuronas. Cada neurona tiene unas entradas y una salida. Tanto las entradas como las salidas son sólo números. Por tanto, el trabajo de una neurona consiste en tomar las entradas y calcular una salida utilizando para ello unas sencillas funciones matemáticas. Las neuronas se organizan en redes formando capas. Normalmente existe una capa de entrada. Si hiciéramos una comparación con nuestro cerebro, la capa de entrada se utilizaría para recoger información sensible. A continuación se colocan capas ocultas y finalmente capa de salida (por ejemplo, neuronas que envían señales a nuestros músculos). En la figura 1 se puede ver una estructura sencilla de la misma.
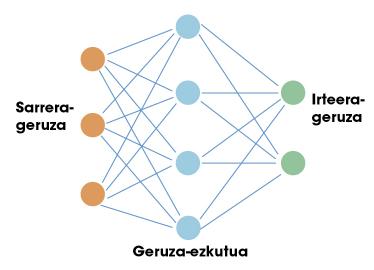
Éxito de redes neuronales en el ámbito de la inteligencia artificial. La clave está en el teorema de la aproximación universal. Algunos matemáticos demostraron que una red neuronal con una sola capa oculta puede aproximarse a cualquier función no lineal. En otras palabras, una red neuronal puede aprender cualquier relación posible entre los números de entrada y salida. En el caso de un ser humano, puede aprender cualquier reacción relacionada con la información que reciben los sentidos. Ahí está precisamente el potencial de estas redes.
¿Es suficiente una sola capa?
Teóricamente se puede aprender cualquier relación con una capa oculta, pero en la práctica las redes tan sencillas no son muy útiles para tareas complejas. Por ejemplo, supongamos que queremos distinguir las caras de un montón de imágenes. La entrada a la red sería una imagen y la salida una cara o no en esa imagen. Debido a la complejidad de la información de entrada (en definitiva, una imagen es un montón de números), las redes de una capa no alcanzan resultados muy satisfactorios. Los investigadores tienen que trabajar mucho en las imágenes, realizando algunos procesamientos y calculando algunas características geométricas, para proporcionar a la red una menor y más significativa información (Figura 2). Así, las redes neuronales separan bien las caras.
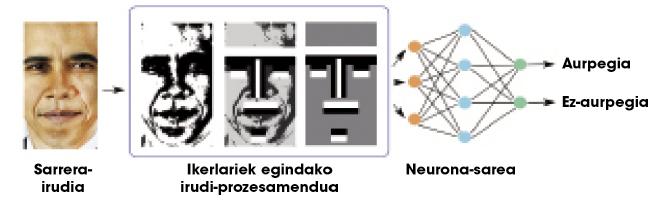
Nuestro cerebro realiza todos los cálculos correspondientes a cualquier tarea en la propia red neuronal, es decir, no hay investigadores externos que realicen el procesamiento de la figura 2. Para ello, nuestro cerebro se organiza en un montón de capas neuronales. Por ello, algunos investigadores pensaron que en lugar de usar una sola capa oculta, quizás habría que utilizar muchas capas para hacer frente a tareas complejas. Las redes neuronales con muchas capas se denominan “redes profundas”.
Problemas de entrenamiento en redes profundas
Para que una red neuronal funcione correctamente es necesario entrenar. En el caso de la figura 2 que acabamos de ver, antes de solicitar a la red la separación de caras, hay que mostrar un montón de imágenes indicando cuales son las caras y cuales no. De esta manera, la red aprende los parámetros de cada una de sus neuronas para realizar correctamente esta tarea concreta, es decir, la función no lineal que decíamos inicialmente se concreta en la fase de entrenamiento para relacionar los datos de entrada con las salidas.

Aplicando técnicas de entrenamiento en redes monocapa en redes profundas, los resultados eran muy malos: las redes profundas no aprendían nada. Pronto se dieron cuenta de que había grandes carencias en las técnicas de entrenamiento. No podían entender cómo entraba una red profunda. Por ello, hasta el año 2006 las redes de más de dos capas ocultas ni siquiera se utilizaban, ya que no podían entrenarse.
¿Qué pasó en el año 2006? Geoffrey Hinton creó junto a su equipo una revolucionaria técnica para entrenar redes profundas. Era un aprendizaje profundo, deep learning, recién nacido.
Google Brain sorprendente

Uno de los ejemplos más sorprendentes del uso del deep learning es Google Brain. Como se puede apreciar en la figura 4, utiliza 1000 ordenadores para mantener en funcionamiento una red profunda. En un artículo publicado en 2013, un grupo de investigadores de Google dio a conocer un gran paso adelante. Aprovechando la capacidad de Google Brain, entrenaron durante tres días una red profunda con resultados tan sorprendentes como curiosos.
Como hemos dicho antes, para aprender a diferenciar una cara hay que pasar una fase de entrenamiento en la que se da un montón de imágenes a la red y se le dice en qué imagen aparecen las caras y en qué imagen no. Este proceso se denomina “aprendizaje supervisado”. Según algunos neurocientíficos, los seres humanos no aprendemos así a diferenciar las caras, sino que, como vemos muchas veces las caras, nuestro cerebro aprende un modelo de rostro, sin que nadie diga que ese modelo es una cara. Es decir, el aprendizaje no es supervisado.
Los investigadores de Google se sumaron a estas teorías y preguntaron: “¿Es posible que una red profunda aprenda de forma no supervisada qué es una cara?” Para responder a la pregunta, crearon una red profunda basada en la estructura del cerebro humano. La red cuenta con mil millones de parámetros para entrenar. A pesar de que es terrible, ¡la corteza visual de un ser humano sólo tiene 100 veces más neuronas y sinapsis! En la figura 5 se puede ver una representación de la red.
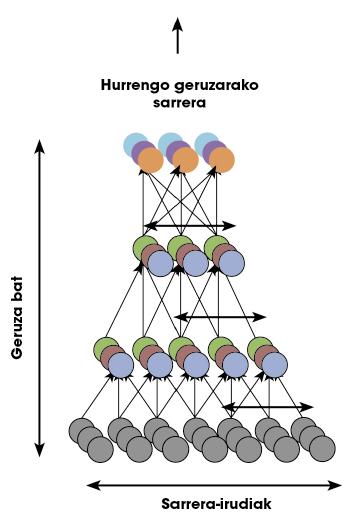
Los investigadores justificaron que en los vídeos que están en Youtube aparecen un montón de caras humanas. Por lo tanto, si seleccionamos aleatoriamente un montón de vídeos y utilizamos las imágenes para entrenar la red, la red debería aprender el modelo de una cara. Decir y hacer. Tras tres días de entrenamiento, mostraron a la red imágenes con caras. En porcentajes muy altos (81,7%), la red respondía frente a estas imágenes con el mismo patrón de activación. En las imágenes en las que no aparecían caras, no mostraba ninguna activación de este tipo. Quería decir que la red sabía qué era una cara.
Mediante técnicas avanzadas de representación, los patrones de activación pueden convertirse en espectaculares características geométricas. Los investigadores utilizaron estas técnicas para representar el modelo de la cara que la red tenía “guardada”. En la figura 6 se puede ver un resultado de terrible apariencia.
Como sabéis, en Youtube aparecen en muchas ocasiones gatos además de humanos. Es lógico pensar, por tanto, que la red también estudiaría lo que es un gato. Para resolver la duda, los investigadores recogieron imágenes de gatos y las pasaron a la red. Y sí, la red mostraba patrones de activación similares a los de las caras. Aquí tenéis el modelo de gato que aprendió la red (figura 7).

¿Por qué funcionan tan bien las redes profundas? Parece que la razón es su estructura jerárquica. Las neuronas tienen la capacidad de guardar modelos abstractos de la información de la capa inferior por capa, desde las diferencias de color entre los píxeles de una imagen (primera capa) hasta las características geométricas (últimas capas). Además, todas estas características y modelos pueden aprender a su caso según los datos que se les faciliten.
¿Y ahora qué?
Este trabajo que acabamos de exponer fue publicado en 2013, “ayer”. El Deep Learning sigue siendo un campo muy “joven” y, por tanto, tiene un gran futuro. Por ejemplo, hay una conocida base de datos con un montón de imágenes, ImageNet, en la que se organizan concursos de separación de objetos en imágenes. Google fue el último vencedor. Esta base de datos ha calculado experimentalmente que los seres humanos tenemos una tasa de error del 5,1%. La empresa china Baidu ha publicado recientemente una tasa de error del 5,98% con el deep learning, aunque todavía no se ha demostrado oficialmente.

El deep learning está obteniendo muy buenos resultados en la comprensión de lenguajes naturales y en las tareas visuales, dos de las capacidades más importantes que tenemos los seres humanos. Se han realizado trabajos basados en las neurociencias, aunque los modelos que se utilizan todavía no son muy precisos. Seguramente las aportaciones de los proyectos Human Brain Project y BRAIN Initiative nos enseñarán nuevos caminos. En algún momento, los avances en neurociencia y en inteligencia artificial se encontrarán creando cerebros virtuales más poderosos. Quién sabe...
Bibliografía

Zu idazle
Zientzia aldizkaria

