

Petits cervells virtuals
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea

Grans projectes en marxa
Les majors potències del món ja han començat l'estudi del cervell amb grans projectes. D'una banda, cal destacar dos projectes que reben fons públics: BRAIN Initiative dels EUA i Human Brain Project d'Europa. Tots dos projectes tenen diferents perspectives: els americans busquen obtenir un mapa del cervell concret, analitzant bé el funcionament de cada neurona; els europeus, per part seva, tenen una visió més informàtica, que té com a objectiu aconseguir un model computacional concret del nostre cervell, per a desenvolupar cervells virtuals.
També hi ha diners privats. Amb objectius molt més pràctics, Google, Microsoft, Baidu (Google Xina), Facebook i altres grans empreses han creat els seus propis projectes de recerca. Donada la naturalesa d'aquestes empreses, es detecta immediatament que la visió és molt “informàtica”: es basa en el cervell humà per a imitar artificialment la nostra intel·ligència i oferir així serveis molt més intel·ligents.

Aquest article pretén donar a conèixer el concepte innovador que està en el centre dels projectes d'aquestes grans empreses: el deep learning (aprenentatge profund). Aquest concepte porta a un altre nivell les xarxes neuronals artificials que es van inventar en els anys 60 i 70 del segle passat. En 2006 l'investigador Geoffrey Hinton va publicar les bases del deep learning. Hinton treballa actualment en Google.
Xarxes neuronals artificials
La primera parada d'aquest viatge és en xarxes neuronals artificials. Igual que el cervell humà, aquestes xarxes artificials estan basades en neurones. Cada neurona té unes entrades i una sortida. Tant les entrades com les sortides són només números. Per tant, el treball d'una neurona consisteix a prendre les entrades i calcular una sortida utilitzant per a això unes senzilles funcions matemàtiques. Les neurones s'organitzen en xarxes formant capes. Normalment existeix una capa d'entrada. Si féssim una comparació amb el nostre cervell, la capa d'entrada s'utilitzaria per a recollir informació sensible. A continuació es col·loquen capes ocultes i finalment capa de sortida (per exemple, neurones que envien senyals als nostres músculs). En la figura 1 es pot veure una estructura senzilla d'aquesta.
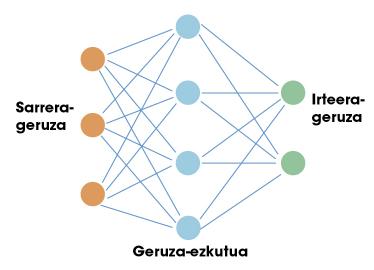
Èxit de xarxes neuronals en l'àmbit de la intel·ligència artificial. La clau està en el teorema de l'aproximació universal. Alguns matemàtics van demostrar que una xarxa neuronal amb una sola capa oculta pot aproximar-se a qualsevol funció no lineal. En altres paraules, una xarxa neuronal pot aprendre qualsevol relació possible entre els números d'entrada i sortida. En el cas d'un ésser humà, pot aprendre qualsevol reacció relacionada amb la informació que reben els sentits. Aquí està precisament el potencial d'aquestes xarxes.
És suficient una sola capa?
Teòricament es pot aprendre qualsevol relació amb una capa oculta, però en la pràctica les xarxes tan senzilles no són molt útils per a tasques complexes. Per exemple, suposem que volem distingir les cares d'un munt d'imatges. L'entrada a la xarxa seria una imatge i la sortida una cara o no en aquesta imatge. A causa de la complexitat de la informació d'entrada (en definitiva, una imatge és un munt de números), les xarxes d'una capa no aconsegueixen resultats molt satisfactoris. Els investigadors han de treballar molt en les imatges, realitzant alguns processaments i calculant algunes característiques geomètriques, per a proporcionar a la xarxa una menor i més significativa informació (Figura 2). Així, les xarxes neuronals separen bé les cares.
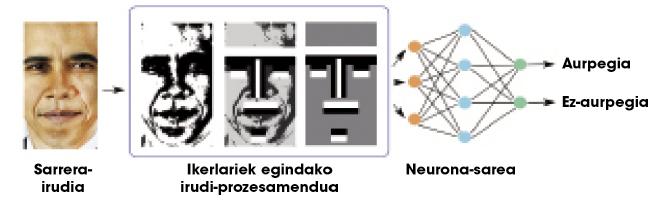
El nostre cervell realitza tots els càlculs corresponents a qualsevol tasca en la pròpia xarxa neuronal, és a dir, no hi ha investigadors externs que realitzin el processament de la figura 2. Per a això, el nostre cervell s'organitza en un munt de capes neuronals. Per això, alguns investigadors van pensar que en lloc d'usar una sola capa oculta, potser caldria utilitzar moltes capes per a fer front a tasques complexes. Les xarxes neuronals amb moltes capes es denominen “xarxes profundes”.
Problemes d'entrenament en xarxes profundes
Perquè una xarxa neuronal funcioni correctament és necessari entrenar. En el cas de la figura 2 que acabem de veure, abans de sol·licitar a la xarxa la separació de cares, cal mostrar un munt d'imatges indicant quals són les cares i quals no. D'aquesta manera, la xarxa aprèn els paràmetres de cadascuna de les seves neurones per a realitzar correctament aquesta tasca concreta, és a dir, la funció no lineal que dèiem inicialment es concreta en la fase d'entrenament per a relacionar les dades d'entrada amb les sortides.

Aplicant tècniques d'entrenament en xarxes monocapa en xarxes profundes, els resultats eren molt dolents: les xarxes profundes no aprenien res. Aviat es van adonar que hi havia grans manques en les tècniques d'entrenament. No podien entendre com entrava una xarxa profunda. Per això, fins a l'any 2006 les xarxes de més de dues capes ocultes ni tan sols s'utilitzaven, ja que no podien entrenar-se.
Què va passar l'any 2006? Geoffrey Hinton va crear al costat del seu equip una revolucionària tècnica per a entrenar xarxes profundes. Era un aprenentatge profund, deep learning, nounat.
Google Brain sorprenent

Un dels exemples més sorprenents de l'ús del deep learning és Google Brain. Com es pot apreciar en la figura 4, utilitza 1000 ordinadors per a mantenir en funcionament una xarxa profunda. En un article publicat en 2013, un grup d'investigadors de Google va donar a conèixer un gran pas endavant. Aprofitant la capacitat de Google Brain, van entrenar durant tres dies una xarxa profunda amb resultats tan sorprenents com curiosos.
Com hem dit abans, per a aprendre a diferenciar una cara cal passar una fase d'entrenament en la qual es dóna un munt d'imatges a la xarxa i se li diu en quina imatge apareixen les cares i en quina imatge no. Aquest procés es denomina “aprenentatge supervisat”. Segons alguns neurocientífics, els éssers humans no aprenem així a diferenciar les cares, sinó que, com veiem moltes vegades les cares, el nostre cervell aprèn un model de rostre, sense que ningú digui que aquest model és una cara. És a dir, l'aprenentatge no és supervisat.
Els investigadors de Google es van sumar a aquestes teories i van preguntar: “És possible que una xarxa profunda aprengui de forma no supervisada què és una cara?” Per a respondre a la pregunta, van crear una xarxa profunda basada en l'estructura del cervell humà. La xarxa compta amb mil milions de paràmetres per a entrenar. A pesar que és terrible, l'escorça visual d'un ésser humà només té 100 vegades més neurones i sinapsis! En la figura 5 es pot veure una representació de la xarxa.
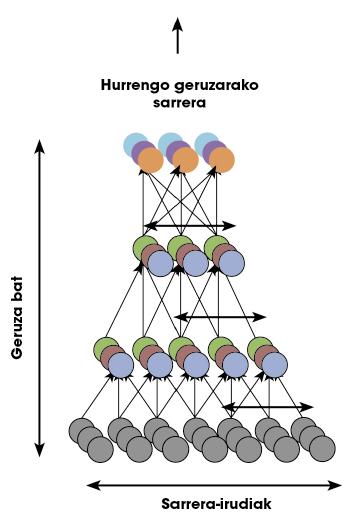
Els investigadors van justificar que en els vídeos que estan en Youtube apareixen un munt de cares humanes. Per tant, si seleccionem aleatòriament un munt de vídeos i utilitzem les imatges per a entrenar la xarxa, la xarxa hauria d'aprendre el model d'una cara. Dir i fer. Després de tres dies d'entrenament, van mostrar a la xarxa imatges amb cares. En percentatges molt alts (81,7%), la xarxa responia enfront d'aquestes imatges amb el mateix patró d'activació. En les imatges en les quals no apareixien cares, no mostrava cap activació d'aquest tipus. Volia dir que la xarxa sabia què era una cara.
Mitjançant tècniques avançades de representació, els patrons d'activació poden convertir-se en espectaculars característiques geomètriques. Els investigadors van utilitzar aquestes tècniques per a representar el model de la cara que la xarxa tenia “guardada”. En la figura 6 es pot veure un resultat de terrible aparença.
Com sabeu, en Youtube apareixen en moltes ocasions gats a més d'humans. És lògic pensar, per tant, que la xarxa també estudiaria el que és un gat. Per a resoldre el dubte, els investigadors van recollir imatges de gats i les van passar a la xarxa. I sí, la xarxa mostrava patrons d'activació similars als de les cares. Aquí teniu el model de gat que va aprendre la xarxa (figura 7).

Per què funcionen tan bé les xarxes profundes? Sembla que la raó és la seva estructura jeràrquica. Les neurones tenen la capacitat de guardar models abstractes de la informació de la capa inferior per capa, des de les diferències de color entre els píxels d'una imatge (primera capa) fins a les característiques geomètriques (últimes capes). A més, totes aquestes característiques i models poden aprendre al seu cas segons les dades que se'ls facilitin.
I ara què?
Aquest treball que acabem d'exposar va ser publicat en 2013, “ahir”. El Deep Learning continua sent un camp molt “jove” i, per tant, té un gran futur. Per exemple, hi ha una coneguda base de dades amb un munt d'imatges, ImageNet, en la qual s'organitzen concursos de separació d'objectes en imatges. Google va ser l'últim vencedor. Aquesta base de dades ha calculat experimentalment que els éssers humans tenim una taxa d'error del 5,1%. L'empresa xinesa Baidu ha publicat recentment una taxa d'error del 5,98% amb el deep learning, encara que encara no s'ha demostrat oficialment.

El deep learning està obtenint molt bons resultats en la comprensió de llenguatges naturals i en les tasques visuals, dues de les capacitats més importants que tenim els éssers humans. S'han fet treballs basats en les neurociències, encara que els models que s'utilitzen encara no són molt precisos. Segurament les aportacions dels projectes Human Brain Project i BRAIN Initiative ens ensenyaran nous camins. En algun moment, els avanços en neurociència i en intel·ligència artificial es trobaran creant cervells virtuals més poderosos. Qui sap...
Bibliografia

Zu idazle
Zientzia aldizkaria

