

Garun txiki birtualak
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea

Proiektu handiak martxan
Munduko potentzia handienek ekin diote jada garunaren azterketari, proiektu handiak abiaraziz. Alde batetik, diru publikoa jasotzen duten bi proiektu nabarmendu daitezke: AEBko BRAIN Initiative eta Europako Human Brain Project. Ikuspegi ezberdinak dituzte bi proiektuok: amerikarrek, garunaren mapa zehatz bat lortu nahi dute, neurona bakoitzaren funtzionamendua ongi aztertuz; europarrek, berriz, ikuspegi informatikoagoa dute, zeinak gure garunaren eredu konputazional zehatz bat lortzea duen helburu, garun birtualak garatzeko betiere.
Diru pribaturik ere bada tartean. Helburu askoz praktikoagoak tarteko direla, Google, Microsoft, Baidu (Txinako Google), Facebook eta beste zenbait enpresa erraldoik beren ikerkuntza-proiektu propioak sortu dituzte. Enpresa horien izaera ikusirik, berehala atzematen da ikuspegia oso “informatikoa” dela: giza garuna hartzen dute oinarritzat, gure adimena artifizialki imitatu eta, hartara, zerbitzu askoz adimentsuagoak eskaintzeko.

Enpresa handi horien proiektuen muinean dagoen kontzeptu berritzailea azaltzea du xede artikulu honek: deep learninga, alegia (ikasketa sakona). Aurreko mendeko 60ko eta 70eko hamarkadetan asmatu ziren neurona-sare artifizialak beste maila batera eramaten ditu kontzeptu horrek. 2006. urtean argitaratu zituen Geoffrey Hinton ikerlariak deep learningaren oinarriak. Googlen ari da lanean Hinton gaur egun.
Neurona-sare artifizialak
Bidaia honen lehen geldialdia neurona-sare artifizialetan egin behar dugu. Giza garunak bezalatsu, sare artifizial horiek ere neuronak dituzte oinarri. Neurona bakoitzak sarrera batzuk ditu, eta irteera bat. Bai sarrerak, bai irteerak zenbakiak besterik ez dira. Beraz, sarrerak hartu eta irteera bat kalkulatzea da neurona baten lana, horretarako funtzio matematiko sinple batzuk erabiliz. Saretan antolatzen dira neuronak, geruzak osatuz. Eskuarki, sarrera-geruza bat egon ohi da. Gure garunarekin konparazio bat egingo bagenu, sarrera-geruza zentzumenen bidezko informazioa jasotzeko erabiliko litzateke. Ondoren, geruza ezkutuak jarri ohi dira; azkenik, irteera-geruza (adibidez, gure muskuluetara seinaleak bidaltzen dituzten neuronak). 1. irudian ikusten da horren egitura sinple bat.
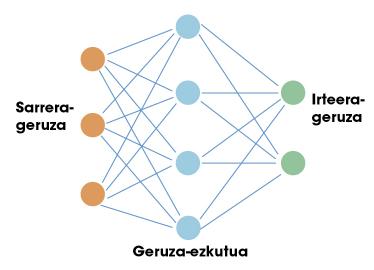
Arrakasta handia izan dute neurona-sareek adimen artifizialaren esparruan. Hurbilketa unibertsalaren teoreman dago horren gakoa. Matematikari batzuek frogatu zutenez, geruza ezkutu bakarra duen neurona-sare bat edozein funtzio ez-linealetara hurbil daiteke. Beste hitz batzuetan esanda, sarrera- eta irteera-zenbakien arteko edozein erlazio posible ikas dezake neurona-sare batek. Gizaki baten kasuan, zentzumenek jasotzen duten informazioari dagokion edozein erreakzio ikas dezake. Hortxe dago, hain juxtu ere, sare horien potentziala.
Nahikoa ote geruza bakar bat?
Teorikoki, geruza ezkutu batekiko edozein erlazio ikas daiteke, baina, praktikan, sare hain sinpleak ez dira oso erabilgarriak ataza konplexuetarako. Demagun, adibidez, irudi-pilo bateko aurpegiak bereizi nahi ditugula. Sarearen sarrera irudi bat litzateke, eta irteera, berriz, irudi horretan aurpegi bat egotea edo ez egotea. Sarrerako informazioaren konplexutasuna dela eta (azken batean, irudi bat zenbaki-pilo bat da), geruza bateko sareek ez dituzte oso emaitza onak lortzen. Irudietan lan handia egin behar izaten dute ikerlariek, prozesamendu batzuk eginez eta ezaugarri geometriko batzuk kalkulatuz, sareari informazio gutxiago eta esanguratsuagoa emateko (2. irudia). Horrela, neurona-sareek ongi bereizten dituzte aurpegiak.
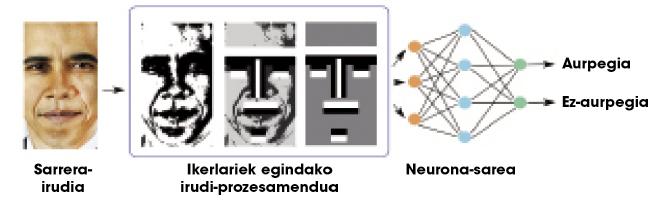
Neurona-sarean bertan egiten ditu gure garunak edozein atazari dagozkion kalkulu guztiak, hots, ez dago kanpoko ikerlaririk 2. irudiko prozesamendurik egiteko. Horretarako, neurona-geruza pilo batean antolatzen da gure garuna. Hori dela eta, ikerlari batzuek pentsatu zuten geruza ezkutu bakarra erabili beharrean, agian geruza asko erabili beharko liratekeela ataza konplexuei aurre egiteko. “Sare sakonak” deitzen zaie geruza asko dituzten neurona-sareei.
Entrenamendu-arazoak sare sakonetan
Neurona-sare batek behar bezala funtziona dezan, entrenatu egin behar da. Ikusi berri dugun 2. irudiaren kasuan, sareari aurpegiak bereizteko eskatu aurretik, irudi-pilo bat erakutsi behar zaizkio, zein diren aurpegiak eta zein ez adieraziz. Hartara, sareak bere neurona bakoitzaren parametroak ikasten ditu, ataza jakin hori behar bezala egiteko; hau da, hasieran esaten genuen funtzio ez-lineal hori entrenamendu fasean zehazten da, sarrera-datuak irteerekin erlazionatzeko.

Geruza bakarreko sareetan erabiltzen ziren entrenamendu-teknikak aplikatuz gero sare sakonetan, oso txarrak izaten ziren emaitzak: sare sakonek ez zuten ezer ikasten. Azkar ohartu ziren ikerlariak gabezia handiak zeudela entrenamendu-tekniketan. Ezin zuten ulertu sare sakon bat nola entrena zitekeen. Hori dela eta, 2006. urtera arte bi geruza ezkutu baino gehiagoko sareak ez ziren erabili ere egiten, ezin baitziren entrenatu.
Zer gertatu zen, bada, 2006. urtean? Geoffrey Hintonek sare sakonak entrenatzeko teknika iraultzaile bat sortu zuen, bere taldearekin batera. Ikasketa sakona, deep learninga, jaio berria zen.
Google Brain harrigarria

Deep learningaren erabileraren adibide harrigarrienetako bat Google Brain dugu. Laugarren irudian ongi ikusten den bezala, 1.000 ordenagailu erabiltzen ditu sare sakon bat martxan mantentzeko. 2013. urtean argitaratu zen artikulu batean, Googleko ikerlari-talde batek aurrerapauso handi baten berri eman zuen. Google Brainen gaitasunaz baliatuz, sare sakon bat entrenatu zuten hiru egunez, eta emaitza txundigarriak bezain bitxiak lortu.
Lehen esan dugun bezala, aurpegi bat bereizten ikasteko entrenamendu-fase bat pasatu behar da, non irudi-pilo bat ematen zaion sareari eta esaten zaion zein iruditan agertzen diren aurpegiak eta zein iruditan ez. Prozesu horri “ikasketa gainbegiratua” deritzo. Neurozientzialari batzuen arabera, gizakiok ez dugu ikasten horrela aurpegiak bereizten, honela baizik: aurpegiak askotan ikusten ditugunez, gure garunak aurpegi-eredu bat ikasten du, inork esan gabe eredu hori aurpegi bat dela. Hots, ikasketa ez da gainbegiratua.
Googleko ikerlariek teoria horiekin bat egin zuten, eta galdera hau luzatu: “Posible al da sare sakon batek aurpegi bat zer den ikastea modu ez-gainbegiratuan?” Galderari erantzuteko, giza garunaren egituran oinarritzen den sare sakon bat eratu zuten. Mila milioi parametro ditu sareak, entrenatzeko. Ikaragarria bada ere, gizaki baten ikusmen-kortexak bakarrik hori baino 100 aldiz neurona eta sinapsi gehiago ditu! Bosgarren irudian duzue sarearen irudikapen bat.
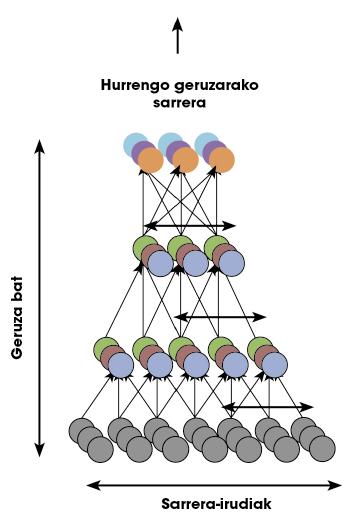
Ikerlariek arrazoitu zuten Youtuben dauden bideoetan gizakien aurpegi-pilo bat agertzen direla. Beraz, ausaz bideo-pilo bat aukeratu eta irudiak sarea entrenatzeko erabiliz gero, sareak aurpegi baten eredua ikasi beharko luke. Esan eta egin. Hiru egun entrenamendu-prozesuan jardun eta gero, aurpegiak zituzten irudiak erakutsi zizkioten sareari. Portzentaje oso altuetan (% 81,7), sareak aktibazio-patroi berarekinerantzuten zuen irudi horien aurrean. Aurpegiak agertzen ez ziren irudietan, berriz, ez zuen horrelako aktibaziorik erakusten. Hona zer esan nahi zuen: sareak bazekiela aurpegi bat zer zen.
Irudikapen-teknika aurreratu batzuk erabilita, aktibazio-patroiak ezaugarri geometriko ikusgarri bilaka daitezke. Ikerlariek teknika horiek erabili zituzten sareak “gordeta” zuen aurpegiaren eredua irudikatzeko. Seigarren irudian duzue itxura beldurgarriko emaitza.
Dakizuenez, Youtuben gizakiez gain katuak ere agertzen dira askotan. Pentsatzekoa da, beraz, agian katu bat zer den ere ikasiko zuela sareak. Zalantza argitzeko, katuen irudiak bildu zituzten ikerlariek, eta sareari pasatu zizkioten. Eta bai: aktibazio-patroi bertsuak ageri zituen sareak, aurpegiekin gertatzen zen antzera. Hemen duzue sareak ikasi zuen katuaren eredua (7. irudia).

Zergatik funtzionatzen duten sare sakonek hain ondo? Badirudi arrazoia haien egitura hierarkikoa dela. Geruza bakoitzeko, azpiko geruzako informazioaren eredu abstraktuak gordetzeko gaitasuna dute neuronek, irudi bateko pixelen arteko kolore-ezberdintasunetatik hasi (lehen geruza) eta ezaugarri geometrikoetaraino (azken geruzak). Gainera, ezaugarri eta eredu horiek guztiak, beren kasara ikasi ditzakete ematen zaizkien datuen arabera.
Eta orain zer?
2013an argitaratu zen azaldu berria dugun lan hori; hots, “atzo”. Deep learninga oso eremu “gaztea” da oraindik eta, beraz, etorkizun oparoa du. Adibidez, bada irudi-pilo bat biltzen dituen datu-base ezagun bat, ImageNet, non irudietan objektuak bereizteko lehiaketak antolatzen diren. Google izan zen azken garailea. Esperimentuen bidez, gizakiok % 5,1eko errore-tasa dugula kalkulatu du datu-base horrek. Bada, deep learningaz baliatuz % 5,98ko errore-tasa lortu duela argitaratu berri du Baidu enpresa txinatarrak, oraindik ofizialki frogatu ez bada ere.

Oso emaitza onak ari da izaten deep learninga lengoaia naturalen ulermenean eta ikusmen-atazetan, gizakiok ditugun bi gaitasun garrantzitsuenetakoetan, alegia. Neurozientzietan oinarritutako lanak egin dira, nahiz eta erabiltzen diren ereduak ez izan, oraindik, guztiz zehatzak. Seguru aski, Human Brain Project eta BRAIN Initiative proiektuen ekarpenek bide berriak erakutsiko dizkigute. Momenturen batean, neurozientziaren aurrerapenek eta adimen artifizialarenek elkarrekin topo egin eta garun birtual boteretsuagoak sortuko dituzte. Nork jakin...
Bibliografia

Idatzi zuk zeuk Gai librean atalean
Gai librean aritzeko, bidali zure artikulua aldizkaria@elhuyar.eus helbidera
Hauek dira Gai librean atalean Idazteko arauak
Zu idazle
Zientzia aldizkaria

