

¿Error con o sin h?

Estimación error diferente
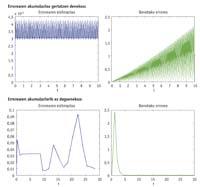
Si una ecuación diferencial no se puede resolver analíticamente, se puede resolver mediante métodos numéricos. El resultado analítico es preciso, mientras que el resultado obtenido por el método numérico es aproximado y se construye paso a paso. El error al soltar una ecuación diferencial por método numérico es la diferencia entre el resultado exacto y el aproximado. Un concepto que teóricamente no tiene más dificultades que una sustracción, cuando hay que calcularlo en la práctica se convierte en un concepto complejo. Pero, ¿cuál es el problema? Que desconocemos los resultados exactos de muchas ecuaciones diferenciales. Por ello, al desconocernos el resultado exacto, nos resulta imposible calcular el error que estamos cometiendo al utilizar el método numérico. Aunque no conocemos el error, sabemos que el resultado aproximado que se obtiene utilizando métodos numéricos de orden alto es más preciso que el obtenido con métodos numéricos de orden inferior. Sin embargo, cada vez que se da un paso por el método numérico, se suele utilizar una medida que nos dice si el resultado obtenido en ese paso es válido o no. ¿Qué medida es esta si hemos dicho que no se puede calcular el error sin conocer el resultado concreto?
La medida utilizada es la estimación del error. Una estimación de error de gran utilidad es la que se calcula como la diferencia de resultados que se obtiene utilizando métodos numéricos de orden sucesivo, basada en la eliminación del resultado obtenido mediante la utilización de un método numérico de orden ( n+1 ), que se conoce como extrapolación local. Cuando la utilizamos, en cada paso exigimos que la diferencia entre los resultados obtenidos por dos métodos consecutivos sea inferior a una tolerancia previamente establecida. Si se cumple la condición, se acepta el resultado dado por el método de orden ( n+1 ), de lo contrario será necesario repetir las operaciones de paso y probarlo con otro paso inferior al utilizado anteriormente. Si quisiéramos utilizar extrapolación local de alguna de las medidas a realizar en un laboratorio, se realizarían dos mediciones de la cantidad que se desea medir utilizando dos aparatos de diferente precisión. Dado que las precisiones de estos aparatos deben ser consecutivas, cuando se dispone de un aparato de mayor precisión, el segundo será el que tenga mayor precisión entre los aparatos de menor precisión que el primero. De esta manera, aseguraríamos que estamos utilizando aparatos con precisiones sucesivas. La medida debería repetirse hasta que la diferencia entre ambas medidas sea inferior a un valor determinado y, si se cumple la condición, se aceptará el resultado del aparato de mayor precisión. Como se puede apreciar en el ejemplo de laboratorio, el desconocimiento del resultado real se paga con la duplicación del número de cálculos.

Por tanto, la extrapolación local es un recurso seguro pero caro a la vez. Dado que su potencial se basa en la comparación de los resultados obtenidos con dos métodos de diferente orden, siempre supondrá un aumento del número de cálculos. Aprovechando la certeza de la extrapolación local y aceptando el aumento que va a suponer en el número de cálculos, muchos de los creadores o padres de métodos numéricos se han centrado en el diseño de métodos que podían hacer que este número de cálculos no llegara a duplicarse, es decir, han tenido como objetivo dar a luz dos métodos de orden sucesivo con las menores diferencias posibles. En este sentido, mediante la utilización de un juego de constantes diferente en una sola operación, los métodos que realizan un método de orden n o ( n+1 ) son muy útiles, ya que consiguen optimizar la diferencia entre dos métodos de orden sucesivo. Ejemplo de ello son los métodos Runge-Kutta introducidos. En ellas, basta con que, además de las operaciones realizadas para obtener el resultado por el método de orden ( n+1 ), se realice una única operación para obtener el resultado que nos proporciona el método de orden n. Ofrecen, por tanto, una opción económica para obtener resultados de diferentes órdenes. Sólo hay otra opción más económica que la de conseguir ambas al precio de una. Pero eso es imposible, porque habrá que diferenciar los diferentes métodos en algo.
Estimación con h sin h

A veces, el descenso de la barrera no se verá afectado, ya que habrá estimaciones que pasarían sin ayuda la altura inicial de la barrera. Pero habrá saltos que no pueden superar la altura inicial de la barrera y que se verán afectados por el descenso de la barrera. En consecuencia, el paso que debería repetirse utilizando otra estimación se considerará válido. La repetición de un paso supone probar con pasos más pequeños, y si los pasos son pequeños, se necesita más. Por lo tanto, cuando utilizamos las estimaciones en las que estamos bajando la barrera, se darán menos pasos y por lo tanto mayores que en las que no bajan. La moneda, sin embargo, tiene otro aspecto, ya que puede ocurrir que el descenso de la barrera no tenga el resultado deseado. Esto puede influir negativamente en el error final y reducir drásticamente la calidad del resultado aproximado que obtenemos. En general, la estimación que se calcula sin h conllevará la necesidad de dar pasos más pequeños, pero la acumulación de error real también será menor.

Estimación error en h o sin h
Las ecuaciones diferenciales pueden ser rígidas o no rígidas. La definición práctica de la ecuación diferencial rígida es la de una ecuación que debe dar muchos pasos a un algoritmo. Aunque la palabra "mucho" no indica números concretos, 100 pasos no son muchos y 3.000 son muchos. Cuando el problema es rígido, se prefiere utilizar una estimación sin “h”, ya que con la estimación con “h” se obtendrá un resultado mucho mejor que el que se obtendría con la estimación sin “h”. Aunque el problema no sea rígido, el resultado obtenido con una estimación sin h será, en la mayoría de los casos, mejor que el obtenido con h, pero el resultado --diferencia entre ambos - no será tan espectacular, es decir, el trabajo adicional que supone la utilización de una estimación sin h en ecuaciones diferenciales no rígidas no generará mucho brillo en la solución.

En los idiomas es habitual que una palabra pierda o gane la "h" según la época. Ejemplos de ello son la construcción de muros a veces con o sin h, o la curación de pacientes en hospitales con o sin h. Sin embargo, la función o significado de las palabras que se han pegado o eliminado la “h” por la época ha seguido siendo la misma. El tema de los errores con h y sin h en matemáticas no depende de la época: siempre ha estado la convivencia entre ambos, y ambos son necesarios porque la función de uno y otro nunca ha sido la misma. Al igual que consultamos en el diccionario si una palabra tiene o no una “h”, para decidir si utiliza o no una “h” en la estimación del error habrá que “consultar” el problema a liberar, ya que la clave del éxito que obtendremos en el resultado será que la estimación del error tenga o no una “h”.

Zu idazle
Zientzia aldizkaria

