

Descubridor informático de rima paira o bertsolarismo
Está claro que crear no xadrez algo como o "Deep Blue" que gañou a Kasparov é polo momento imposible no bertsolarismo. Está claro que aínda non imos conseguir ningún bertsolari virtual, non imos crear una máquina de bertsos ao nivel dun Andoni Egaña. Pero una aplicación que axude a facer bertsos, por que non? O descubridor de rima que se presenta neste artigo pretende ser una axuda paira os que non son tan hábiles nos bertsos, ou un soporte paira os que están a aprender a ser bertsolaris no futuro.

E é que desde a creación do primeiro computador, fai uns 40 anos, o desenvolvemento da informática foi enorme. Hoxe en día paira traballar en calquera ámbito ou área é case imprescindible una aplicación informática ou outra. Así, por que non usar a informática noutros ámbitos que queremos? E por que o bertsolarismo non será un deses campos? Está claro que estamos lonxe de conseguir una virtual Egaña ou Amuriza, porque se deixaron de lado polo momento uns obxectivos demasiado ambiciosos paira crear máquinas pensadoras ou similares que soñaron desde a creación da informática. Con todo, xa non seremos capaces de cumprir uns obxectivos máis sinxelos? Este descubridor informático de rima, nacido da idea de realizar una aplicación xeral que puidese axudar ao bertsolarista, non quere máis que ser una aplicación auxiliar paira atopar rimas.
Pero antes de entrar en explicacións máis profundas, situemos o noso traballo no campo da informática en cuestión, concretamente na intelixencia artificial, máis concretamente na enxeñaría lingüística, e analicemos a evolución deste campo, co obxectivo da máquina pensadora desde o seu nacemento até a actualidade.
Máquina pensadora: aquela barbaridade!
Ese era o obxectivo da intelixencia artificial (deberiamos dicir soño), desde que na década dos 50 bautizouse con estas palabras este campo da informática. Crear una máquina intelixente que puidese pensar.
Con todo, tras varios fracasos sufridos na década dos 60, na década dos 70 produciuse una especie de desilusión, acompañada dunha humildade de obxectivos. A sinxeleza dos obxectivos propiciou a creación dos primeiros grandes prototipos de "sistemas intelixentes" capaces de dar respostas en temas concretos e limitados. Así, por exemplo, MYCIN (Shortliffe, 1976), "sistema intelixente" que realizaba o tratamento e diagnóstico de enfermidades infecciosas, ou PROSPECTOR (Dúbidas e outros, 1976), seleccionaba os lugares adecuados paira realizar exploracións xeolóxicas.
O éxito destes primeiros prototipos trouxo consigo a implicación do mundo empresarial, coa consolidación e desenvolvemento da intelixencia artificial nos anos 80 e 90. Así, a intelixencia artificial ha chegado a ser una das liñas de investigación máis importantes dentro da informática.
O procesamiento da linguaxe natural (LNP), ou a enxeñaría lingüística, si deséxase, é un campo específico que se sitúa no ámbito da intelixencia artificial. Entre os resultados deste campo que analiza o tratamento automático da linguaxe atópanse as seguintes aplicacións informáticas: correctores ortográficos, sintácticos, tradutores automáticos, sistemas de recoñecemento de voz, etc. Paira conseguilos hai que ter en conta que cada lingua ten as súas peculiaridades. Por tanto, aínda que o proceso sexa similar paira todas as linguas, debe axustarse a cada una delas.
Pero antes de explicar o fondo deste proxecto, imos contar que é o que nos levou a levar a cabo este traballo, cales foron as motivacións e obxectivos que tivemos en conta á hora de realizar este traballo.
Motivacións e obxectivos: complicacións seguras
Nin que dicir ten que tesouro é o bertsolarismo. Son poucos os países que sosteñen este tipo de expresións orais. E este tipo de versos (ver figura 1) reflicten a esencia e riqueza do bertsolarismo espontáneo.
Con todo, moitas veces non nos damos conta da dificultade de facer un bertso. E é que, como desde o nacemento pode ser importante ter ou ser un bertsolari, o proceso de aprendizaxe pode ser máis importante. Non te perdas como saíron dunha escola de bertsos todos os bertsolaris actuais. Melodías, medidas, rimas… Non hai seres que nazan sabendo todo iso. Sabemos ben que nós, os afeccionados, quixemos e non puidemos.
Empezamos a traballar con estes pensamentos na cabeza. O bertsolarismo, as escolas de bertsolaris, como aprender a facer bertsos, como ensinalos… E na memoria de todos eles, sacamos a idea de facer una aplicación completa paira axudar aos bertsolaris principiantes, ou aos bertsolaris en xeral. A idea inicial foi facer una aplicación paira controlar as medidas, dar a coñecer as melodías, ter una biblioteca de bertsos antigos e novos, atopar rimas… Pero había que empezar por algún sitio. E paira decidir por onde empezar, aos afeccionados, ocorréusenos que era bo empezar polo que máis nos custa. E que se nos fai máis difícil que atopar rimas adecuadas paira un bertso?
Tiñamos o obxectivo marcado. Queriamos facer un descubridor informático de rima. Una aplicación que nos daría un final de palabra e daríanos todas as formas en eúscaro que coincidían con ese final. Pero como conseguir cun final de palabra todas as palabras vascas con ese final? E cando dicimos todos, ademais de todas as palabras que aparecen nos dicionarios, falamos de palabras derivadas e declinadas, de verbos compactos e xogados… Como conseguilas?
O investimento en eúscaro: esta é a mestura!
Primeiro de nada, vexamos en que nos baseamos á hora de realizar este traballo, porque non partimos de cero.
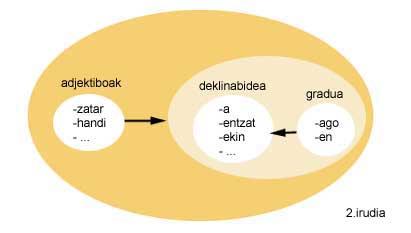
O grupo IXA ( www.ixa.si.ehu.es ) ten dixitalizada a descrición morfofónica do eúscaro (Agirre eta beste batzuk, 91) K. Segundo o modelo de morfología a dous niveis de Koskenniemi (Koskenniemi, 83). Nesta descrición morfo-fonológica do grupo IXA, cada entrada é un morfema vasco. Os morfemas, pola súa banda, están divididos en varios grupos e cada un ten definido a listaxe de grupos de entradas que pode seguir. Noutras palabras, se garda que morfemas poden seguir a cada morfema.
Se se analiza o exemplo da figura 2, obsérvase que os adxectivos poden seguir ao conxunto a declinación e o grao, e que ao mesmo tempo, a declinación pode seguirse polo conxunto grao.
Esta descrición morfológica do eúscaro é a base do analizador-creador morfológico paira o eúscaro. Este analizador-creador morfológico, por unha banda, realiza unha análise morfológico das palabras (ver exemplo) e, doutra banda, mediante unha introdución ao léxico, obtén todas as palabras que poden xurdir a partir desta entrada ao léxico (ver exemplo).
desgraciadamente
("desgraciadamente" ADB)
("desgraciadamente" IZE +DEK INS MG)
("desgraciadamente" IZE + DEK INS NUMP MUGM)
can
can
ao
can
con can.
O que necesitamos é, con todo, un creador morfológico que, partindo dun final de palabra, realizaría una creación inversa (ver exemplo).
máis información
estou
máis
pequeno…
...
Paira iso é necesario investir dalgunha maneira a descrición morfológica do eúscaro, en lugar de definir os grupos de entradas que poden ir por detrás dun conxunto de entradas, paira definir os que poden ir por diante. Noutras palabras, trátase de conseguir una serie de morfemas que poden ir por diante de cada morfema.
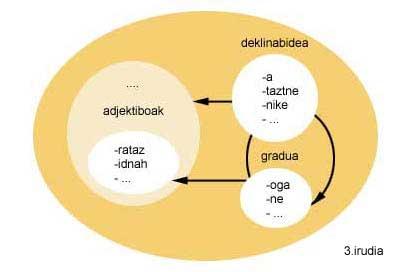
Seguindo co exemplo da figura 2, una vez investida esta descrición morfológica, a descrición morfológica que se obtería debería indicar que as entradas do grupo grao ou adxectivos poden ir por diante das entradas do grupo declinación, e as do grupo grao por diante das entradas do grupo.
Paira conseguilo hai que ter en conta como funciona o creador morfológico. O creador morfológico só pode realizar un encadeado cara adiante dos conxuntos de entrada, xa que crea as palabras segundo a orde que lle indica a descrición morfológica. Por tanto, non pode facer cadeas cara atrás. E dado que a creación parte dun final de palabra, paira investir a descrición morfológica, ademais de indicar que morfema vai despois do morfemo, os morfemas deberán investirse uno a un (ver figura 3) e, por tanto, o final de palabra que inicia a creación. Así pois, obteranse todas as palabras que coincidan con ese final de palabra, pero ao revés. Neste sentido, será necesario realizar una último investimento paira presentar as palabras correctamente ao usuario. Todo o proceso como final de palabra ' ekin'.
Con todo, hai outro aspecto que, por non habelo mencionado até agora, quedou patente co exemplo que utilizamos, o dos cambios morfofónicos. No caso da descrición morfológica retrospectiva antes do eúscaro, na creación iniciada co termo 'zatar' obteríanse formas como 'zatara', 'zataren' ou 'zatarago', en lugar de 'zatarra', 'zatarren', 'zatarrago' ou 'zatarrena'. Precisamente paira inducir estes cambios morfo-fonológicos, na descrición morfofónica do eúscaro defínense regras de 2 niveis (de aí o seu nome a este modelo). Así, cando una palabra que termina co carácter 'r' siga una forma que empeza por vogal, haberá que definir una regra que converta a 'r' brando en duro:
r + vogal -- rr + vogal
Paira o creador morfológico alternativo é necesario "investir" estas regras, xa que todos os morfemas están investidos e as unións entre morfemas tamén están investidas. Por tanto, a nova regra, paira conseguir un 'r' duro, deberá esixir que o contexto da esquerda teña a vocal e o da dereita o carácter 'r':
vogal + r -- vogal + rr
Seguindo co exemplo anterior, ao unir 'a' e 'rataz' (inversa de 'zatar') con esta regra obteríase 'arrataz'. O mesmo fíxose co resto das regras morfofonológicas.
Non hai que esquecer que todo isto se fixo de forma automática, xa que o investimento manual de todas as regras e de todas as entradas do léxico dunha nunha podía ser una tarefa enorme.
Por tanto, investindo así a descrición morfológica do eúscaro, conseguiuse o creador morfológico contraposto ao eúscaro, cun final de palabra que dá todas as palabras coincidentes con ese fin. Esta característica, que parece una vantaxe da aplicación, é dicir, a de dar todas as palabras, tamén será a orixe dos quebradizos de cabeza, xa que a lista de palabras que se xera con certos terminos de palabras é demasiado grande.
Por exemplo, co final da palabra 'ena', o número de palabras que se crean é enorme, ademais de palabras sinxelas ('pena', 'antena'...), palabras derivadas e declinadas ('maior', 'menor', 'máis bela'... 'etxena', 'mutilena', 'amarena' …), ou ben porque son moitos os verbos conxugados ('quen ten', 'quen os tiña', 'os que eramos'...). Por iso, tivéronse que tomar medidas paira romper dalgunha maneira o exceso de creación ou, polo menos, paira explicar primeiro as palabras que máis lle interesarían ao bertsolari.
A riqueza do eúscaro tróuxonos dificultades
Comezando polo estudo das peculiaridades do eúscaro, pódese observar que o eúscaro ten unhas características específicas que explican a riqueza que poden ter as palabras vascas ao final.
En primeiro lugar, a linguaxe é pegante, é dicir, tras un morfema poden ir outro ou outros. Por outra banda, a riqueza do verbo tamén é evidente, xa que son moitas as formas que pode adoptar cada verbo. E ademais, os seus catorce casos de declinación en flexión dan conta das diferentes formas que una palabra pode admitir ao final.
Precisamente por esa riqueza que poden ter as palabras vascas ao final, puxéronse de manifesto os problemas que pode ter a aplicación, segundo o final de palabra que dá o usuario, xa que as formas vascas que coinciden con ese final poden ser miles. Que se fixo paira solucionar este problema? Exponse dúas melloras principais.
Una, agrupar as palabras traducidas pola aplicación por categorías. Seguindo co exemplo anteriormente utilizado, en lugar de explicar 'o máis grande', 'o máis pequeno', 'o máis belo', poderíase dar un exemplo e una explicación da seguinte maneira:
maior
GRAD + a(NOMIN)ou
maior
(ADJ) + en(GENPL) + a(NOMIN)
Quedaría claro que ao engadir en+a todos os adxectivos obteríanse palabras que farían rima con ena, tanto aplicando a categoría de grao como aplicando o genitivo plural.
Outra categorización da mesma rima sería:
con
du(izan-ADI) + en(ERL) + a(NOMIN)Con todo, as palabras que se atopan fóra destas categorizaciones -as palabras compactadas- deberían mostrarse todas, xa que paira elas non existen criterios de agrupación: 'pena', 'antena', ...
A outra mellora vén na mesma liña. Dado que o bertsolari non aprecia por igual unhas rimas ou outras, a segunda mellora que se expuxo consiste en que unhas formas se expoñan antes que outras. Por iso, optouse por antepor as palabras ou formas máis apreciadas no bertsolarismo ás menos apreciadas. E creemos que, polo menos desde o punto de vista estilístico, aprécianse máis as palabras compactas ('pena', 'antena'...) que as palabras derivadas ('maior','menor'...), aínda que, en xeral, estea ben visto o uso de palabras derivadas, salvo que nun mesmo verso utilícense máis dunha rima da mesma categoría (Amuriza, 81). No entanto, á hora de presentar as palabras, decidimos primeiro dar palabras compactas e logo palabras derivadas.
Una ou dúas melloras non son demasiadas
Esta aplicación admitiría, como non podía ser doutra maneira, melloras e traballos complementarios en liña coas motivacións e ideas que tiñamos ao comezar con este traballo.
A primeira mellora consiste na capacidade da aplicación de mostrar as rimas por temas. Noutras palabras, ofreceríase ao usuario a posibilidade de buscar palabras rimadas dunha categoría semántica, é dicir, a aplicación mostraría todas as palabras que coincidan coa palabra e o tema elixidos polo usuario.
A segunda mellora sería presentar tamén as rimas asonantes ou as palabras que permiten as leis das familias de consonantes. Se o final fose '-dous', por exemplo, á hora de pedir todas as palabras que fagan rima con este final, é posible presentar palabras cos terminos 'dous', 'dei', 'gi', 'ri' a petición do usuario.
A terceira mellora consistiría en crear una interfaz web paira a aplicación e publicala en Internet, de forma que a aplicación estea dispoñible paira calquera. Xunto a isto, non estaría mal mellorar a rapidez da aplicación –tempo de resposta–.
E por último, máis que como mellora, o que hai que expor como obxectivo xeneral é crear un soporte paira o que está a aprender bertsos, ademais de rimas, paira medidas, melodías, etc., un profesor virtual de bertsos que ofreza axuda.
Como conclusión, poderiamos dicir que esta aplicación sería un traballo a situar dentro doutra aplicación máis grande. No entanto, se este apartado funciona pola súa conta e en canto realícense algunhas melloras, publicarase na rede Internet este descubridor informático de rima paira o seu uso público.
Nun futuro próximo, por tanto, este descubridor informático de rima pretende ser un soporte paira calquera afeccionado ao bertsolarismo, a fin de que ninguén quede sen rima á hora de facer algún bertso papel. Ou que sirva como mínimo paira atopar títulos brancos rimados a este tipo de artigos.
Zu idazle
Zientzia aldizkaria

