

Descobridor informàtic de rima per al bertsolarismo
És clar que crear en els escacs una mica com el "Deep Blue" que va guanyar a Kasparov és de moment impossible en el bertsolarismo. És clar que encara no aconseguirem cap bertsolari virtual, no crearem una màquina de bertsos al nivell d'un Andoni Egaña. Però una aplicació que ajudi a fer bertsos, per què no? El descobridor de rima que es presenta en aquest article pretén ser una ajuda per als quals no són tan hàbils en els bertsos, o un suport per als quals estan aprenent a ser bertsolaris en el futur.

I és que des de la creació del primer ordenador, fa uns 40 anys, el desenvolupament de la informàtica ha estat enorme. Avui dia per a treballar en qualsevol àmbit o àrea és gairebé imprescindible una aplicació informàtica o una altra. Així, per què no usar la informàtica en altres àmbits que volem? I per què el bertsolarismo no serà un d'aquests camps? És clar que estem lluny d'aconseguir una virtual Egaña o Amuriza, perquè s'han deixat de costat de moment uns objectius massa ambiciosos per a crear màquines pensadores o similars que han somiat des de la creació de la informàtica. No obstant això, ja no serem capaços de complir uns objectius més senzills? Aquest descobridor informàtic de rima, nascut de la idea de realitzar una aplicació general que pogués ajudar al bertsolarista, no vol més que ser una aplicació auxiliar per a trobar rimes.
Però abans d'entrar en explicacions més profundes, situem el nostre treball en el camp de la informàtica en qüestió, concretament en la intel·ligència artificial, més concretament en l'enginyeria lingüística, i analitzem l'evolució d'aquest camp, amb l'objectiu de la màquina pensadora des del seu naixement fins a l'actualitat.
Màquina pensadora: aquella barbaritat!
Aquest era l'objectiu de la intel·ligència artificial (hauríem de dir somni), des que en la dècada dels 50 es va batejar amb aquestes paraules aquest camp de la informàtica. Crear una màquina intel·ligent que pogués pensar.
No obstant això, després de diversos fracassos soferts en la dècada dels 60, en la dècada dels 70 es va produir una espècie de desil·lusió, acompanyada d'una humilitat d'objectius. La senzillesa dels objectius va propiciar la creació dels primers grans prototips de sistemes "intel·ligents" capaços de donar respostes en temes concrets i limitats. Així, per exemple, MYCIN (Shortliffe, 1976), "sistema intel·ligent" que realitzava el tractament i diagnòstic de malalties infeccioses, o PROSPECTOR (Dubtes i uns altres, 1976), seleccionava els llocs adequats per a realitzar exploracions geològiques.
L'èxit d'aquests primers prototips va portar amb si la implicació del món empresarial, amb la consolidació i desenvolupament de la intel·ligència artificial en els anys 80 i 90. Així, la intel·ligència artificial ha arribat a ser una de les línies de recerca més importants dins de la informàtica.
El processament del llenguatge natural (LNP), o l'enginyeria lingüística, si es desitja, és un camp específic que se situa en l'àmbit de la intel·ligència artificial. Entre els resultats d'aquest camp que analitza el tractament automàtic del llenguatge es troben les següents aplicacions informàtiques: correctors ortogràfics, sintàctics, traductors automàtics, sistemes de reconeixement de veu, etc. Per a aconseguir-los cal tenir en compte que cada llengua té les seves peculiaritats. Per tant, encara que el procés sigui similar per a totes les llengües, ha d'ajustar-se a cadascuna d'elles.
Però abans d'explicar el fons d'aquest projecte, explicarem què és el que ens ha portat a dur a terme aquest treball, quins han estat les motivacions i objectius que hem tingut en compte a l'hora de fer aquest treball.
Motivacions i objectius: complicacions segures
No cal dir que tresor és el bertsolarismo. Són pocs els països que sostenen aquest tipus d'expressions orals. I aquest tipus de versos (veure figura 1) reflecteixen l'essència i riquesa del bertsolarismo espontani.
No obstant això, moltes vegades no ens adonem de la dificultat de fer un bertso. I és que, com des del naixement pot ser important tenir o ser un bertsolari, el procés d'aprenentatge pot ser més important. No et perdis com han sortit d'una escola de bertsos tots els bertsolaris actuals. Melodies, mesures, rimes… No hi ha éssers que hagin nascut sabent tot això. Sabem bé que nosaltres, els afeccionats, hem volgut i no hem pogut.
Comencem a treballar amb aquests pensaments al cap. El bertsolarismo, les escoles de bertsolaris, com aprendre a fer bertsos, com ensenyar-los… I en la memòria de tots ells, traiem la idea de fer una aplicació completa per a ajudar als bertsolaris principiants, o als bertsolaris en general. La idea inicial va ser fer una aplicació per a controlar les mesures, donar a conèixer les melodies, tenir una biblioteca de bertsos antics i nous, trobar rimes… Però calia començar per algun lloc. I per a decidir per on començar, als afeccionats, se'ns va ocórrer que era bo començar pel que més ens costa. I què se'ns fa més difícil que trobar rimes adequades per a un bertso?
Teníem l'objectiu marcat. Volíem fer un descobridor informàtic de rima. Una aplicació que ens donaria un final de paraula i ens donaria totes les formes en basca que coincidien amb aquest final. Però com aconseguir amb un final de paraula totes les paraules basques amb aquest final? I quan diem tots, a més de totes les paraules que apareixen en els diccionaris, parlem de paraules derivades i declinades, de verbs compactes i jugats… Com aconseguir-les?
La inversió en basca: aquesta és la mescla!
Primer de tot, vegem en què ens hem basat a l'hora de fer aquest treball, perquè no partim de zero.
El grup IXA ( www.ixa.si.ehu.es ) té digitalitzada la descripció morfofónica del basc (Agirre eta beste batzuk, 91) K. Segons el model de morfologia a dos nivells de Koskenniemi (Koskenniemi, 83). En aquesta descripció morf-fonològica del grup IXA, cada entrada és un morfema basc. Els morfemes, per part seva, estan dividits en diversos grups i cadascun té definit el llistat de grups d'entrades que pot seguir. En altres paraules, es guarda quins morfemes poden seguir a cada morfema.
Si s'analitza l'exemple de la figura 2, s'observa que els adjectius poden seguir al conjunt la declinació i el grau, i que al mateix temps, la declinació pot seguir-se pel conjunt grau.
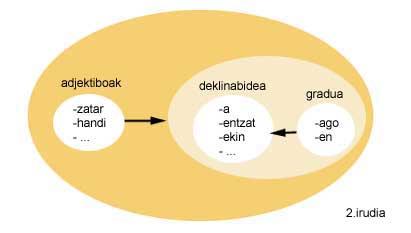
Aquesta descripció morfològica del basc és la base de l'analitzador-creador morfològic per al basc. Aquest analitzador-creador morfològic, d'una banda, realitza una anàlisi morfològica de les paraules (veure exemple) i, d'altra banda, mitjançant una introducció al lèxic, obté totes les paraules que poden sorgir a partir d'aquesta entrada al lèxic (veure exemple).
desgraciadament
("desgraciadament" ADB) ("desgraciadament" IZE +DEK INS MG) ("desgraciadament" IZE + DEK INS NUMP MUGM)
gos
gos al gos amb gos
El que necessitem és, no obstant això, un creador morfològic que, partint d'un final de paraula, realitzaria una creació inversa (veure exemple).
més informació
estic més petit… ...
Per a això és necessari invertir d'alguna manera la descripció morfològica del basc, en lloc de definir els grups d'entrades que poden anar per darrere d'un conjunt d'entrades, per a definir els que poden anar per davant. En altres paraules, es tracta d'aconseguir una sèrie de morfemes que poden anar per davant de cada morfema.
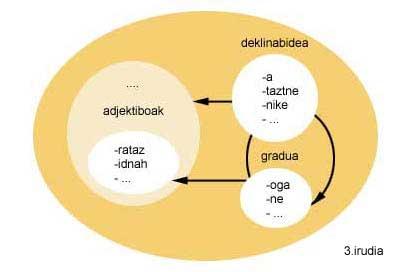
Seguint amb l'exemple de la figura 2, una vegada invertida aquesta descripció morfològica, la descripció morfològica que s'obtindria hauria d'indicar que les entrades del grup grau o adjectius poden anar per davant de les entrades del grup declinació, i les del grup grau per davant de les entrades del grup.
Per a aconseguir-ho cal tenir en compte com funciona el creador morfològic. El creador morfològic només pot realitzar un encadenat cap endavant dels conjunts d'entrada, ja que crea les paraules segons l'ordre que li indica la descripció morfològica. Per tant, no pot fer cadenes cap endarrere. I atès que la creació parteix d'un final de paraula, per a invertir la descripció morfològica, a més d'indicar quin morfema va després del morfemo, els morfemes hauran d'invertir-se un a un (veure figura 3) i, per tant, el final de paraula que inicia la creació. Així doncs, s'obtindran totes les paraules que coincideixin amb aquest final de paraula, però a l'inrevés. En aquest sentit, serà necessari realitzar una última inversió per a presentar les paraules correctament a l'usuari. Tot el procés com a final de paraula ' ekin'.
No obstant això, hi ha un altre aspecte que, per no haver-lo esmentat fins ara, ha quedat palès amb l'exemple que hem utilitzat, el dels canvis morfofónicos. En el cas de la descripció morfològica retrospectiva abans del basc, en la creació iniciada amb el terme 'zatar' s'obtindrien formes com 'zatara', 'zataren' o 'zatarago', en lloc de 'zatarra', 'zatarren', 'zatarrago' o 'zatarrena'. Precisament per a induir aquests canvis morf-fonològics, en la descripció morfofónica del basc es defineixen regles de 2 nivells (d'aquí el seu nom a aquest model). Així, quan una paraula que acaba amb el caràcter 'r' segueixi una forma que comença per vocal, caldrà definir una regla que converteixi a 'r' tou en duro:
r + vocal -- rr + vocal
Per al creador morfològic alternatiu és necessari "invertir" aquestes regles, ja que tots els morfemes estan invertits i les unions entre morfemes també estan invertides. Per tant, la nova regla, per a aconseguir un 'r' dur, haurà d'exigir que el context de l'esquerra tingui la vocal i el de la dreta el caràcter 'r':
vocal + r -- vocal + rr
Seguint amb l'exemple anterior, en unir 'a' i 'rataz' (inversa de 'zatar') amb aquesta regla s'obtindria 'arrataz'. El mateix s'ha fet amb la resta de les regles morfofonològiques.
Cal no oblidar que tot això s'ha fet de manera automàtica, ja que la inversió manual de totes les regles i de totes les entrades del lèxic d'una en una podia ser una tasca enorme.
Per tant, invertint així la descripció morfològica del basc, s'ha aconseguit el creador morfològic contraposat al basc, amb un final de paraula que dóna totes les paraules coincidents amb aquesta fi. Aquesta característica, que sembla un avantatge de l'aplicació, és a dir, la de donar totes les paraules, també serà l'origen dels maldecaps, ja que la llista de paraules que es genera amb certs terminos de paraules és massa gran.
Per exemple, amb el final de la paraula 'ena', el nombre de paraules que es creen és enorme, a més de paraules senzilles ('pena', 'antena'...), paraules derivades i declinades ('major', 'menor', 'més bella'... 'etxena', 'mutilena', 'amarena' …), o bé perquè són molts els verbs conjugats ('qui té', 'qui els tenia', 'els que érem'...). Per això, s'han hagut de prendre mesures per a trencar d'alguna manera l'excés de creació o, almenys, per a explicar primer les paraules que més li interessarien al bertsolari.
La riquesa del basc ens ha portat dificultats
Començant per l'estudi de les peculiaritats del basc, es pot observar que el basc té unes característiques específiques que expliquen la riquesa que poden tenir les paraules basques al final.
En primer lloc, el llenguatge és pegante, és a dir, després d'un morfema poden anar altre o uns altres. D'altra banda, la riquesa del verb també és evident, ja que són moltes les formes que pot adoptar cada verb. I a més, els seus catorze casos de declinació en flexió donen compte de les diferents formes que una paraula pot admetre al final.
Precisament per aquesta riquesa que poden tenir les paraules basques al final, s'han posat de manifest els problemes que pot tenir l'aplicació, segons el final de paraula que dóna l'usuari, ja que les formes basques que coincideixen amb aquest final poden ser milers. Què s'ha fet per a solucionar aquest problema? Es plantegen dues millores principals.
Una, agrupar les paraules traduïdes per l'aplicació per categories. Seguint amb l'exemple anteriorment utilitzat, en lloc d'explicar 'el més gran', 'el més petit', 'el més bell', es podria donar un exemple i una explicació de la següent manera:
major
GRAD + a(NOMIN)o
major (ADJ) + en(GENPL) + a(NOMIN)
Quedaria clar que en afegir en+a tots els adjectius s'obtindrien paraules que farien rima amb ena, tant aplicant la categoria de grau com aplicant el genitiu plural.
Una altra categorització de la mateixa rima seria:
amb
du(hissen-ADI) + en(ERL) + a(NOMIN)No obstant això, les paraules que es troben fora d'aquestes categoritzacions -les paraules compactades- haurien de mostrar-se totes, ja que per a elles no existeixen criteris d'agrupació: 'pena', 'antena', ...
L'altra millora ve en la mateixa línia. Atès que el bertsolari no aprecia per igual unes rimes o unes altres, la segona millora que s'ha plantejat consisteix en el fet que unes formes s'exposin abans que unes altres. Per això, s'ha optat per anteposar les paraules o formes més benvolgudes en el bertsolarismo a les menys benvolgudes. I creiem que, almenys des del punt de vista estilístic, s'aprecien més les paraules compactes ('pena', 'antena'...) que les paraules derivades ('major','menor'...), encara que, en general, estigui bé vist l'ús de paraules derivades, tret que en un mateix vers s'utilitzin més d'una rima de la mateixa categoria (Amuriza, 81). No obstant això, a l'hora de presentar les paraules, hem decidit primer donar paraules compactes i després paraules derivades.
Una o dues millores no són massa
Aquesta aplicació admetria, com no podia ser d'una altra manera, millores i treballs complementaris en línia amb les motivacions i idees que teníem en començar amb aquest treball.
La primera millora consisteix en la capacitat de l'aplicació de mostrar les rimes per temes. En altres paraules, s'oferiria a l'usuari la possibilitat de buscar paraules rimades d'una categoria semàntica, és a dir, l'aplicació mostraria totes les paraules que coincideixin amb la paraula i el tema triats per l'usuari.
La segona millora seria presentar també les rimes assonants o les paraules que permeten les lleis de les famílies de consonants. Si el final fos '-dos', per exemple, a l'hora de demanar totes les paraules que facin rima amb aquest final, és possible presentar paraules amb els terminos 'dos', 'vaig donar', 'gi', 'ri' a petició de l'usuari.
La tercera millora consistiria a crear una interfície web per a l'aplicació i publicar-la en Internet, de manera que l'aplicació estigui disponible per a qualsevol. Al costat d'això, no estaria mal millorar la rapidesa de l'aplicació –temps de resposta–.
I finalment, més que com a millora, el que cal plantejar com a objectiu general és crear un suport per al qual està aprenent bertsos, a més de rimes, per a mesures, melodies, etc., un professor virtual de bertsos que ofereixi ajuda.
Com a conclusió, podríem dir que aquesta aplicació seria un treball a situar dins d'una altra aplicació més gran. No obstant això, si aquest apartat funciona pel seu compte i quan es realitzin algunes millores, es publicarà en la xarxa Internet aquest descobridor informàtic de rima per al seu ús públic.
En un futur pròxim, per tant, aquest descobridor informàtic de rima pretén ser un suport per a qualsevol afeccionat al bertsolarismo, a fi que ningú quedi sense rima a l'hora de fer algun bertso paper. O que serveixi com a mínim per a trobar títols blancs rimats a aquesta mena d'articles.
Zu idazle
Zientzia aldizkaria

