

Descubridor informático de rima para el bertsolarismo
Está claro que crear en el ajedrez algo como el "Deep Blue" que ganó a Kasparov es por el momento imposible en el bertsolarismo. Está claro que todavía no vamos a conseguir ningún bertsolari virtual, no vamos a crear una máquina de bertsos al nivel de un Andoni Egaña. Pero una aplicación que ayude a hacer bertsos, ¿por qué no? El descubridor de rima que se presenta en este artículo pretende ser una ayuda para los que no son tan hábiles en los bertsos, o un soporte para los que están aprendiendo a ser bertsolaris en el futuro.

Y es que desde la creación del primer ordenador, hace unos 40 años, el desarrollo de la informática ha sido enorme. Hoy en día para trabajar en cualquier ámbito o área es casi imprescindible una aplicación informática u otra. Así, ¿por qué no usar la informática en otros ámbitos que queremos? ¿Y por qué el bertsolarismo no será uno de esos campos? Está claro que estamos lejos de conseguir una virtual Egaña o Amuriza, porque se han dejado de lado por el momento unos objetivos demasiado ambiciosos para crear máquinas pensadoras o similares que han soñado desde la creación de la informática. Sin embargo, ¿ya no seremos capaces de cumplir unos objetivos más sencillos? Este descubridor informático de rima, nacido de la idea de realizar una aplicación general que pudiera ayudar al bertsolarista, no quiere más que ser una aplicación auxiliar para encontrar rimas.
Pero antes de entrar en explicaciones más profundas, situemos nuestro trabajo en el campo de la informática en cuestión, concretamente en la inteligencia artificial, más concretamente en la ingeniería lingüística, y analicemos la evolución de este campo, con el objetivo de la máquina pensadora desde su nacimiento hasta la actualidad.
Máquina pensadora: ¡aquella barbaridad!
Ese era el objetivo de la inteligencia artificial (deberíamos decir sueño), desde que en la década de los 50 se bautizó con estas palabras este campo de la informática. Crear una máquina inteligente que pudiera pensar.
Sin embargo, tras varios fracasos sufridos en la década de los 60, en la década de los 70 se produjo una especie de desilusión, acompañada de una humildad de objetivos. La sencillez de los objetivos propició la creación de los primeros grandes prototipos de "sistemas inteligentes" capaces de dar respuestas en temas concretos y limitados. Así, por ejemplo, MYCIN (Shortliffe, 1976), "sistema inteligente" que realizaba el tratamiento y diagnóstico de enfermedades infecciosas, o PROSPECTOR (Dudas y otros, 1976), seleccionaba los lugares adecuados para realizar exploraciones geológicas.
El éxito de estos primeros prototipos trajo consigo la implicación del mundo empresarial, con la consolidación y desarrollo de la inteligencia artificial en los años 80 y 90. Así, la inteligencia artificial ha llegado a ser una de las líneas de investigación más importantes dentro de la informática.
El procesamiento del lenguaje natural (LNP), o la ingeniería lingüística, si se desea, es un campo específico que se sitúa en el ámbito de la inteligencia artificial. Entre los resultados de este campo que analiza el tratamiento automático del lenguaje se encuentran las siguientes aplicaciones informáticas: correctores ortográficos, sintácticos, traductores automáticos, sistemas de reconocimiento de voz, etc. Para conseguirlos hay que tener en cuenta que cada lengua tiene sus peculiaridades. Por lo tanto, aunque el proceso sea similar para todas las lenguas, debe ajustarse a cada una de ellas.
Pero antes de explicar el fondo de este proyecto, vamos a contar qué es lo que nos ha llevado a llevar a cabo este trabajo, cuáles han sido las motivaciones y objetivos que hemos tenido en cuenta a la hora de realizar este trabajo.
Motivaciones y objetivos: complicaciones seguras
Ni que decir tiene que tesoro es el bertsolarismo. Son pocos los países que sostienen este tipo de expresiones orales. Y este tipo de versos (ver figura 1) reflejan la esencia y riqueza del bertsolarismo espontáneo.
Sin embargo, muchas veces no nos damos cuenta de la dificultad de hacer un bertso. Y es que, como desde el nacimiento puede ser importante tener o ser un bertsolari, el proceso de aprendizaje puede ser más importante. No te pierdas cómo han salido de una escuela de bertsos todos los bertsolaris actuales. Melodías, medidas, rimas… No hay seres que hayan nacido sabiendo todo eso. Sabemos bien que nosotros, los aficionados, hemos querido y no hemos podido.
Empezamos a trabajar con estos pensamientos en la cabeza. El bertsolarismo, las escuelas de bertsolaris, cómo aprender a hacer bertsos, cómo enseñarlos… Y en la memoria de todos ellos, sacamos la idea de hacer una aplicación completa para ayudar a los bertsolaris principiantes, o a los bertsolaris en general. La idea inicial fue hacer una aplicación para controlar las medidas, dar a conocer las melodías, tener una biblioteca de bertsos antiguos y nuevos, encontrar rimas… Pero había que empezar por algún sitio. Y para decidir por dónde empezar, a los aficionados, se nos ocurrió que era bueno empezar por lo que más nos cuesta. ¿Y qué se nos hace más difícil que encontrar rimas adecuadas para un bertso?
Teníamos el objetivo marcado. Queríamos hacer un descubridor informático de rima. Una aplicación que nos daría un final de palabra y nos daría todas las formas en euskera que coincidían con ese final. Pero ¿cómo conseguir con un final de palabra todas las palabras vascas con ese final? Y cuando decimos todos, además de todas las palabras que aparecen en los diccionarios, hablamos de palabras derivadas y declinadas, de verbos compactos y jugados… ¿Cómo conseguirlas?
La inversión en euskera: ¡esta es la mezcla!
Antes que nada, veamos en qué nos hemos basado a la hora de realizar este trabajo, porque no partimos de cero.
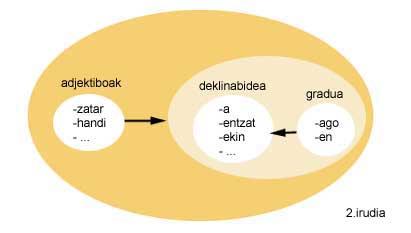
El grupo IXA ( www.ixa.si.ehu.es ) tiene digitalizada la descripción morfofónica del euskera (Agirre eta beste batzuk, 91) K. Según el modelo de morfología a dos niveles de Koskenniemi (Koskenniemi, 83). En esta descripción morfo-fonológica del grupo IXA, cada entrada es un morfema vasco. Los morfemas, por su parte, están divididos en varios grupos y cada uno tiene definido el listado de grupos de entradas que puede seguir. En otras palabras, se guarda qué morfemas pueden seguir a cada morfema.
Si se analiza el ejemplo de la figura 2, se observa que los adjetivos pueden seguir al conjunto la declinación y el grado, y que al mismo tiempo, la declinación puede seguirse por el conjunto grado.
Esta descripción morfológica del euskera es la base del analizador-creador morfológico para el euskera. Este analizador-creador morfológico, por un lado, realiza un análisis morfológico de las palabras (ver ejemplo) y, por otro lado, mediante una introducción al léxico, obtiene todas las palabras que pueden surgir a partir de esta entrada al léxico (ver ejemplo).
desgraciadamente
("desgraciadamente" ADB)
("desgraciadamente" IZE +DEK INS MG)
("desgraciadamente" IZE + DEK INS NUMP MUGM)
perro
perro
al
perro
con
perro
Lo que necesitamos es, sin embargo, un creador morfológico que, partiendo de un final de palabra, realizaría una creación inversa (ver ejemplo).
más información
estoy
más
pequeño…
...
Para ello es necesario invertir de alguna manera la descripción morfológica del euskera, en lugar de definir los grupos de entradas que pueden ir por detrás de un conjunto de entradas, para definir los que pueden ir por delante. En otras palabras, se trata de conseguir una serie de morfemas que pueden ir por delante de cada morfema.
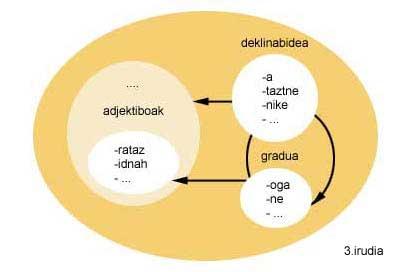
Siguiendo con el ejemplo de la figura 2, una vez invertida esta descripción morfológica, la descripción morfológica que se obtendría debería indicar que las entradas del grupo grado o adjetivos pueden ir por delante de las entradas del grupo declinación, y las del grupo grado por delante de las entradas del grupo.
Para conseguirlo hay que tener en cuenta cómo funciona el creador morfológico. El creador morfológico sólo puede realizar un encadenado hacia delante de los conjuntos de entrada, ya que crea las palabras según el orden que le indica la descripción morfológica. Por lo tanto, no puede hacer cadenas hacia atrás. Y dado que la creación parte de un final de palabra, para invertir la descripción morfológica, además de indicar qué morfema va después del morfemo, los morfemas deberán invertirse uno a uno (ver figura 3) y, por tanto, el final de palabra que inicia la creación. Así pues, se obtendrán todas las palabras que coincidan con ese final de palabra, pero al revés. En este sentido, será necesario realizar una última inversión para presentar las palabras correctamente al usuario. Todo el proceso como final de palabra ' ekin'.
Sin embargo, hay otro aspecto que, por no haberlo mencionado hasta ahora, ha quedado patente con el ejemplo que hemos utilizado, el de los cambios morfofónicos. En el caso de la descripción morfológica retrospectiva antes del euskera, en la creación iniciada con el término 'zatar' se obtendrían formas como 'zatara', 'zataren' o 'zatarago', en lugar de 'zatarra', 'zatarren', 'zatarrago' o 'zatarrena'. Precisamente para inducir estos cambios morfo-fonológicos, en la descripción morfofónica del euskera se definen reglas de 2 niveles (de ahí su nombre a este modelo). Así, cuando una palabra que termina con el carácter 'r' siga una forma que empieza por vocal, habrá que definir una regla que convierta a 'r' blando en duro:
r + vocal -- rr + vocal
Para el creador morfológico alternativo es necesario "invertir" estas reglas, ya que todos los morfemas están invertidos y las uniones entre morfemas también están invertidas. Por lo tanto, la nueva regla, para conseguir un 'r' duro, deberá exigir que el contexto de la izquierda tenga la vocal y el de la derecha el carácter 'r':
vocal + r -- vocal + rr
Siguiendo con el ejemplo anterior, al unir 'a' y 'rataz' (inversa de 'zatar') con esta regla se obtendría 'arrataz'. Lo mismo se ha hecho con el resto de las reglas morfofonológicas.
No hay que olvidar que todo esto se ha hecho de forma automática, ya que la inversión manual de todas las reglas y de todas las entradas del léxico de una en una podía ser una tarea enorme.
Por lo tanto, invirtiendo así la descripción morfológica del euskera, se ha conseguido el creador morfológico contrapuesto al euskera, con un final de palabra que da todas las palabras coincidentes con ese fin. Esta característica, que parece una ventaja de la aplicación, es decir, la de dar todas las palabras, también será el origen de los quebraderos de cabeza, ya que la lista de palabras que se genera con ciertos terminos de palabras es demasiado grande.
Por ejemplo, con el final de la palabra 'ena', el número de palabras que se crean es enorme, además de palabras sencillas ('pena', 'antena'...), palabras derivadas y declinadas ('mayor', 'menor', 'más bella'... 'etxena', 'mutilena', 'amarena' …), o bien porque son muchos los verbos conjugados ('quien tiene', 'quien los tenía', 'los que éramos'...). Por ello, se han tenido que tomar medidas para romper de alguna manera el exceso de creación o, al menos, para explicar primero las palabras que más le interesarían al bertsolari.
La riqueza del euskera nos ha traído dificultades
Comenzando por el estudio de las peculiaridades del euskera, se puede observar que el euskera tiene unas características específicas que explican la riqueza que pueden tener las palabras vascas al final.
En primer lugar, el lenguaje es pegante, es decir, tras un morfema pueden ir otro u otros. Por otra parte, la riqueza del verbo también es evidente, ya que son muchas las formas que puede adoptar cada verbo. Y además, sus catorce casos de declinación en flexión dan cuenta de las diferentes formas que una palabra puede admitir al final.
Precisamente por esa riqueza que pueden tener las palabras vascas al final, se han puesto de manifiesto los problemas que puede tener la aplicación, según el final de palabra que da el usuario, ya que las formas vascas que coinciden con ese final pueden ser miles. ¿Qué se ha hecho para solucionar este problema? Se plantean dos mejoras principales.
Una, agrupar las palabras traducidas por la aplicación por categorías. Siguiendo con el ejemplo anteriormente utilizado, en lugar de explicar 'el más grande', 'el más pequeño', 'el más bello', se podría dar un ejemplo y una explicación de la siguiente manera:
mayor
GRAD + a(NOMIN)o
mayor
(ADJ) + en(GENPL) + a(NOMIN)
Quedaría claro que al añadir en+a todos los adjetivos se obtendrían palabras que harían rima con ena, tanto aplicando la categoría de grado como aplicando el genitivo plural.
Otra categorización de la misma rima sería:
con
du(izan-ADI) + en(ERL) + a(NOMIN)Sin embargo, las palabras que se encuentran fuera de estas categorizaciones -las palabras compactadas- deberían mostrarse todas, ya que para ellas no existen criterios de agrupación: 'pena', 'antena', ...
La otra mejora viene en la misma línea. Dado que el bertsolari no aprecia por igual unas rimas u otras, la segunda mejora que se ha planteado consiste en que unas formas se expongan antes que otras. Por ello, se ha optado por anteponer las palabras o formas más apreciadas en el bertsolarismo a las menos apreciadas. Y creemos que, al menos desde el punto de vista estilístico, se aprecian más las palabras compactas ('pena', 'antena'...) que las palabras derivadas ('mayor','menor'...), aunque, en general, esté bien visto el uso de palabras derivadas, salvo que en un mismo verso se utilicen más de una rima de la misma categoría (Amuriza, 81). No obstante, a la hora de presentar las palabras, hemos decidido primero dar palabras compactas y luego palabras derivadas.
Una o dos mejoras no son demasiadas
Esta aplicación admitiría, como no podía ser de otra manera, mejoras y trabajos complementarios en línea con las motivaciones e ideas que teníamos al comenzar con este trabajo.
La primera mejora consiste en la capacidad de la aplicación de mostrar las rimas por temas. En otras palabras, se ofrecería al usuario la posibilidad de buscar palabras rimadas de una categoría semántica, es decir, la aplicación mostraría todas las palabras que coincidan con la palabra y el tema elegidos por el usuario.
La segunda mejora sería presentar también las rimas asonantes o las palabras que permiten las leyes de las familias de consonantes. Si el final fuera '-dos', por ejemplo, a la hora de pedir todas las palabras que hagan rima con este final, es posible presentar palabras con los terminos 'dos', 'di', 'gi', 'ri' a petición del usuario.
La tercera mejora consistiría en crear una interfaz web para la aplicación y publicarla en Internet, de forma que la aplicación esté disponible para cualquiera. Junto a esto, no estaría mal mejorar la rapidez de la aplicación –tiempo de respuesta–.
Y por último, más que como mejora, lo que hay que plantear como objetivo general es crear un soporte para el que está aprendiendo bertsos, además de rimas, para medidas, melodías, etc., un profesor virtual de bertsos que ofrezca ayuda.
Como conclusión, podríamos decir que esta aplicación sería un trabajo a ubicar dentro de otra aplicación más grande. No obstante, si este apartado funciona por su cuenta y en cuanto se realicen algunas mejoras, se publicará en la red Internet este descubridor informático de rima para su uso público.
En un futuro cercano, por tanto, este descubridor informático de rima pretende ser un soporte para cualquier aficionado al bertsolarismo, a fin de que nadie quede sin rima a la hora de hacer algún bertso papel. O que sirva como mínimo para encontrar títulos blancos rimados a este tipo de artículos.
Zu idazle
Zientzia aldizkaria

