

Rima computer discoverer for bertsolarism
It is clear that creating in chess something like the "Deep Blue" that won Kasparov is at the moment impossible in Bertsolarism. It is clear that we are not yet going to get any virtual bertsolari, we will not create a bertsos machine at the level of an Andoni Egaña. But an application that helps make bertsos, why not? The rima discoverer presented in this article aims to be an aid for those who are not so skilled in the bertsos, or a support for those who are learning to be bertsolaris in the future.

And since the creation of the first computer, about 40 years ago, the development of computing has been enormous. Today to work in any area or area is almost essential one computer application or another. So why not use computing in other areas we want? And why will Bertsolarism not be one of those fields? It is clear that we are far from getting a virtual Egaña or Amuriza, because too ambitious goals have been left aside for the moment to create thinking or similar machines that have dreamed since the creation of computer science. However, will we no longer be able to meet simpler goals? This computer discoverer of rhyme, born of the idea of realizing a general application that could help the bertsolarista, does not want but to be an auxiliary application to find rhymes.
But before entering into deeper explanations, let us situate our work in the field of computer science in question, specifically in artificial intelligence, more specifically in linguistic engineering, and analyze the evolution of this field, with the aim of the thinking machine from its birth to the present.
Thinking machine: that barbarity!
That was the objective of artificial intelligence (we should say dream), since in the 50s this field of computing was baptized with these words. Create a smart machine you could think of.
However, after several failures suffered in the 1960s, in the 1970s a kind of disillusionment occurred, accompanied by a humility of objectives. The simplicity of the objectives led to the creation of the first great prototypes of "intelligent systems" capable of providing answers on specific and limited issues. Thus, for example, MYCIN (Shortliffe, 1976), "intelligent system" that performed the treatment and diagnosis of infectious diseases, or PROSPECTOR (Doubts and others, 1976), selected the appropriate places to perform geological explorations.
The success of these first prototypes brought with it the involvement of the business world, with the consolidation and development of artificial intelligence in the 80s and 90s. Thus, artificial intelligence has become one of the most important lines of research within computing.
Natural language processing (NPL), or linguistic engineering, if desired, is a specific field in the field of artificial intelligence. Among the results of this field that analyzes the automatic treatment of language are the following computer applications: spell checkers, syntactic, automatic translators, voice recognition systems, etc. To get them you have to keep in mind that each language has its peculiarities. Therefore, even if the process is similar for all languages, it must conform to each language.
But before explaining the background of this project, let's tell what has led us to carry out this work, what have been the motivations and objectives that we have taken into account when doing this work.
Motivations and objectives: safe complications
Needless to say, what a treasure is berthsolarism. Few countries support this type of oral expression. And this type of verse (see figure 1) reflects the essence and richness of spontaneous berthsolarism.
However, many times we do not realize the difficulty of making a bertso. And since birth it can be important to have or be a bertsolari, the learning process can be more important. Don't miss how all the current bertsolaris have left a school of bertsos. Melodies, measures, rhymes… There are no beings born knowing all that. We know well that we, the fans, have wanted and have not been able.
We start working with these thoughts on the head. Bertsolarism, bertsolaris schools, how to learn how to make bertsos, how to teach them… And in the memory of all of them, we get the idea of making a complete application to help beginners bertsolaris, or bertsolaris in general. The initial idea was to make an application to control the measures, to make known the melodies, to have a library of old and new bertsos, to find rhymes… But it had to start somewhere. And to decide where to start, the fans, it occurred to us that it was good to start with what costs us the most. And what makes us more difficult than finding rims suitable for a bertso?
We had the goal set. We wanted to make a computer rima discoverer. An application that would give us an end of word and give us all the forms in Basque that coincided with that end. But how to get with a final word all the Basque words with that end? And when we say all, in addition to all the words that appear in the dictionaries, we talk about derived and declined words, compact and played verbs… How to get them?
Investment in Basque: this is the mix!
First of all, let's see what we've based ourselves on when doing this work, because we don't start from scratch.
The IXA group ( www.ixa.si.ehu.es) has digitized the morphophonic description of the Basque language (Agirre eta beste batzuk, 91) K. According to the two-level morphology model of Koskenniemi (Koskenniemi, 83). In this morpho-phonological description of the IXA group, each entry is a Basque morpheme. The morphemes, on the other hand, are divided into several groups and each has defined the list of groups of entries that you can follow. In other words, what morphemes can follow each morpheme is saved.
If the example of Figure 2 is analyzed, it is observed that adjectives can follow the whole decline and degree, and that at the same time, the decline can be followed by the whole degree.
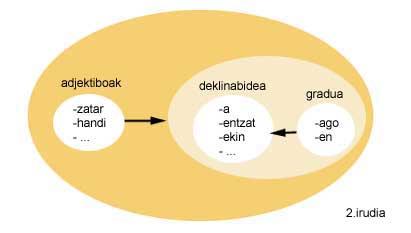
This morphological description of the Basque language is the basis of the morphological analyzer creator for the Basque language. This morphological analyzer creator, on the one hand, performs a morphological analysis of the words (see example) and, on the other hand, by an introduction to the lexicon, obtains all the words that can arise from this entry into the lexicon (see example).
unfortunately
("unfortunately" ADB)
("unfortunately" IZE +DEK INS MG)
("unfortunately" IZE + DEK INS NUMP MUGM)
dog
dog
to
dog
with
dog
What we need is, however, a morphological creator who, starting from a final word, would make a reverse creation (see example).
more information
I
am
smaller…
..
To do this, it is necessary to invert in some way the morphological description of Basque, instead of defining the groups of entries that can go behind a set of entries, to define those that can go ahead. In other words, it is about getting a series of morphemes that can go ahead of each morpheme.
Following the example of Figure 2, once this morphological description has been inverted, the morphological description to be obtained should indicate that the entries of the grade group or adjectives can go ahead of the entries of the declination group, and those of the grade group ahead of the group entries.
To achieve this, consider how the morphological creator works. The morphological creator can only perform a chained forward of the input sets, as he creates the words according to the order indicated by the morphological description. Therefore, you cannot make chains back. And since the creation starts from an end of the word, to reverse the morphological description, in addition to indicating what morpheme goes after the morpheme, the morphemes must be inverted one by one (see figure 3) and, therefore, the end of the word that begins the creation. So, you will get all the words that match that end of word, but vice versa. In this sense, it will be necessary to make a last investment to present the words correctly to the user. The whole process as a final word ' ekin'.
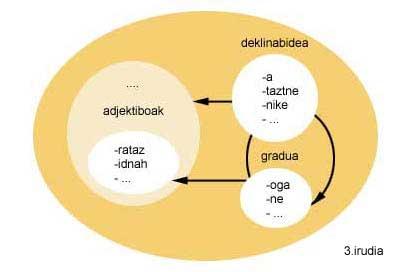
However, there is another aspect that, if not mentioned so far, has become clear with the example we have used, that of morphophonic changes. In the case of the retrospective morphological description before the Basque language, in the creation initiated with the term 'zatar' forms would be obtained as 'zatara', 'zataren' or 'zatarago', instead of 'zatarra', 'zatarren', 'zatarrago' or 'zatarrena'. Precisely to induce these morpho-phonological changes, the morphophonic description of the Basque language defines rules of 2 levels (hence its name to this model). Thus, when a word that ends with the 'r' character follows a form that starts with a vowel, a rule must be defined that turns soft 'r' into hard:
r + vocal -- rr + vocal
For the alternative morphological creator it is necessary to "reverse" these rules, since all morphemes are inverted and the bonds between morphemes are also inverted. Therefore, the new rule, in order to achieve a hard 'r', must require that the context of the left have the vowel and that of the right the character 'r':
vocal + r -- vocal + rr
Following the example above, joining 'a' and 'rataz' (inverse of 'zatar') with this rule would obtain 'arrataz'. The same has been done with the rest of the morphophonological rules.
It should not be forgotten that all this has been done automatically, since the manual reversal of all the rules and all the lexical entries one by one could be a huge task.
Therefore, reversing the morphological description of the Basque language, the morphological creator counterposed to the Basque language has been achieved, with an end of word that gives all the words matched to that end. This feature, which seems to be an advantage of the application, that is, to give all words, will also be the origin of headaches, since the list of words that is generated with certain word terms is too large.
For example, with the end of the word 'ena', the number of words created is enormous, in addition to simple words ('penalty', 'antenna'...), derived and declined words ('greater', 'lesser', 'more beautiful'... 'etxena', 'mutilena', 'amarena' …), or because there are many conjugated verbs ('who has', 'who had them', 'who we were'...). Therefore, measures have had to be taken to somehow break the excess of creation or, at least, to explain first the words that most interest bertsolari.
The wealth of Basque has brought us difficulties
Starting with the study of the peculiarities of Basque, we can observe that Basque has specific characteristics that explain the richness that Basque words can have at the end.
First, the language is sticky, that is, after a morpheme other or others can go. On the other hand, the richness of the verb is also evident, since there are many forms that each verb can adopt. And in addition, its fourteen cases of bending decline account for the different forms a word can admit in the end.
Precisely because of the richness that the Basque words can have at the end, the problems that the application can have have have, according to the end of the word that the user gives, since the Basque forms that coincide with that end can be thousands. What has been done to solve this problem? Two main improvements are proposed.
One, group the words translated by the application by categories. Following the example used above, instead of explaining 'the largest', 'the smallest', 'the most beautiful', you could give an example and an explanation as follows:
higher
GRAD + a(NOMIN)or
greater
(ADJ) + in(GENPL) + a(NOMIN)
It would be clear that adding in+a all adjectives would produce words that would rhyme with ena, both applying the grade category and applying the plural genitive.
Another categorization of the same rhyme would be:
with
du(izan-ADI) + en(ERL) + a(NOMIN)However, the words outside these categorizations - compacted words - should be shown all, since for them there are no grouping criteria: 'penalty', 'antenna', ..
The other improvement comes in the same line. Since bertsolari does not like rhymes or others, the second improvement that has been raised is that some forms are exposed before others. Therefore, it has been chosen to put the most appreciated words or forms in Bertsolarism before the least appreciated. And we believe that, at least from the stylistic point of view, the compact words ('penalty', 'antenna'...) are more appreciated than the derived words ('greater', 'lesser'...), although, in general, the use of derived words is well seen, unless in the same verse more than one rhyme of the same category is used (Amuriza, 81). However, when presenting the words, we decided first to give compact words and then derivative words.
One or two improvements are not too many
This application would admit, as it could not be otherwise, improvements and complementary works in line with the motivations and ideas we had when we started this work.
The first improvement is the ability of the application to show rhymes by themes. In other words, the user would be offered the possibility to search for rhymed words of a semantic category, that is, the application would show all the words that match the word and theme chosen by the user.
The second improvement would also be to present the consonant rhymes or words that allow the laws of consonant families. If the end is '-two', for example, when asking for all the words that rhyme with this end, it is possible to present words with the terms 'two', 'di', 'gi', 'ri' at the user's request.
The third improvement would be to create a web interface for the application and publish it on the Internet, so that the application is available to anyone. Along with this, it would not be wrong to improve the speed of the application – response time.
And finally, more than improving, what needs to be proposed as a general objective is to create a support for the one who is learning bertsos, in addition to rhymes, for measures, melodies, etc., a virtual teacher of bertsos that offers help.
In conclusion, we could say that this application would be a job to place within another larger application. However, if this section works on your own and as soon as some improvements are made, this computer rima discoverer will be published on the Internet for public use.
In the near future, therefore, this computer discoverer of rhyme aims to be a support for any fan of bertsolarism, so that no one is left without rhyme when making some bertso paper. Or it serves as a minimum to find ripped white titles to these types of articles.
Zu idazle
Zientzia aldizkaria

