

Découvreur informatique de rime pour le bertsolarisme
Il est clair que créer aux échecs quelque chose comme le "Deep Blue" qui a gagné Kasparov est pour le moment impossible dans le bertsolarisme. Il est clair que nous n'obtiendrons pas encore un bertsolari virtuel, nous ne créerons pas une machine de berthsos au niveau d'un Andoni Egaña. Mais une application qui aide à faire des berthos, pourquoi pas? Le découvreur de rime présenté dans cet article prétend être une aide pour ceux qui ne sont pas si habiles dans les Bertsos, ou un support pour ceux qui apprennent à être bertsolaris à l'avenir.

Et c'est que depuis la création du premier ordinateur, il y a environ 40 ans, le développement de l'informatique a été énorme. Aujourd'hui, pour travailler dans n'importe quel domaine ou domaine est presque indispensable une application informatique ou autre. Alors, pourquoi ne pas utiliser l'informatique dans d'autres domaines que nous voulons? Et pourquoi le bertsolarisme ne sera-t-il pas un de ces camps ? Il est clair que nous sommes loin d'obtenir une virtuelle Egaña ou Amuriza, parce qu'ils ont laissé de côté pour le moment des objectifs trop ambitieux pour créer des machines penseuses ou similaires qu'ils ont rêvé depuis la création de l'informatique. Cependant, ne serons-nous plus en mesure d'atteindre des objectifs plus simples? Ce découvreur informatique de rima, né de l'idée de réaliser une application générale qui pourrait aider le bertsolariste, ne veut qu'être une application auxiliaire pour trouver des rimes.
Mais avant d'entrer dans des explications plus profondes, situons notre travail dans le domaine de l'informatique en question, concrètement dans l'intelligence artificielle, plus concrètement dans l'ingénierie linguistique, et analysons l'évolution de ce domaine, avec l'objectif de la machine penseuse depuis sa naissance jusqu'à nos jours.
Machine à penser: Cette barbarie !
C'était le but de l'intelligence artificielle (nous devrions dire rêve), depuis que dans les années 50 ce domaine de l'informatique a été baptisé avec ces mots. Créer une machine intelligente que vous pourriez penser.
Cependant, après plusieurs échecs subis dans les années 1960, une sorte de désillusion s'est produite dans les années 1970, accompagnée d'une humilité d'objectifs. La simplicité des objectifs a favorisé la création des premiers grands prototypes de "systèmes intelligents" capables de donner des réponses sur des sujets concrets et limités. Ainsi, par exemple, MYCIN (Shortliffe, 1976), "système intelligent" qui effectuait le traitement et le diagnostic des maladies infectieuses, ou PROSPECTOR (Doutes et autres, 1976), sélectionnait les endroits appropriés pour réaliser des explorations géologiques.
Le succès de ces premiers prototypes a entraîné l'implication du monde des affaires, avec la consolidation et le développement de l'intelligence artificielle dans les années 80 et 90. Ainsi, l'intelligence artificielle est devenue l'une des plus importantes lignes de recherche dans l'informatique.
Le traitement du langage naturel (LNP), ou l'ingénierie linguistique, si on le souhaite, est un domaine spécifique qui se situe dans le domaine de l'intelligence artificielle. Parmi les résultats de ce domaine qui analyse le traitement automatique du langage se trouvent les applications informatiques suivantes: correcteurs orthographiques, syntaxiques, traducteurs automatiques, systèmes de reconnaissance vocale, etc. Pour les obtenir, il faut garder à l'esprit que chaque langue a ses particularités. Par conséquent, même si le processus est similaire pour toutes les langues, il doit être adapté à chacune d'elles.
Mais avant d'expliquer le fond de ce projet, nous allons raconter ce qui nous a conduit à réaliser ce travail, quelles ont été les motivations et les objectifs que nous avons pris en compte lors de la réalisation de ce travail.
Motivations et objectifs : des complications sûres
Inutile de dire que le trésor est le bertsolarisme. Peu de pays soutiennent ce type d'expressions orales. Et ce genre de versets (voir figure 1) reflètent l'essence et la richesse du bertsolarisme spontané.
Cependant, souvent, nous ne réalisons pas la difficulté de faire un bertso. Et c'est que, comme depuis la naissance peut être important d'avoir ou être un bertsolari, le processus d'apprentissage peut être plus important. Ne manquez pas comment tous les bertsolaris actuels sont sortis d'une école de berthsos. Mélodies, mesures, rimes… Il n'y a pas d'êtres qui sont nés sachant tout cela. Nous savons bien que nous, les amateurs, avons voulu et nous n'avons pas pu.
Nous avons commencé à travailler avec ces pensées dans la tête. Le bertsolarisme, les écoles de bertsolaris, comment apprendre à faire des bertsos, comment les enseigner… Et dans la mémoire de tous, nous tirons l'idée de faire une application complète pour aider les bertsolaris débutants, ou les bertsolaris en général. L'idée initiale était de faire une application pour contrôler les mesures, faire connaître les mélodies, avoir une bibliothèque de berthos anciens et nouveaux, trouver des rimes… Mais il fallait commencer quelque part. Et pour décider par où commencer, les fans, il nous est arrivé qu'il était bon de commencer par ce qui nous coûte le plus. Et qu'est-ce qui nous rend plus difficile que de trouver des rimes appropriés pour un bertso?
Nous avions l'objectif marqué. Nous voulions faire un découvreur informatique de rime. Une application qui nous donnerait une fin de mot et nous donnerait toutes les formes en basque qui coïncidaient avec cette fin. Mais comment obtenir avec une fin de mot tous les mots basques avec cette fin? Et quand nous disons tous, en plus de tous les mots qui apparaissent dans les dictionnaires, nous parlons de mots dérivés et déclinés, de verbes compacts et joués… Comment les obtenir ?
L'investissement en basque : C'est le mélange !
Tout d'abord, voyons ce que nous nous sommes fondés sur la réalisation de ce travail, parce que nous ne partons pas de zéro.
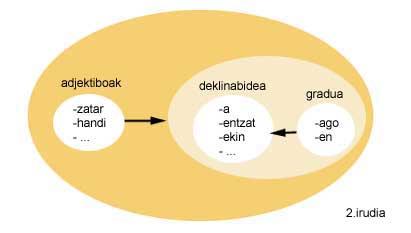
Le groupe IXA ( www.ixa.si.ehu.es ) a numérisé la description morphophonique de l'euskera (Agirre eta beste batzuk, 91) K. Selon le modèle de morphologie à deux niveaux de Koskenniemi (Koskenniemi, 83). Dans cette description morpho-phonologique du groupe IXA, chaque entrée est un morphème basque. Les morphèmes, quant à eux, sont divisés en plusieurs groupes et chacun a défini la liste des groupes d'entrées qu'il peut suivre. En d'autres termes, les morphèmes peuvent suivre chaque morphème.
Si on analyse l'exemple de la figure 2, on observe que les adjectifs peuvent suivre à l'ensemble le déclin et le degré, et qu'en même temps le déclin peut être suivi par l'ensemble degré.
Cette description morphologique d'euskera est la base de l'analyseur morphologique créateur pour l'euskera. Cet analyseur morphologique, d'une part, réalise une analyse morphologique des mots (voir exemple) et, d'autre part, par une introduction au lexique, obtient tous les mots qui peuvent surgir de cette entrée au lexique (voir exemple).
malheureusement
("malheureusement" ADB)
("malheureusement" IZE +DEK INS MG)
("malheureusement" IZE + DEK INS NUMP MUGM)
chien chien de chien
chien
de
chien
avec
chien
Ce dont nous avons besoin est, cependant, un créateur morphologique qui, à partir d'une fin de mot, réaliserait une création inverse (voir exemple).
plus d’informations
je
suis plus
petit…
...
Pour cela, il est nécessaire d'investir en quelque sorte la description morphologique du basque, au lieu de définir les groupes d'entrées qui peuvent aller derrière un ensemble de billets, pour définir ceux qui peuvent aller de l'avant. En d'autres termes, il s'agit d'obtenir une série de morphèmes qui peuvent aller avant chaque morphème.
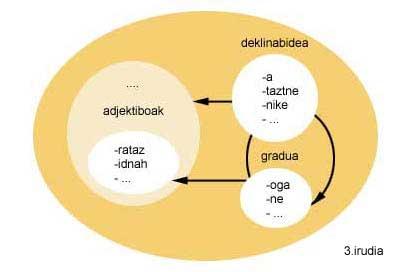
En suivant l'exemple de la figure 2, une fois cette description morphologique inversée, la description morphologique que l'on obtiendrait devrait indiquer que les entrées du groupe degré ou adjectifs peuvent aller devant les entrées du groupe déclin, et celles du groupe degré devant les entrées du groupe.
Pour y parvenir, il faut tenir compte du fonctionnement du créateur morphologique. Le créateur morphologique ne peut réaliser qu'un enchaînement avant les ensembles d'entrée, car il crée les mots selon l'ordre que lui indique la description morphologique. Par conséquent, vous ne pouvez pas faire de chaînes en arrière. Et puisque la création part d'une fin de mot, pour inverser la description morphologique, en plus d'indiquer quel morphème va après le morphème, les morphèmes doivent être inversés un par un (voir figure 3) et donc la fin de mot qui commence la création. Ainsi, vous obtiendrez tous les mots qui correspondent à cette fin de mot, mais à l'inverse. En ce sens, il sera nécessaire de réaliser un dernier investissement pour présenter les mots correctement à l'utilisateur. Tout le processus comme fin de mot ' ekin'.
Cependant, il y a un autre aspect qui, sans l'avoir mentionné jusqu'ici, est devenu évident avec l'exemple que nous avons utilisé, celui des changements morphophoniques. Dans le cas de la description morphologique rétrospective avant l'euskera, dans la création commencée avec le terme 'zatar' on obtiendrait des formes comme 'zatara', 'zataren' ou 'zatarago', au lieu de 'zatarra', 'zatarren', 'zatarrago' ou 'zatarrena'. Précisément pour induire ces changements morpho-phonologiques, la description morphophonique de l'euskera définit des règles à 2 niveaux (d'où son nom à ce modèle). Ainsi, lorsqu'un mot se terminant par le caractère 'r' suit une forme commençant par vocal, il faudra définir une règle qui transforme 'r' en dur :
r + vocal -- rr + vocal
Pour le créateur morphologique alternatif, il faut "inverser" ces règles, car tous les morphèmes sont inversés et les unions entre morphèmes sont également inversées. Par conséquent, la nouvelle règle, pour obtenir un 'r' dur, devra exiger que le contexte de gauche ait la voyelle et celle de droite le caractère 'r':
vocal + r -- vocal + rr
En suivant l'exemple ci-dessus, en joignant 'a' et 'rataz' (inverse de 'zatar') avec cette règle, vous obtiendrez 'arrataz'. La même chose a été faite avec le reste des règles morphophophonologiques.
Il ne faut pas oublier que tout cela a été fait automatiquement, puisque l'investissement manuel de toutes les règles et de toutes les entrées du lexique d'une en une pouvait être une tâche énorme.
Par conséquent, en inversant ainsi la description morphologique de l'euskera, on a obtenu le créateur morphologique opposé à l'euskera, avec une fin de mot qui donne toutes les paroles correspondantes à cette fin. Cette fonctionnalité, qui ressemble à un avantage de l'application, à savoir celui de donner tous les mots, sera également à l'origine des casse-tête, car la liste de mots qui est généré avec certains termes est trop grand.
Par exemple, avec la fin du mot 'ena', le nombre de mots créés est énorme, en plus des mots simples ('pena', 'antena'...), des mots dérivés et déclinés ('mayor', 'menor', 'más bella'... 'etxena', 'mutilena', 'amarena' …), ou parce que nombreux sont les verbes conjugués ('qui a', 'qui les avait', 'qui nous étions'...). C'est pourquoi il a fallu prendre des mesures pour briser en quelque sorte l'excès de création ou, au moins, pour expliquer d'abord les mots qui intéressent le plus le bertsolari.
La richesse du basque nous a apporté des difficultés
En commençant par l'étude des particularités de l'euskera, on peut observer que l'euskera a des caractéristiques spécifiques qui expliquent la richesse que peuvent avoir les mots basques à la fin.
Tout d'abord, le langage est collant, c'est à dire, après un morphème peut aller un autre ou d'autres. D'autre part, la richesse du verbe est également évident, car il ya beaucoup de formes que chaque verbe peut adopter. En outre, ses quatorze cas de déclin en flexion rendent compte des différentes formes qu'un mot peut admettre à la fin.
Précisément à cause de cette richesse que peuvent avoir les mots basques à la fin, ont été mis en évidence les problèmes que peut avoir l'application, selon la fin du mot donné par l'utilisateur, puisque les formes basques qui coïncident avec cette fin peuvent être des milliers. Qu'est-ce qui a été fait pour résoudre ce problème? Deux améliorations majeures sont proposées.
Une, regrouper les mots traduits par l'application par catégories. En suivant l'exemple ci-dessus utilisé, au lieu d'expliquer 'le plus grand', 'le plus petit', 'le plus beau', on pourrait donner un exemple et une explication comme suit:
plus grande, plus grande, plus grande
GRAD + a(NOMIN)ou non,
majeur
(ADJ) + en(GENPL) + a(NOMIN)
Il serait clair qu'en ajoutant à + tous les adjectifs on obtiendrait des mots qui rendraient rime avec ena, tant en appliquant la catégorie de degré qu'en appliquant le génitif pluriel.
Une autre catégorisation de la même rime serait:
avec l'aide de
du(izan-ADI) + dans(ERL) + a(NOMIN)Cependant, les mots qui se trouvent en dehors de ces catégorisations - les mots compacts - devraient tous être affichés, car pour elles il n'y a pas de critères de regroupement: 'peine', 'antenne', ...
L'autre amélioration vient sur la même ligne. Puisque le bertsolari n'apprécie pas pareillement les rimes ou les autres, la deuxième amélioration qui s'est posée consiste en ce que certaines formes soient exposées avant d'autres. C'est pourquoi on a choisi de mettre en avant les mots ou formes les plus appréciés dans le bertsolarisme aux moins appréciées. Et nous croyons qu'au moins du point de vue stylistique, on apprécie davantage les mots compacts ('peine', 'antena'...) que les mots dérivés ('majeur','mineur'...), bien qu'en général l'utilisation de mots dérivés soit bien vue, sauf que dans un même verset on utilise plus d'une rime de la même catégorie (Amuriza, 81). Cependant, lors de la présentation des mots, nous avons décidé d'abord de donner des mots compacts, puis des mots dérivés.
Une ou deux améliorations ne sont pas trop
Cette application admettrait, comme il ne pouvait en être autrement, des améliorations et des travaux complémentaires en ligne avec les motivations et les idées que nous avions au début de ce travail.
La première amélioration consiste en la capacité de l'application de montrer les rimes par thèmes. En d'autres termes, on offrirait à l'utilisateur la possibilité de rechercher des mots rimés d'une catégorie sémantique, c'est-à-dire que l'application montrerait tous les mots qui correspondent au mot et au thème choisis par l'utilisateur.
La deuxième amélioration serait de présenter aussi les rimes asonantes ou les mots qui permettent les lois des familles de consonnes. Si la fin était '-dos', par exemple, au moment de demander tous les mots qui riment avec cette fin, il est possible de présenter des mots avec les termes 'dos', 'di', 'gi', 'ri' à la demande de l'utilisateur.
La troisième amélioration consisterait à créer une interface web pour l'application et la publier sur Internet, de sorte que l'application soit disponible pour n'importe qui. Parallèlement à cela, il ne serait pas mal d'améliorer la rapidité de l'application – temps de réponse –.
Et enfin, plus que comme amélioration, ce qu'il faut considérer comme objectif général est de créer un support pour lequel il apprend des berthos, en plus des rimes, des mesures, des mélodies, etc., un professeur virtuel de berthsos qui offre de l'aide.
En conclusion, nous pourrions dire que cette application serait un travail à placer dans une autre application plus grande. Toutefois, si cette section fonctionne sur votre propre et que certaines améliorations sont apportées, ce découvreur informatique rime sera publié sur le réseau Internet pour un usage public.
Dans un proche avenir, donc, ce découvreur informatique de rime prétend être un support pour tout amateur de bertsolarisme, afin que personne ne reste sans rime quand il s'agit de faire un papier bertso. Ou servez au moins pour trouver des titres blancs rimés à ce type d'articles.
Zu idazle
Zientzia aldizkaria

