

Idioma dos números
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea

A intelixencia humana é moi complexa. Tan complexo que aínda non rompemos a súa pel. Con todo, está claro que uno dos alicerces desta intelixencia é a linguaxe. A linguaxe permitiunos expresar conceptos complexos, dar forma ás ideas e transmitilas aos nosos compañeiros, estruturar culturas ricas e deixar pegada nas seguintes xeracións.
Tendo en conta a importancia da linguaxe na nosa mente, converteuse nun tema fundamental de investigación no campo da intelixencia artificial. Chamámolo procesamiento de linguaxes naturais (LNP) e moitos o podemos ver en máis aplicacións das que pensamos: O LNP utilízase en tradutores automáticos paira identificar as mensaxes spam e clasificar o comentario dun produto que compramos en Amazon.
Nos últimos anos a revolución das redes neuronais artificiais chegou tamén ao ámbito do LNP, con espectaculares conclusións prácticas [1]. Pero non só iso: púxonos de manifesto interesantes pistas sobre como se relacionan palabras e números.
Representación de palabras paira máquinas
Supoñamos que somos directores de mercadotecnia dunha empresa de lentes. Lanzamos unhas lentes novas e queremos recoller as opinións dos compradores. Paira iso ocorréullenos utilizar a rede social Twitter. Crearemos o hashtag que leva o nome das nosas novas lentes paira saber que escriben os nosos clientes sobre as lentes. O problema é que, como a nosa empresa vende en todo o mundo, esperamos moitos tweets. Así que non podes ler todos os tuits! Gustaríanos que todo este traballo fixéseo o computador.
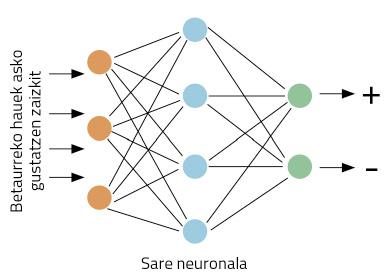
Imos concretar mellor os traballos: tomando un paxaro, o noso computador debe decidir se se dá una opinión positiva ou negativa sobre as nosas lentes. Empecemos traballando. Este tipo de problemas son adecuados paira redes neuronais. A idea é sinxela: insignia á rede neuronal varios tweets, indicando si son positivos ou negativos; a través da visualización de exemplos, a rede aprenderá a distinguir entre positivos e negativos (Figura 1).
Pero temos outro problema: as redes neuronais traballan con números, non con palabras. Como representamos as palabras con números? No mundo do LNP fíxose un gran traballo respecto diso, o que fai que haxa moitas formas de representación de palabras. A idea máis sinxela é a denominada one-hot vector en inglés.
Imaxinemos catro palabras: arriba, abaixo, esquerda e dereita. Paira iso utilizaremos vectores de catro números e asignaremos una posición a cada palabra. Noso vector de catro elementos estará formado por ceros, excepto na posición que asignamos a cada palabra, onde poremos un (Figura 2).
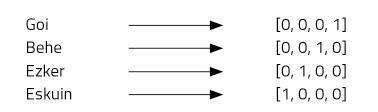
Este tipo de representación é moi simple e distingue ben cada palabra, pero ten algúns inconvenientes. Por exemplo, todos sabemos que as palabras arriba e abaixo son antónimos. Os vectores de ambas as palabras demostran esta relación? Non. O uso de “one-hot vector” non permite imaxinar relacións entre palabras. Outro problema: o eúscaro, por exemplo, ten unhas 37 mil palabras [2]. Paira representalas necesitariamos vectores de 37 mil dimensións! Non parece, por tanto, una idea moi boa.
Word2Vec
É una idea atractiva utilizar vectores paira representar palabras, xa que as redes neuronais traballan ben con vectores. Pero temos que mellorar os vectores one-hot. Así o pensaron Mikolov e os seus compañeiros cando inventaron a técnica Word2Vec [3]. Mediante esta técnica obtéñense representacións moi interesantes das palabras por:
1. As palabras pódense representar mediante pequenos vectores.

2. Pódense representar relacións semánticas entre palabras.
Como se consegue? Utilización estraña de redes neuronais. Supoñamos que tomamos como texto toda a Wikipedia en eúscaro. Nela aparecerán a maioría das palabras en eúscaro, en frases ben estruturadas. Tomaremos as palabras destas frases e codificaremos one-hot vector mediante unha representación simple. Agora vén o truco. Tomaremos una palabra paira pasar a unha rede neuronal, cuxo obxectivo é inventar as dúas palabras que están por diante e por detrás desa palabra. É dicir, adestraremos a rede neuronal paira adiviñar o seu contexto cunha palabra, tal e como se mostra na Figura 3.
Na figura 4 pódese observar a rede neuronal utilizada paira realizar este adestramento. Procesará o texto completo de nosa Wikipedia en eúscaro, tal e como se mostra. A través de una palabra, traballará neste adestramento a capacidade de adiviñar o seu contexto. Ao principio, a palabra contexto non acertará, polo que cometerá grandes erros. Pero estes erros utilízanse paira adestrar a rede. Así, a rede reducirá os seus erros de invención a través da observación de textos de millóns de palabras.
Durante este proceso, con todo, onde están as representacións das palabras apresas? Na figura 4, na casa que representamos como proxección. Quizá paira entendelo mellor, temos que mirar a figura 5. Nela pódese observar a estrutura máis precisa da rede neuronal nun caso no que só se tomaron dúas palabras: una de entrada e outra de saída. Una vez finalizado o proceso de adestramento, paira obter a representación dunha palabra basta con pasar esa palabra á rede neuronal que acabamos de adestrar e tomar activacións ocultas de capa. Do mesmo xeito que as neuronas dos nosos cerebros, as neuronas artificiais tamén se activan de forma diferente segundo diferentes estímulos. Pois ben, as activacións que se obteñen paira una palabra diferente serán a representación adecuada desa palabra. Non é sorprendente?
En definitiva, a rede neuronal que adestramos paira realizar una tarefa concreta aprendeu de forma automática algunhas representacións numéricas das palabras. E estas representacións son moi poderosas.

Xogando coas palabras
As activacións destas neuronas ocultas son números. Por tanto, colocando 300 neuronas nesta capa, obteremos un vector de 300 números paira calquera palabra. Tendo en conta que na representación de One-hot vector necesitabamos máis de 37 mil números, gañamos moito, non? Pero iso non é o mellor. Estes novos vectores de palabras teñen propiedades case máxicas. Imos xogar con eles, quedades abertos!
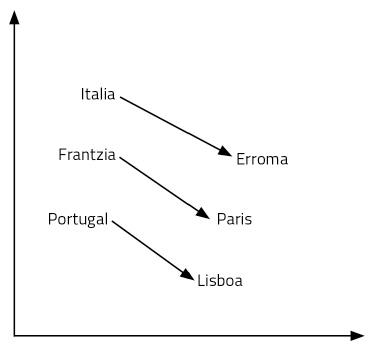
Empecemos cunha pregunta: O que paira Italia é Roma, que é paira Francia? A túa resposta será París. Por que? Porque viches país e capital na relación Italia-Roma. Utilizando o seu significado, fixo ese razoamento. Así que pensaches cal é a capital de Francia: París. Paira atopar a resposta á pregunta foi necesario manexar a linguaxe e os conceptos. Parece un proceso bastante complexo.
Os vectores de palabras que acabamos de aprender permítennos responder con facilidade a este tipo de preguntas. Neste caso, basta con realizar a operación Italia – Roma + Francia. É dicir, ao vector Italia restámoslle o vector Roma e despois engadímoslle o vector Francia. E si, o resultado é o vector París! Outro exemplo: Rei – home + muller = reina. Alucinante, non?

Como é posible? É así que engadir e eliminar vectores equivale a razoar? As representacións das palabras que aprendemos son só puntos dun espazo de 300 dimensións. Pensemos en dúas dimensións paira facilitar a súa visualización. Na figura 6 represéntanse algúns países e capitais nun plano de 2 dimensións. Como se pode observar, os países aparecen cerca, incluso as capitais, que forman parte dunha categoría semántica destas características. Pero ademais, a distancia entre un país e o seu capital é igual paira todos párelos de capitais de país. Por iso funcionan as nosas sumas e restas. Iso mesmo pasa con todas as palabras dunha lingua, pero nun espazo de 300 dimensións. Finalmente, as relacións entre palabras, o seu significado e matices son propiedades xeométricas.
Hai que ter en conta que ninguén deseñou ese espazo semántico que forman esas representacións das palabras. Una rede neuronal aprendeu por si mesma, una rede neuronal que se adestrou paira inventar o seu contexto cunha palabra. É sorprendente pensar como una complexa representación é aprendida por unha rede que adestramos paira aprender una tarefa sinxela. Pero así sucede.
Paira terminar
A representación das palabras mediante redes neuronais é a base do LNP actual. Por exemplo, as redes complexas utilizadas na tradución automática consideran estes vectores de palabras como introdución. Tomar vectores en eúscaro e crear vectores en inglés, por exemplo. Nestes procesos observouse que as propiedades xeométricas entre palabras apresas en diferentes linguas son moi similares. É dicir, as posicións relativas dos vectores king, man, woman e queen en inglés son practicamente iguais aos vectores rei, home, muller e raíña en eúscaro. Investigadores do Grupo Ixa da UPV, Elhuyar e Vicomtech, entre outros, están a estudar estas vías e propondo técnicas innovadoras de tradución.
Outros investigadores demostraron que nas propiedades xeométricas dos vectores pódense detectar tendencias sexistas na nosa lingua. Así, propuxéronse técnicas paira eliminar as tendencias sexistas destas palabras para que as máquinas non repitan os nosos erros [5].
Todos estes traballos cambian radicalmente a nosa visión da relación entre palabras e números. Ten en conta que as nosas neuronas traballan coa tensión eléctrica. Con números, dalgunha maneira. Os nosos recordos, sentimentos, linguaxe e razoamento están presentes nos desprazamentos dos electróns entre neuronas. Do mesmo xeito que ocorre coas redes neuronais artificiais, non falo, sen darme conta, operando cunha chea de números? Non será noso outro idioma?
Bibliografía
Traballo presentado aos premios CAF-Elhuyar.
Zu idazle
Zientzia aldizkaria

