

Langue des nombres
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea

L'intelligence humaine est très complexe. Si complexe que nous n'avons pas encore brisé votre peau. Cependant, il est clair que l'un des piliers de cette intelligence est le langage. Le langage nous a permis d'exprimer des concepts complexes, de façonner les idées et de les transmettre à nos compagnons, de structurer des cultures riches et de laisser des traces dans les générations suivantes.
Compte tenu de l'importance du langage dans notre esprit, il est devenu un sujet fondamental de recherche dans le domaine de l'intelligence artificielle. Nous l'appelons traitement des langages naturels (LNP) et beaucoup le voient dans plus d'applications que nous pensons : Le LNP est utilisé dans les traducteurs automatiques pour identifier les messages spam et classer le commentaire d'un produit que nous avons acheté sur Amazon.
Ces dernières années, la révolution des réseaux neuronaux artificiels a également atteint le domaine du LNP, avec des conclusions pratiques spectaculaires [1]. Mais pas seulement cela: il nous a montré des indices intéressants sur la façon dont les mots et les nombres sont liés.
Représentation des mots pour machines
Supposons que nous sommes directeurs marketing d'une société de lunettes. Nous avons lancé de nouvelles lunettes et nous voulons recueillir les avis des acheteurs. Pour cela, il nous est arrivé d'utiliser le réseau social Twitter. Nous créerons le hashtag qui porte le nom de nos nouvelles lunettes pour savoir ce que nos clients écrivent sur les lunettes. Le problème est que, comme notre société vend partout dans le monde, nous attendons de nombreux tweets. Vous ne pouvez donc pas lire tous les tweets ! Nous aimerions que tout ce travail soit fait par l'ordinateur.
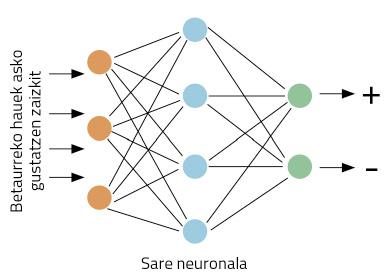
Nous allons mieux concrétiser les travaux: en prenant un oiseau, notre ordinateur doit décider de donner une opinion positive ou négative sur nos lunettes. Commençons par travailler. Ces types de problèmes sont adaptés aux réseaux neuronaux. L'idée est simple : elle enseigne au réseau neuronal plusieurs tweets, indiquant s'ils sont positifs ou négatifs ; à travers la visualisation d'exemples, le réseau apprendra à distinguer positifs et négatifs (Figure 1).
Mais nous avons un autre problème : les réseaux neuronaux travaillent avec des nombres, pas avec des mots. Comment représentons-nous les mots avec des nombres ? Dans le monde du LNP, un grand travail a été fait à ce sujet, ce qui rend de nombreuses formes de représentation des mots. L'idée la plus simple est celle appelée one-hot vector en anglais.
Imaginons quatre mots : haut, bas, gauche et droite. Pour cela, nous utiliserons des vecteurs à quatre nombres et assignerons une position à chaque mot. Notre vecteur à quatre éléments sera composé de zéros, sauf dans la position que nous avons assignée à chaque mot, où nous en mettrons un (figure 2).
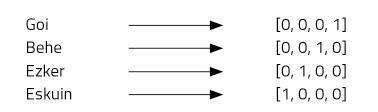
Ce type de représentation est très simple et distingue bien chaque mot, mais a quelques inconvénients. Par exemple, nous savons tous que les mots haut et bas sont antonymes. Les vecteurs des deux mots démontrent cette relation ? Non. L'utilisation de « one-hot vector » ne permet pas d'imaginer des relations entre les mots. Un autre problème: le basque, par exemple, a environ 37 mille mots [2]. Pour les représenter nous aurions besoin de vecteurs de 37 mille dimensions! Il ne semble donc pas une très bonne idée.
Word2Vec
C'est une idée attrayante d'employer des vecteurs pour représenter des mots, puisque les réseaux neuronaux fonctionnent bien avec des vecteurs. Mais nous devons améliorer les vecteurs one-hot. C'est ce qu'ont pensé Mikolov et ses compagnons lorsqu'ils ont inventé la technique Word2Vec [3]. Grâce à cette technique, on obtient des représentations très intéressantes des mots par:
1. Les mots peuvent être représentés par de petits vecteurs.

2. On peut représenter des relations sémantiques entre les mots.
Comment est-il obtenu? Utilisation étrange des réseaux neuronaux. Supposons que nous prenons comme texte toute la Wikipedia en basque. On y trouvera la plupart des mots en basque, en phrases bien structurées. Nous prendrons les mots de ces phrases et coderons one-hot vector par une représentation simple. Maintenant vient le tour. Nous prendrons un mot pour passer à un réseau neuronal, dont le but est d'inventer les deux mots qui sont devant et derrière ce mot. C'est-à-dire que nous formerons le réseau neuronal pour deviner son contexte avec un mot, comme le montre la Figure 3.
La figure 4 montre le réseau neuronal utilisé pour cette formation. Il traitera le texte complet de notre Wikipedia en basque, comme le montre. Par un mot, vous travaillerez dans cette formation la capacité de deviner votre contexte. Au début, le mot contexte ne réussira pas, donc il fera de grandes erreurs. Mais ces erreurs sont utilisées pour former le réseau. Ainsi, le réseau réduira ses erreurs d'invention par l'observation de textes de millions de mots.
Pendant ce processus, cependant, où sont les représentations des mots appris? Dans la figure 4, dans la case que nous avons représentée comme projection. Peut-être pour mieux le comprendre, nous devons regarder la figure 5. On peut y observer la structure la plus précise du réseau neuronal dans un cas où seuls deux mots ont été pris: l'un d'entrée et l'autre de sortie. Une fois le processus d'entraînement terminé, pour obtenir la représentation d'un mot il suffit de passer ce mot au réseau neuronal que nous venons de former et de prendre des activations cachées de couche. Comme les neurones de nos cerveaux, les neurones artificiels sont également activés différemment selon différents stimuli. Eh bien, les activations obtenues pour un mot différent seront la bonne représentation de ce mot. N'est-ce pas surprenant ?
En définitive, le réseau neuronal que nous avons formé pour accomplir une tâche concrète a appris automatiquement quelques représentations numériques des mots. Et ces représentations sont très puissantes.

Jouer avec les mots
Les activations de ces neurones cachés sont des nombres. Par conséquent, en plaçant 300 neurones dans cette couche, nous obtiendrons un vecteur de 300 nombres pour n'importe quel mot. Étant donné que dans la représentation de One-hot vector nous avions besoin de plus de 37 mille numéros, nous avons gagné beaucoup, non ? Mais ce n'est pas le meilleur. Ces nouveaux vecteurs de mots ont des propriétés presque magiques. Nous allons jouer avec eux, vous serez ouverts!
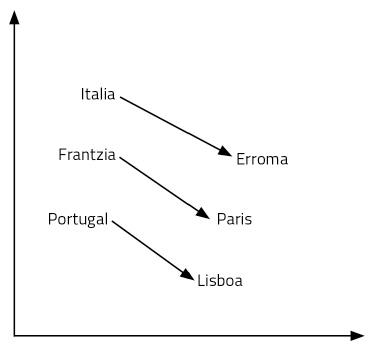
Commençons par une question : Ce qui pour l'Italie est Rome, qu'est-ce que la France? Votre réponse sera Paris. Pourquoi ? Parce que tu as vu pays et capital dans la relation Italie-Rome. En utilisant sa signification, il a fait ce raisonnement. Donc, vous avez pensé quelle est la capitale de la France: Paris. Pour trouver la réponse à la question, il a fallu gérer le langage et les concepts. Il semble un processus assez complexe.
Les vecteurs de mots que nous venons d'apprendre nous permettent de répondre facilement à ce type de questions. Dans ce cas, il suffit de réaliser l'opération Italie-Rome + France. C'est-à-dire, au vecteur l'Italie nous lui résistons le vecteur Rome et ensuite nous lui ajoutons le vecteur France. Et oui, le résultat est le vecteur Paris ! Un autre exemple: Roi – homme + femme = reine. Hallucinant, non ?

Comment est-il possible ? Est-il donc d'ajouter et de supprimer des vecteurs équivaut à raisonner ? Les représentations des mots que nous avons appris sont seulement des points d'un espace de 300 dimensions. Pensons à deux dimensions pour faciliter la visualisation. La figure 6 représente certains pays et capitales sur un plan à 2 dimensions. Comme on peut le voir, les pays apparaissent à proximité, même les capitales, qui font partie d'une catégorie sémantique de ces caractéristiques. Mais en outre, la distance entre un pays et son capital est égale pour toutes les paires de capitaux de pays. C'est pourquoi nos sommes et restes fonctionnent. C'est la même chose avec tous les mots d'une langue, mais dans un espace de 300 dimensions. Enfin, les relations entre les mots, leur signification et les nuances sont des propriétés géométriques.
Il faut garder à l'esprit que personne n'a conçu cet espace sémantique qui forment ces représentations des mots. Un réseau neuronal a appris par lui-même, un réseau neuronal qui a été formé pour inventer son contexte avec un mot. Il est surprenant de penser comment une représentation complexe est apprise par un réseau que nous formons pour apprendre une tâche simple. Mais cela arrive.
Pour finir
La représentation des mots par des réseaux neuronaux est la base du LNP actuel. Par exemple, les réseaux complexes utilisés dans la traduction automatique considèrent ces vecteurs de mots comme une introduction. Prendre des vecteurs en basque et créer des vecteurs en anglais, par exemple. Dans ces processus, il a été observé que les propriétés géométriques entre les mots appris dans différentes langues sont très similaires. Autrement dit, les positions relatives des vecteurs king, man, woman et queen anglais sont pratiquement égales aux vecteurs roi, homme, femme et reine en basque. Des chercheurs du Groupe Ixa de l'UPV, Elhuyar et Vicomtech, entre autres, étudient ces voies et proposent des techniques de traduction innovantes.
D'autres chercheurs ont montré que les propriétés géométriques des vecteurs peuvent détecter des tendances sexistes dans notre langue. Ainsi, des techniques ont été proposées pour éliminer les tendances sexistes de ces mots afin que les machines ne répétent pas nos erreurs [5].
Tous ces travaux changent radicalement notre vision de la relation entre mots et nombres. Notez que nos neurones fonctionnent avec la tension électrique. Avec des nombres, en quelque sorte. Nos souvenirs, sentiments, langage et raisonnement sont présents dans les déplacements des électrons entre neurones. Comme pour les réseaux neuronaux artificiels, je ne parle pas, sans me rendre compte, opérant avec beaucoup de chiffres? Ne sera-t-il pas notre autre langue?
Bibliographie Bibliographie
Travail présenté aux prix CAF-Elhuyar.
Zu idazle
Zientzia aldizkaria

