

Resolvendo os escuros camiños da intuición
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea

Ao redor da intuición, moitos pensadores traballaron ao longo da historia, como Descartes, Kant ou Husserl. Hoxe en día, con todo, a intuición é un concepto que estudan psicólogos e neurólogos, utilizando paira iso as ferramentas e camiños da ciencia moderna. Non traemos aquí os seus traballos profundos. Basta con saber que, segundo as últimas teorías, a intuición é o coñecemento que se xera a través de vías non racionais. Por tanto, este tipo de coñecemento non podemos nin explicar nin falar [1]. Dá importancia a este concepto, que volverá aparecer.
Ao longo deste artigo veremos si a intuición é una característica exclusiva dos seres humanos. Paira iso, primeiro analizaremos e entenderemos as máquinas que xogan ao xadrez. A continuación veremos un dos grandes logros científicos de 2016 paira a revista Science [2]: AlphaGo, a intelixencia artificial que conquistou o xogo chinés.
Xadrez e máquina Deep Blue

Na cultura occidental, o xadrez foi a culminación dos xogos estratéxicos de mesa. Tentemos analizar este xogo a través dos números. No xadrez cada xogador ten ao principio 16 pezas de 6 tipos. As pezas de cada tipo pódense mover de distintas formas. Por tanto, en calquera situación do xogo, un xogador pode realizar 35 movementos diferentes.
O xadrez e este tipo de xogos poden aparecer utilizando estruturas tipo árbore. Na raíz da árbore indícase o estado inicial do partido, estando cada peza na súa posición inicial. Supoñamos que desde a situación inicial movemos un peón. Esta nova situación estaría na primeira liña da nosa árbore, con todos os movementos posibles de todas as demais pezas. De cada nova situación sairán tantas novas ramas como movementos posibles e así até chegar ao final (Figura 1).
Considérase que o número de xogos que se poden crear no xadrez, é dicir, o número de nodos da árbore, é aproximadamente 10120. Paira ver con máis claridade a magnitude deste número, imaxínache que, segundo os mellores cálculos, no noso universo hai 1080 átomos!
A máquina que por primeira vez puido vencer a un gran mestre de xadrez foi Deep Blue en 1997 [3]. Este supercomputador programado por IBM utilizaba a árbore do xadrez paira tomar decisións. Ao non poder conservar toda a árbore, a partir do nodo que representaba un estado de xogo, a máquina analizaba o seguintes seis liñas de profundidade. Avaliaba os nodos que había nesas profundidades, vendo cal era o nodo peor paira el e cal o mellor. Tras esta avaliación, tomaba o movemento necesario paira evitar o peor nodo.
A clave desta estratexia de xogo é a capacidade de avaliación dos nodos. Paira iso, IBM traballou con grandes xogadores de xadrez paira obter criterios programables co seu coñecemento. Estes criterios denomínanse heurísticos. IBM fixo un gran traballo paira definir e programar eses heurísticos e acabou derrotando ao propio Gary Kasparov.
O xogo chinés Go
As regras do xogo go son máis sinxelas que o xadrez, pero o xogo é moito máis complexo. Calcúlase que hai 10761 xogos posibles na cima! Pero iso non é o peor: no xadrez é posible programar heurísticos, pero é case imposible definir ben os criterios que funcionan correctamente e convertelos en programas. En xeral, os expertos ponse de acordo en si un movemento foi bo ou malo, pero non poden explicar por que pensan. Parece que a intuición é a clave paira xogar. E, por suposto, aínda non sabemos falar da intuición, convertela nunha fórmula matemática ou escribila como un programa.
Por iso, a maioría dos expertos dicían que, hai non moitos anos, non viamos ningunha máquina que gañase aos mellores xogadores do Go na década do vinte. Pois o vimos. En marzo de 2016, Deep Mind [4] gañou coa máquina AlphaGo a un dos grandes campións do mundo, o coreano Le Sedol.
AlphaGo e o poder de aprendizaxe
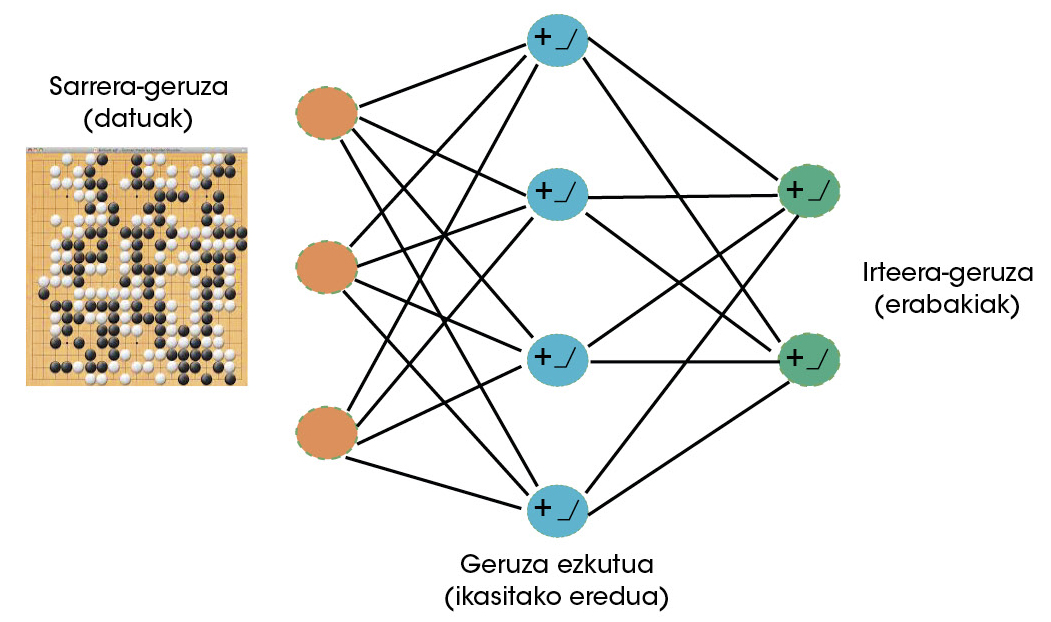
Os científicos de Deep Mind viron claro que o goa podía ser un xogo moi apropiado paira máquinas con capacidade de aprender. Por tanto, as redes neuronais empezaron a usarse paira aprender a xogar no futuro [5]. As redes neuronais son na actualidade os algoritmos de aprendizaxe máis exitosos [6]. Do mesmo xeito que as neuronas cerebrais, as neuronas artificiais reciben una serie de sinais (datos) que, segundo o apreso, actívanse ou non. Ao longo do proceso de aprendizaxe, a rede neuronal define os datos ante os que debe activarse e a intensidade de devanditas activacións. Mediante a interconexión de neuronas artificiais, a formación de capas, estas redes poden aprender comportamentos moi complexos (Figura 2).
AlphaGo conta con dúas importantes redes neuronais: por unha banda temos una rede de políticas e por outro una rede de valores. O obxectivo da rede de políticas é adiviñar cal será o seguinte mellor movemento cunha situación de xogo. Paira iso combínanse dúas estratexias de aprendizaxe. Nun principio, mostráronse á rede 30 millóns de xogadas humanas cunha aprendizaxe supervisada. É dicir, paira una situación de xogo que vía a rede ensinábaselle cal era o seguinte movemento. Aprendeu a xeneralizar deses exemplos. Una vez procesados todos os movementos e terminados os estudos, a rede política prevía os movementos dun ser humano cunha taxa de invención do 57%.
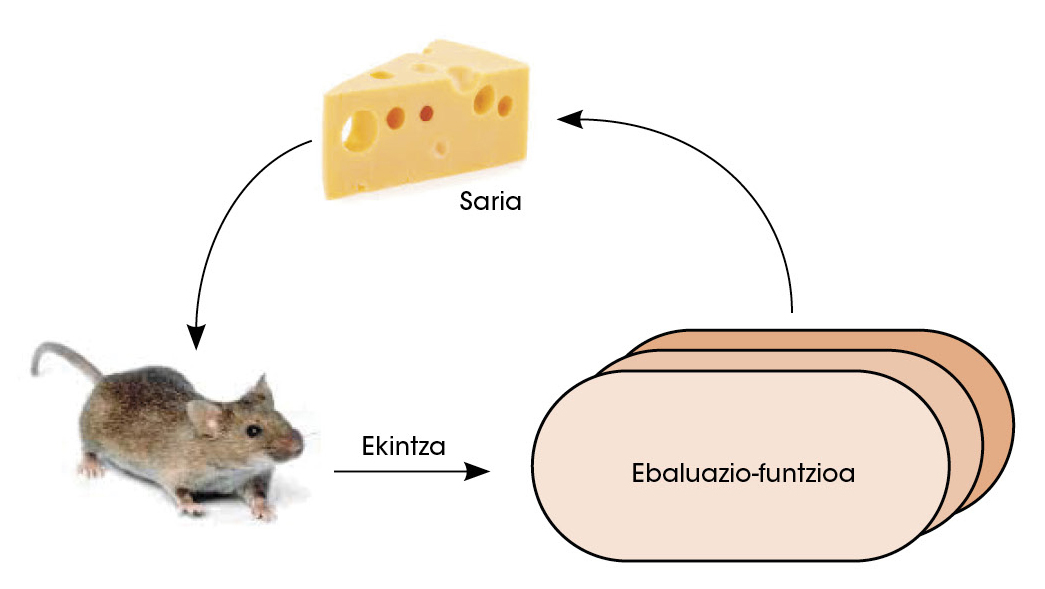
Nunha segunda fase, a rede política enfróntase a si mesma. Así, coa aprendizaxe por reforzo, a rede mellorou a capacidade de decidir cal era o seguinte mellor movemento. Neste tipo de estudos dáse liberdade á rede paira tomar decisións. Se como consecuencia destas decisións consegue gañar, outórgaselle o premio. Pero si perde castígaselle. Paira maximizar o número de premios, a rede aprende a tomar decisións cada vez mellores (figura 3).
A rede de valores ten outro obxectivo. A súa misión é valorar a probabilidade de gañar cunha situación de xogo. Paira adestrar esta rede utilizáronse miles de partidos disputados por AlphaGo contra si mesmo. Tras ver tantos partidos, a rede de valores aprendeu a calcular correctamente a oportunidade de gañar a un xogador ante un escenario de xogo.
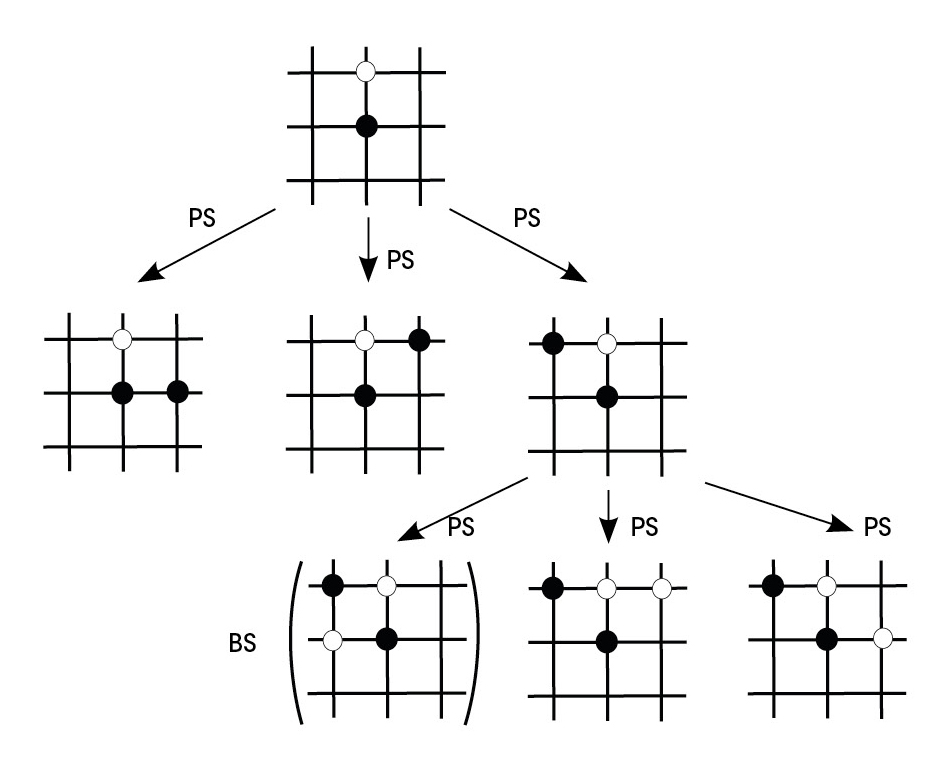
Como se combinan estas dúas redes neuronais paira xogar no ollo? Paira iso debemos volver utilizar a árbore do xogo. AlphaGo, a través de una situación de xogo, utiliza a rede política paira predicir os próximos mellores movementos. Simula partidas paira estes movementos até certa profundidade. Os estados de xogo finais destas partidas pasan á rede de valores paira calcular a probabilidade de gañar. Deste xeito, AlphaGo mantén a rama de xogo que máis probabilidades lle dá á rede de valores de entre os movementos que o tecido político considera mellores (figura 4). Hai que ter en conta, ademais, que con máis partidas, tanto a rede política como a rede de valores fanse mellores no seu traballo.
Deep Blue vs AlphaGo
É certo que ambas as máquinas toman decisións mediante procuras na árbore de xogo. Pero hai una diferenza enorme á hora de analizalos. No caso de Deep Blue, os expertos programaron manualmente os criterios paira avaliar as situacións de xogo. Por tanto, Deep Blue non podería xogar nun xogo que non sexa xadrez. E, por suposto, a súa capacidade de xogo será sempre a mesma, mentres non haxa expertos que melloren os heurísticos.
AlphaGo utiliza dúas redes neuronais paira valorar os mellores movementos e as situacións de xogo. Estas redes non foron programadas manualmente. Conségueno aprendendo a súa capacidade, polo que teñen dúas vantaxes principais:
1 Válido paira calquera outro xogo de mesa.
2 A medida que se xoga máis, AlphaGo convértese en mellor xogador.
Os modos de funcionamento de ambas as máquinas son una excelente mostra dos dúas grandes paradigmas históricos do mundo da intelixencia artificial: Intelixencia ríxida orientada ao coñecemento de Deep Blue e capacidade de aprendizaxe de AlphaGoren. Desde a programación manual das máquinas até o abandono da súa propia aprendizaxe. Hoxe en día vimos bastante claro que a segunda idea, a de aprender, é moito máis poderosa con exemplos como AlphaGo.
Conclusións
A intuición é un coñecemento non racional. Os expertos que xogan en Goa recorren á intuición paira explicar as súas decisións e análises. Saben como actuar pero non son capaces de explicalo correctamente. Non poden dicir por que un movemento é mellor que outro.
AlphaGo puido imitar a función da intuición aproveitando a capacidade de aprender. Ante unha situación de xogo, decide intuitivamente cal é o seguinte mellor movemento, como o fai un ser humano. Tamén decide intuitivamente se una situación de xogo levaralle a gañar. E parece que a súa intuición está por encima do ser humano.
O gran campión Le Sedol utilizou diversas estratexias paira conquistar AlphaGo. Nun partido, intencionadamente, comportouse mal porque non sabía que facer AlphaGo ante un home que actuaba mal. Fallou. Só puido gañar nun partido grazas a un movemento que poucos esperaban. Segundo os enxeñeiros, AlphaGo previu aquel movemento, pero lle deu una probabilidade moi baixa. Le Sedol sorprendeu á máquina con este movemento. Pero una soa vez.
O reto de futuro é utilizar as redes neuronais e técnicas de aprendizaxe que utiliza AlphaGo paira resolver os nosos problemas cotiáns. As máquinas con capacidade de aprendizaxe poden axudarnos na industria, os servizos, o medicamento e mesmo no propio desenvolvemento da ciencia. A intuición é una das claves en todos estes dominios e parece que xa sabemos que facer para que as máquinas consigan esa intuición.
Bibliografía
[1] Teorías da intuición: https://é.wikipedia.org/wiki/Intuici%C3%B3 (última visita: 28/12/2016)
[2] Science’s top 10 breakthroughs of 2016: http://www.sciencemag.org/news/2016/12/ai-proteinfolding-our-breakthrough-runners? utm_source=sciencemagazine&utm_medium=twitter&utm_campaign=6319issue-10031 (última visita: 28/12/2016).
[3] Deep Blue (chess computer): https://en.wikipedia.org/wiki/Deep_Blue_(chess_computer) (última visita: 21/01/2017)
[4] Deep Mind: https://deepmind.com/ (última visita: 29/01/2017)
[5] Silver, David, et ao. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
[6] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444.
Zu idazle
Zientzia aldizkaria

