

Resolviendo los oscuros caminos de la intuición
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea

En torno a la intuición, muchos pensadores han trabajado a lo largo de la historia, como Descartes, Kant o Husserl. Hoy en día, sin embargo, la intuición es un concepto que estudian psicólogos y neurólogos, utilizando para ello las herramientas y caminos de la ciencia moderna. No traemos aquí sus trabajos profundos. Basta con saber que, según las últimas teorías, la intuición es el conocimiento que se genera a través de vías no racionales. Por lo tanto, este tipo de conocimiento no podemos ni explicar ni hablar [1]. Da importancia a este concepto, que volverá a aparecer.
A lo largo de este artículo veremos si la intuición es una característica exclusiva de los seres humanos. Para ello, primero analizaremos y entenderemos las máquinas que juegan al ajedrez. A continuación veremos uno de los grandes logros científicos de 2016 para la revista Science [2]: AlphaGo, la inteligencia artificial que ha conquistado el juego chino.
Ajedrez y máquina Deep Blue

En la cultura occidental, el ajedrez ha sido la culminación de los juegos estratégicos de mesa. Intentemos analizar este juego a través de los números. En el ajedrez cada jugador tiene al principio 16 piezas de 6 tipos. Las piezas de cada tipo se pueden mover de distintas formas. Por tanto, en cualquier situación del juego, un jugador puede realizar 35 movimientos diferentes.
El ajedrez y este tipo de juegos pueden aparecer utilizando estructuras tipo árbol. En la raíz del árbol se indica el estado inicial del partido, estando cada pieza en su posición inicial. Supongamos que desde la situación inicial movemos un peón. Esta nueva situación estaría en la primera línea de nuestro árbol, con todos los movimientos posibles de todas las demás piezas. De cada nueva situación saldrán tantas nuevas ramas como movimientos posibles y así hasta llegar al final (Figura 1).
Se considera que el número de juegos que se pueden crear en el ajedrez, es decir, el número de nodos del árbol, es aproximadamente 10120. Para ver con más claridad la magnitud de este número, imagínate que, según los mejores cálculos, en nuestro universo hay 1080 átomos!
La máquina que por primera vez pudo vencer a un gran maestro de ajedrez fue Deep Blue en 1997 [3]. Este supercomputador programado por IBM utilizaba el árbol del ajedrez para tomar decisiones. Al no poder conservar todo el árbol, a partir del nodo que representaba un estado de juego, la máquina analizaba las siguientes seis líneas de profundidad. Evaluaba los nodos que había en esas profundidades, viendo cuál era el nodo peor para él y cuál el mejor. Tras esta evaluación, tomaba el movimiento necesario para evitar el peor nodo.
La clave de esta estrategia de juego es la capacidad de evaluación de los nodos. Para ello, IBM trabajó con grandes jugadores de ajedrez para obtener criterios programables con su conocimiento. Estos criterios se denominan heurísticos. IBM hizo un gran trabajo para definir y programar esos heurísticos y acabó derrotando al propio Gary Kasparov.
El juego chino Go
Las reglas del juego go son más sencillas que el ajedrez, pero el juego es mucho más complejo. ¡Se calcula que hay 10761 juegos posibles en la cima! Pero eso no es lo peor: en el ajedrez es posible programar heurísticos, pero es casi imposible definir bien los criterios que funcionan correctamente y convertirlos en programas. En general, los expertos se ponen de acuerdo en si un movimiento ha sido bueno o malo, pero no pueden explicar por qué piensan. Parece que la intuición es la clave para jugar. Y, por supuesto, todavía no sabemos hablar de la intuición, convertirla en una fórmula matemática o escribirla como un programa.
Por eso, la mayoría de los expertos decían que, hace no muchos años, no veíamos ninguna máquina que ganara a los mejores jugadores del Go en la década de los veinte. Pues lo hemos visto. En marzo de 2016, Deep Mind [4] ganó con la máquina AlphaGo a uno de los grandes campeones del mundo, el coreano Lee Sedol.
AlphaGo y el poder de aprendizaje
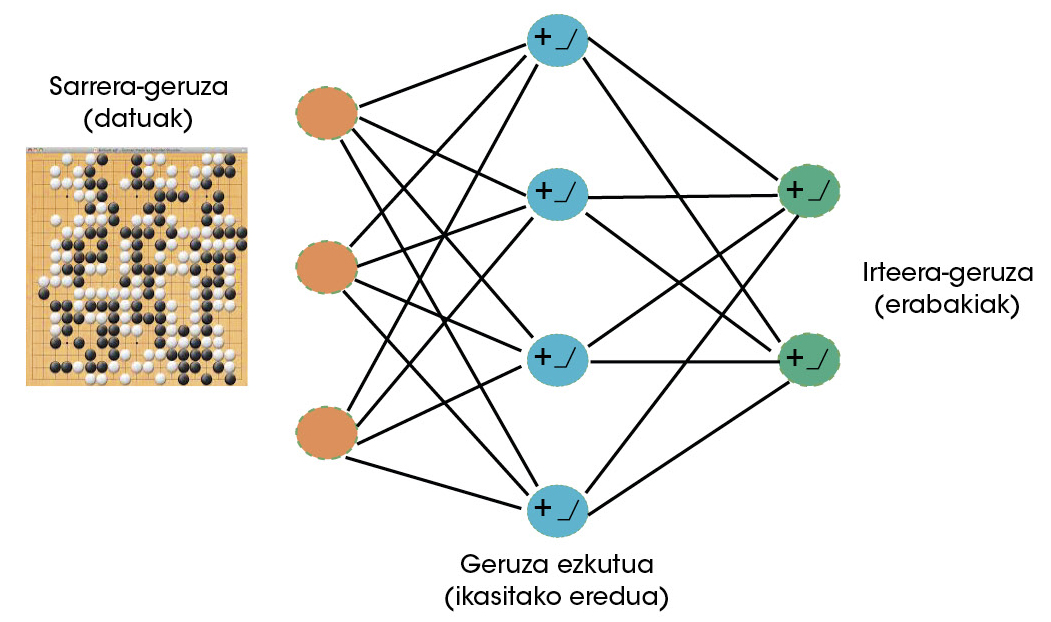
Los científicos de Deep Mind vieron claro que el goa podía ser un juego muy apropiado para máquinas con capacidad de aprender. Por lo tanto, las redes neuronales empezaron a usarse para aprender a jugar en el futuro [5]. Las redes neuronales son en la actualidad los algoritmos de aprendizaje más exitosos [6]. Al igual que las neuronas cerebrales, las neuronas artificiales reciben una serie de señales (datos) que, según lo aprendido, se activan o no. A lo largo del proceso de aprendizaje, la red neuronal define los datos ante los que debe activarse y la intensidad de dichas activaciones. Mediante la interconexión de neuronas artificiales, la formación de capas, estas redes pueden aprender comportamientos muy complejos (Figura 2).
AlphaGo cuenta con dos importantes redes neuronales: por un lado tenemos una red de políticas y por otro una red de valores. El objetivo de la red de políticas es adivinar cuál será el siguiente mejor movimiento con una situación de juego. Para ello se combinan dos estrategias de aprendizaje. En un principio, se mostraron a la red 30 millones de jugadas humanas con un aprendizaje supervisado. Es decir, para una situación de juego que veía la red se le enseñaba cuál era el siguiente movimiento. Aprendió a generalizar de esos ejemplos. Una vez procesados todos los movimientos y terminados los estudios, la red política preveía los movimientos de un ser humano con una tasa de invención del 57%.
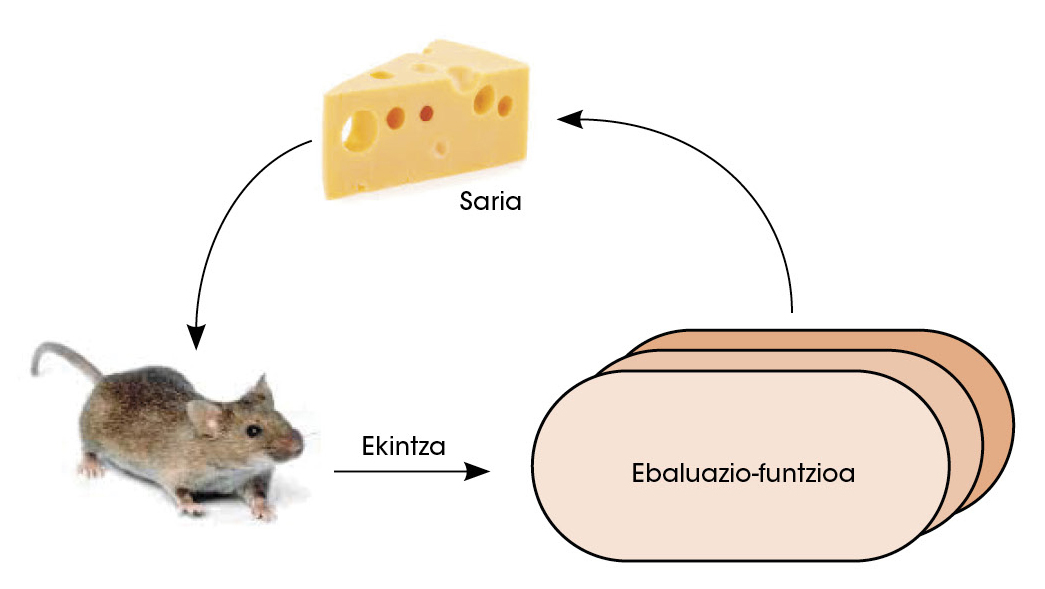
En una segunda fase, la red política se enfrenta a sí misma. Así, con el aprendizaje por refuerzo, la red mejoró la capacidad de decidir cuál era el siguiente mejor movimiento. En este tipo de estudios se da libertad a la red para tomar decisiones. Si como consecuencia de estas decisiones consigue ganar, se le otorga el premio. Pero si pierde se le castiga. Para maximizar el número de premios, la red aprende a tomar decisiones cada vez mejores (figura 3).
La red de valores tiene otro objetivo. Su misión es valorar la probabilidad de ganar con una situación de juego. Para entrenar esta red se utilizaron miles de partidos disputados por AlphaGo contra sí mismo. Tras ver tantos partidos, la red de valores aprendió a calcular correctamente la oportunidad de ganar a un jugador ante un escenario de juego.
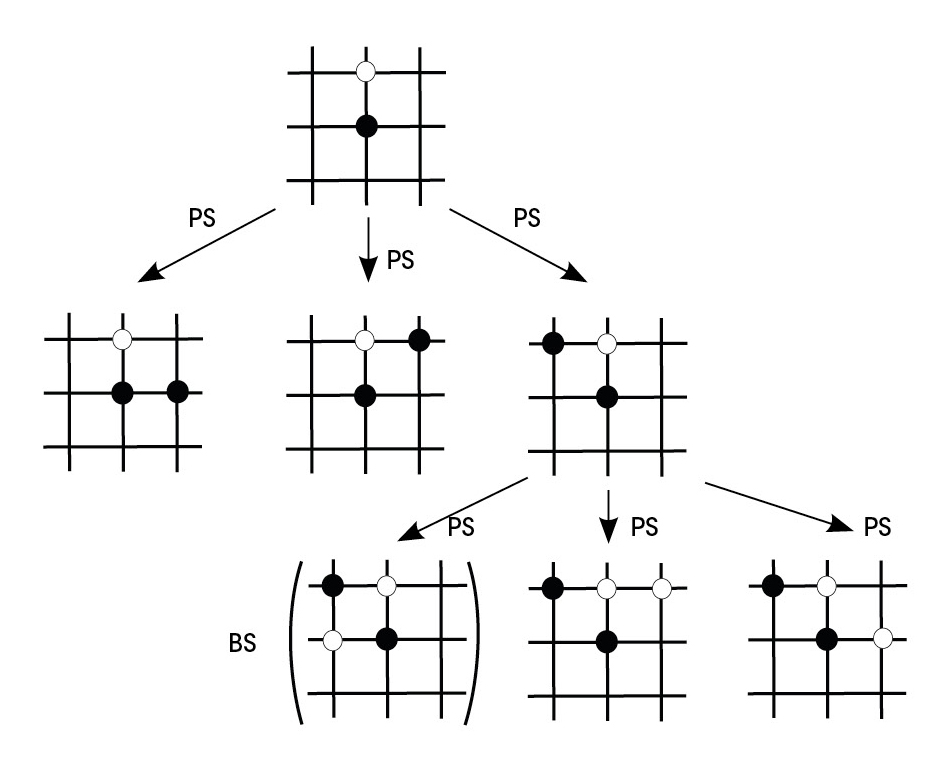
¿Cómo se combinan estas dos redes neuronales para jugar en el ojo? Para ello debemos volver a utilizar el árbol del juego. AlphaGo, a través de una situación de juego, utiliza la red política para predecir los próximos mejores movimientos. Simula partidas para estos movimientos hasta cierta profundidad. Los estados de juego finales de estas partidas pasan a la red de valores para calcular la probabilidad de ganar. De este modo, AlphaGo mantiene la rama de juego que más probabilidades le da a la red de valores de entre los movimientos que el tejido político considera mejores (figura 4). Hay que tener en cuenta, además, que con más partidas, tanto la red política como la red de valores se hacen mejores en su trabajo.
Deep Blue vs AlphaGo
Es cierto que ambas máquinas toman decisiones mediante búsquedas en el árbol de juego. Pero hay una diferencia enorme a la hora de analizarlos. En el caso de Deep Blue, los expertos programaron manualmente los criterios para evaluar las situaciones de juego. Por lo tanto, Deep Blue no podría jugar en un juego que no sea ajedrez. Y, por supuesto, su capacidad de juego será siempre la misma, mientras no haya expertos que mejoren los heurísticos.
AlphaGo utiliza dos redes neuronales para valorar los mejores movimientos y las situaciones de juego. Estas redes no han sido programadas manualmente. Lo consiguen aprendiendo su capacidad, por lo que tienen dos ventajas principales:
1 Válido para cualquier otro juego de mesa.
2 A medida que se juega más, AlphaGo se convierte en mejor jugador.
Los modos de funcionamiento de ambas máquinas son una excelente muestra de los dos grandes paradigmas históricos del mundo de la inteligencia artificial: Inteligencia rígida orientada al conocimiento de Deep Blue y capacidad de aprendizaje de AlphaGoren. Desde la programación manual de las máquinas hasta el abandono de su propio aprendizaje. Hoy en día hemos visto bastante claro que la segunda idea, la de aprender, es mucho más poderosa con ejemplos como AlphaGo.
Conclusiones
La intuición es un conocimiento no racional. Los expertos que juegan en Goa recurren a la intuición para explicar sus decisiones y análisis. Saben cómo actuar pero no son capaces de explicarlo correctamente. No pueden decir por qué un movimiento es mejor que otro.
AlphaGo ha podido imitar la función de la intuición aprovechando la capacidad de aprender. Ante una situación de juego, decide intuitivamente cuál es el siguiente mejor movimiento, como lo hace un ser humano. También decide intuitivamente si una situación de juego le llevará a ganar. Y parece que su intuición está por encima del ser humano.
El gran campeón Lee Sedol utilizó diversas estrategias para conquistar AlphaGo. En un partido, intencionadamente, se comportó mal porque no sabía qué hacer AlphaGo ante un hombre que actuaba mal. Falló. Sólo pudo ganar en un partido gracias a un movimiento que pocos esperaban. Según los ingenieros, AlphaGo previó aquel movimiento, pero le dio una probabilidad muy baja. Lee Sedol sorprendió a la máquina con este movimiento. Pero una sola vez.
El reto de futuro es utilizar las redes neuronales y técnicas de aprendizaje que utiliza AlphaGo para resolver nuestros problemas cotidianos. Las máquinas con capacidad de aprendizaje pueden ayudarnos en la industria, los servicios, la medicina e incluso en el propio desarrollo de la ciencia. La intuición es una de las claves en todos estos dominios y parece que ya sabemos qué hacer para que las máquinas consigan esa intuición.
Bibliografía
[1] Teorías de la intuición: https://es.wikipedia.org/wiki/Intuici%C3%B3 (última visita: 28/12/2016)
[2] Science’s top 10 breakthroughs of 2016: http://www.sciencemag.org/news/2016/12/ai-proteinfolding-our-breakthrough-runners? utm_source=sciencemagazine&utm_medium=twitter&utm_campaign=6319issue-10031 (última visita: 28/12/2016).
[3] Deep Blue (chess computer): https://en.wikipedia.org/wiki/Deep_Blue_(chess_computer) (última visita: 21/01/2017)
[4] Deep Mind: https://deepmind.com/ (última visita: 29/01/2017)
[5] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
[6] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444.
Zu idazle
Zientzia aldizkaria

