

Solving the dark paths of intuition
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea

Around intuition, many thinkers have worked throughout history, such as Descartes, Kant or Husserl. Today, however, intuition is a concept that psychologists and neurologists study, using the tools and paths of modern science. We do not bring here his deep works. It is enough to know that, according to the latest theories, intuition is the knowledge generated through non-rational ways. Therefore, this kind of knowledge can neither explain nor speak [1]. It gives importance to this concept, which will reappear.
Throughout this article we will see if intuition is an exclusive feature of human beings. For this, we will first analyze and understand the machines that play chess. Here is one of the great scientific achievements of 2016 for the journal Science [2]: AlphaGo, the artificial intelligence that has conquered the Chinese game.
Deep Blue Chess and Machine

In Western culture, chess has been the culmination of strategic board games. Let's try to analyze this game through the numbers. In chess each player has at first 16 pieces of 6 types. Parts of each type can be moved in different ways. Therefore, in any situation of the game, a player can make 35 different moves.
Chess and such games can appear using tree structures. At the root of the tree is indicated the initial state of the match, each piece being in its initial position. Suppose from the initial situation we move a pawn. This new situation would be on the front line of our tree, with all possible movements of all other pieces. From each new situation will come as many new branches as possible movements and so until the end (Figure 1).
It is considered that the number of games that can be created in chess, that is, the number of nodes in the tree, is approximately 10120. To see more clearly the magnitude of this number, imagine that, according to the best calculations, in our universe there are 1080 atoms!
The machine that for the first time was able to beat a great chess master was Deep Blue in 1997 [3]. This supercomputer programmed by IBM used the chess tree to make decisions. Unable to preserve the entire tree, from the node representing a state of play, the machine analyzed the following six depth lines. He evaluated the nodes in those depths, seeing what was the worst node for him and which one was the best. After this evaluation, he took the necessary movement to avoid the worst node.
The key to this game strategy is the ability to evaluate nodes. To do this, IBM worked with great chess players to obtain programmable criteria with their knowledge. These criteria are called heuristics. IBM did a great job of defining and programming these heuristics and ended up defeating Gary Kasparov himself.
The Chinese game Go
The rules of the go game are simpler than chess, but the game is much more complex. An estimated 10761 games are possible at the top! But that is not the worst: in chess it is possible to program heuristics, but it is almost impossible to define well the criteria that work correctly and turn them into programs. In general, experts agree on whether a movement has been good or bad, but they cannot explain why they think. It seems that intuition is the key to play. And, of course, we still don't know how to talk about intuition, turn it into a mathematical formula or write it as a program.
That's why most experts said that not many years ago, we didn't see a machine that won the best Go players in the 1920s. We have seen it. In March 2016, Deep Mind [4] won with the AlphaGo machine one of the world's great champions, Korean Lee Sedol.
AlphaGo and the learning power
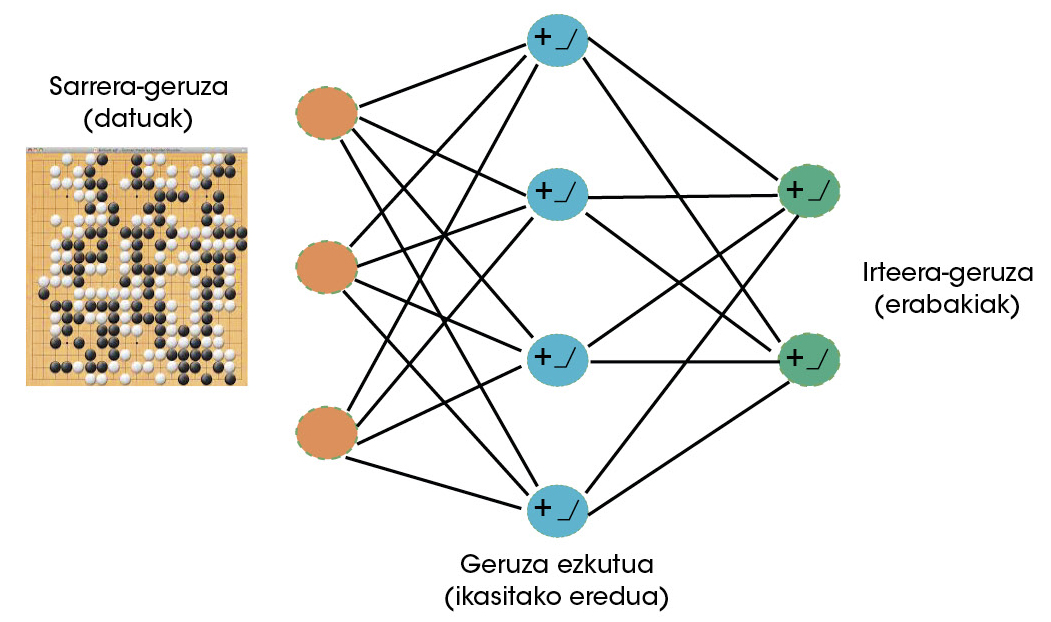
Deep Mind scientists clearly saw that goa could be a very appropriate game for machines with ability to learn. Therefore, neural networks began to be used to learn to play in the future [5]. Neural networks are currently the most successful learning algorithms [6]. Like brain neurons, artificial neurons receive a series of signals (data) that, as learned, are activated or not. Throughout the learning process, the neural network defines the data to be activated and the intensity of these activations. By interconnecting artificial neurons, layer formation, these networks can learn very complex behaviors (Figure 2).
AlphaGo has two important neural networks: on the one hand we have a network of policies and on the other a network of values. The goal of the policy network is to guess what the next best move will be with a game situation. Two learning strategies are combined. Initially, 30 million human plays were shown to the network with supervised learning. That is, for a game situation that saw the net he was taught what the next move was. He learned to generalize from those examples. Once all the movements were processed and the studies finished, the political network provided for the movements of a human being with an invention rate of 57%.
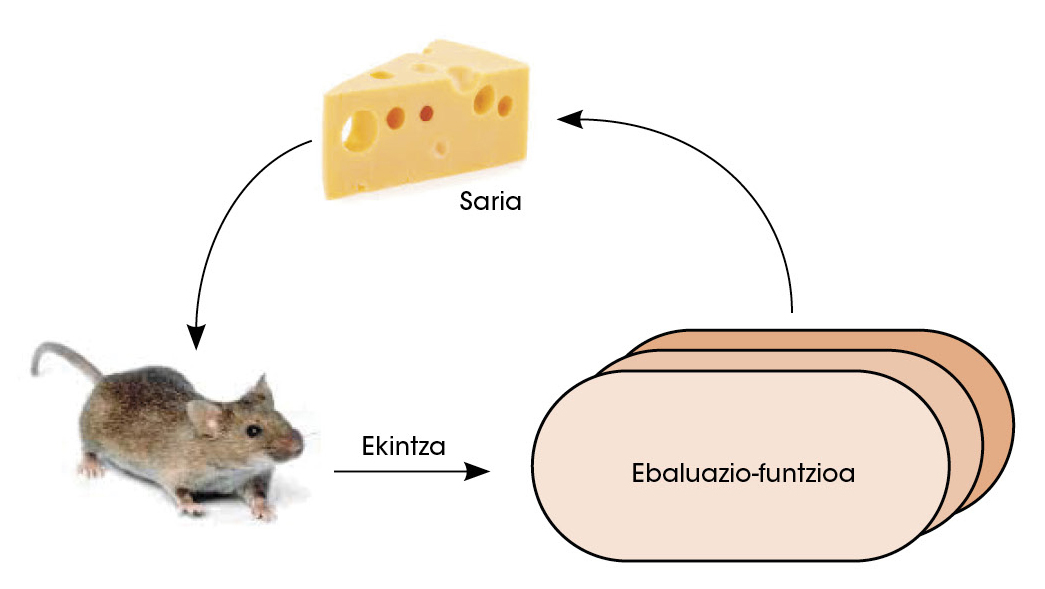
In a second phase, the political network faces itself. Thus, with reinforcement learning, the network improved the ability to decide which was the next best move. In such studies the network is given freedom to make decisions. If you win as a result of these decisions, you are awarded the prize. But if he loses he is punished. To maximize the number of awards, the network learns to make increasingly better decisions (Figure 3).
The value network has another goal. Your mission is to assess the probability of winning with a game situation. Thousands of matches played by AlphaGo against himself were used to train this network. After seeing so many matches, the net of values learned to correctly calculate the opportunity to win a player before a game scenario.
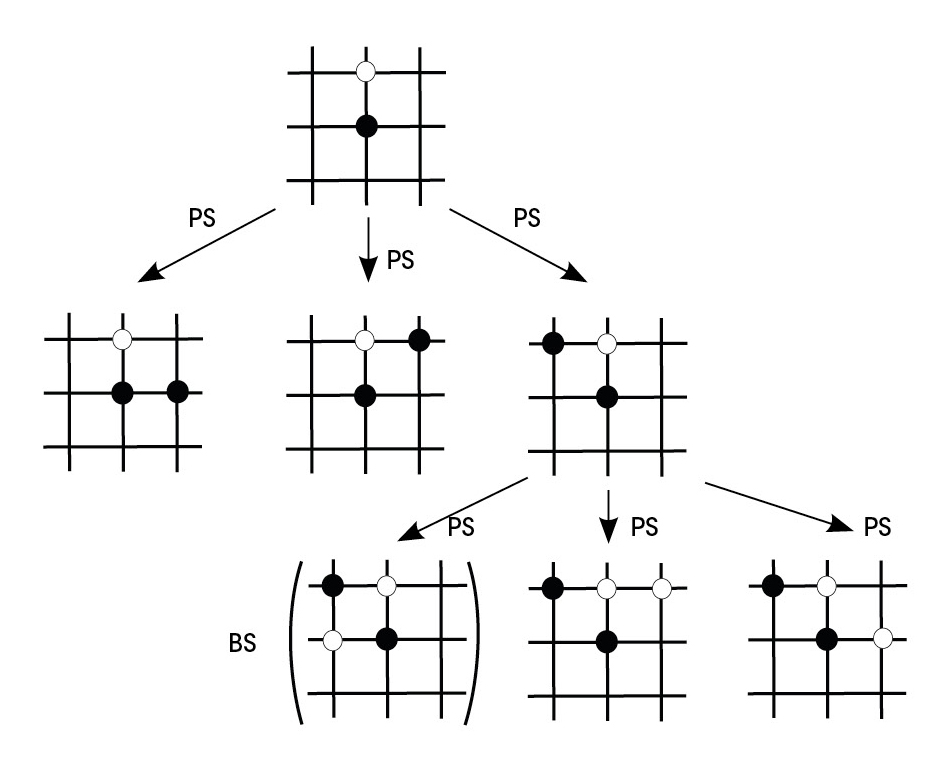
How do these two neural networks combine to play in the eye? To do this we must use the game tree again. AlphaGo, through a gaming situation, uses the political network to predict the next best moves. Simulates games for these movements to some depth. The final game states of these games move to the value grid to calculate the probability of winning. In this way, AlphaGo maintains the game branch that most likely gives the network of values among the movements that the political fabric considers better (Figure 4). We must also take into account that with more games, both the political network and the value network become better in their work.
Deep Blue vs AlphaGo
It is true that both machines make decisions by searching the game tree. But there is a huge difference when analyzing them. In the case of Deep Blue, experts manually programmed the criteria to assess game situations. Therefore, Deep Blue could not play in a game other than chess. And, of course, their playing ability will always be the same, as long as there are no experts to improve heuristics.
AlphaGo uses two neural networks to assess the best movements and play situations. These networks have not been programmed manually. They get it by learning their ability, so they have two main advantages:
1 Valid for any other board game.
2 As more is played, AlphaGo becomes a better player.
The operating modes of both machines are an excellent example of the two great historical paradigms of the artificial intelligence world: Deep Blue knowledge oriented rigid intelligence and AlphaGoren learning capability. From manual machine programming to abandoning your own learning. Today we have seen quite clearly that the second idea, that of learning, is much more powerful with examples like AlphaGo.
Conclusions
Intuition is a non-rational knowledge. Experts playing in Goa use intuition to explain their decisions and analysis. They know how to act but are not able to explain it correctly. They cannot say why one movement is better than another.
AlphaGo has been able to imitate the function of intuition by taking advantage of the ability to learn. Faced with a game situation, he intuitively decides which is the next best move, as a human being does. It also intuitively decides whether a gambling situation will lead you to win. And it seems that his intuition is above the human being.
The great champion Lee Sedol used various strategies to conquer AlphaGo. In a game, he intentionally behaved badly because he didn't know what to do AlphaGo before a man who acted badly. He failed. He could only win in a match thanks to a movement few expected. According to engineers, AlphaGo foresaw that move, but gave it a very low probability. Lee Sedol surprised the machine with this move. But once.
The challenge of the future is to use neural networks and learning techniques that AlphaGo uses to solve our everyday problems. Machines with learning capacity can help us in industry, services, medicine and even in the development of science itself. Intuition is one of the keys in all these domains and it seems that we already know what to do for the machines to get that intuition.
Bibliography
[1] Theories of intuition: https://es.wikipedia.org/wiki/Intuici%C3%B3 (last visit: 28/12/2016
[2] Science’s top 10 breakthroughs of 2016: http://www.sciencemag.org/news/2016/12/ai-proteinfolding-our-breakthrough-runners? utm_source=sciencemagazine&utm_medium=twitter&utm_campaign=6319issue-10031 (last visit: 28/12/2016).
[3] Deep Blue (chess computer): https://en.wikipedia.org/wiki/Deep_Blue_(chess_computer) (last visit: 21 January 2017
[4] Deep Mind: https://deepmind.com/ (last visit: 29/01/2017)
[5] Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
[6] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444.
Zu idazle
Zientzia aldizkaria

