

Os robots son capaces de aprender?
Por que os robots necesitan aprender?
No día a día realizamos moitas actividades sen apenas ter que pensar. Por exemplo, parécenos totalmente normal entrar nunha habitación que non coñecemos e camiñar sen tocar os obxectos desa habitación.

Sexa cal for a contorna, o robot tamén debe ser capaz de conseguir o seu obxectivo si queremos facer algún traballo útil. Tendo en conta a alta capacidade de computabilidad das computadoras actuais, por que non proporcionar ao robot una descrición detallada da contorna? Utilizando esta descrición, o robot será capaz de levar a cabo o seu labor sen necesidade de aprender como é e como debe actuar na contorna.
Todo isto podía ser posible nun mundo artificial de xoguete, pero non en contornas de vida real. Non poderemos proporcionar ao robot una descrición detallada da contorna, xa que pode resultar demasiado complexo ou porque a contorna non o coñecemos previamente. Talvez quereremos que este robot sexa capaz de traballar en máis dunha contorna. E si a contorna fose dinámico ou cambiante? Si a xente retrocedese e seguise alí? Como programar o robot paira traballar nestas contornas?
Está claro, por tanto, que para que nos axude na vida real, o robot debe ser capaz de adaptarse á contorna no que vai traballar, é dicir, de aprender a traballar nesa contorna. Cando aprendemos, queremos dicir que o robot debe ser capaz de mellorar o seu comportamento facéndoo máis apropiado á contorna no que se atopa.
Aprendizaxe violenta
En intelixencia artificial son moitos os métodos utilizados paira aprender. O método de aprendizaxe que se pretende analizar aquí é a aprendizaxe a través da violencia, cuxo nome deriva do valor denominado violencia. Analicemos paso a paso o proceso de aprendizaxe paira entender que é a violencia.
Para que o robot adapte o seu comportamento á contorna, deberá recibir información sobre o mesmo. Isto faio mediante sensores: sensores de luz, sensores de contacto, sistema de visión artificial, etc.

Una vez que o robot reciba información da contorna, seleccionará e executará una das accións que pode levar a cabo (Ej: dar un paso cara adiante). En consecuencia, o robot recibirá un dato da idoneidade da acción. Este valor denomínase violencia.
Será positivo (premio) se a acción realizada ha conducido ao robot a unha situación máis favorable (sempre mellor respecto ao obxectivo que debe alcanzar) e negativo (penalización) se o deixou en peor situación que antes da execución da acción. O robot deberá gardar todas estas experiencias paira poder decidir en futuras ocasións a acción máis conveniente.
Aprender é saber decidir cal é a acción que ten que executar en cada momento paira maximizar o valor violento que vai recibir o robot. Supoñamos que temos un robot simple que se move a través de dúas rodas e que hai una fonte de luz na contorna, que queremos que o robot se mova a fonte de luz. Dispón de dous sensores de luz paira a recollida de información desde a contorna, uno dirixido á esquerda e outro á dereita. O robot pode realizar cinco tipos de actividades: parar, avanzar, retroceder, virar á esquerda e virar á dereita. Os sensores permiten distinguir tres situacións diferentes: a luminosidade xeral medida polo sensor da esquerda é maior, menor e igual que a da dereita.
Estando nestas circunstancias e con capacidade paira executar estas actividades, o robot comezará a moverse na contorna. A violencia á que se enfronta será un gran positivo si a luminosidade global medida na nova situación é superior á do paso anterior.
Así, a adaptación entre a situación e a acción que debe aprender o robot será:
- Se a luminosidade da esquerda é maior que a da dereita, virar á esquerda.
- Se a luminosidade da esquerda é menor que a da dereita, virar á dereita.
- Se a luminosidade da esquerda é a mesma que a da dereita, continuar.
Un algoritmo simple: estimación do intervalo
Este algoritmo baséase na estatística, concretamente na distribución de probabilidades de Bernoulli.
Na medida en que o robot actúe sobre a contorna, gardará a información recibida. Paira iso utiliza dúas táboas bidimensionales, cada una delas corresponde a un par de estados/acciones.
- Na primeira táboa móstrase o número de veces que se experimentou o par estado-acción.
- No segundo, recóllese o grao de conveniencia ou idoneidade do par estado-acción.
Cada vez que execute una acción na contorna actualizará ambas as táboas, engadindo na primeira a situación e o valor da casa correspondente a devanditas accións en 1 non e engadindo a violencia que reciba (positiva ou negativa) na casa correspondente da segunda táboa.
Con estas dúas táboas e utilizando os cálculos estatísticos pódese obter o intervalo de confianza estimado paira a probabilidade de que, estando o robot nunha situación, una acción executada consiga un valor violento 1. Con este intervalo, o algoritmo saberá que acción executar para que o comportamento mostrado polo robot sexa óptimo.
Robot Spanky
Este robot utiliza o algoritmo de estimación de intervalos. Móvese con dúas rodas. Dispón de catro sensores de luz paira obter información sobre o nivel de luminosidade e outros cinco sensores paira detectar obxectos da contorna. Ademais, o robot está rodeado dun sensor circular paira detectar posibles choques.
Todos estes dispositivos fan que o robot reciba información sobre a contorna en 5 bits.
- Bits 0,1: A maior luminosidade provén do robot.- 00: por diante - 01: desde a esquerda - 10: desde a dereita - 11: por detrás
- Bit 2: Atopou algún obxecto o sensor de impacto da dereita? Si ou non.
- Bit 3: Atopou algún obxecto o sensor de impacto da marxe esquerda? Si ou non.
- Bit 4: Polo menos uno dos tres sensores de choque centrais golpeou algún obxecto? Si ou non.
Segundo o comportamento do robot, os violentos que recibirá son:
- Se o robot golpeou algo: violencia negativa - Media da distribución: -2 - Desvío estándar: 0.5.
- Se o robot non se opuxo a nada: violencia positiva - Se luz (agora)> claridade (antes)* Media: 1* Desvío: 0.2- Luminosidade(agora) Claridade(antes) hora* Media: 0* Desvío: 0.2.
Con todo iso, o robot Spanky tenta non chocar contra os obxectos e avanzar cara á fonte de luz. Spanky púxose en marcha en máis de 20 ocasións. Foi capaz de aprender a mellor estratexia nun intervalo de 2-10 minutos.
Violencia recibida
O algoritmo visto modifica a conduta do robot en función da violencia recibida tras a acción.
Con todo, o que nos interesa é maximizar a suma de todas as violencias recollidas polo robot, e paira iso, ademais da violencia recibida tras cada acción, hai que ter en conta as que recibirá posteriormente. Quizais por outra acción non se perciba a maior violencia, pero a longo prazo, se se ten en conta a suma das violencias que se recibirían, será maior.
Hai algoritmos paira iso. O algoritmo denominado Q estudo é un deles e bastante bo. O algoritmo chámase aprendizaxe Q, xa que garda os valores Q. Que indican estes valores Q? O robot está no momento t e recibe o estado de entrada i. Dalgunha maneira decide executar a acción a en ese momento e recolle a violencia r.
Así as cousas, o robot supón que seguirá actuando coa mellor estratexia e espera recibir aos violentos r (1), r (2)... Estas r (j) que espera recibir máis tarde, j = 1..., teranse en conta, pero canto máis lonxe estea, menor será a incidencia. Isto conséguese grazas ao factor de desconto{ Inicialmente, o valor de{ estará próximo a 1 e será cada vez menor achegándoo a 0.
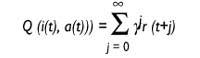
Valor Q: utilidade da acción a en situación i
onde
t: tiema{: factor de desconto 0 <{ < 1r(t): violencia recibida no instante t
O valor Q indica a utilidade de executar una acción nun estado.
Gardará un valor deste tipo paira cada parella de estados e accións. Irase completando una táboa coa experiencia do robot.
O robot ensaiará na contorna e gardará na súa táboa todos os resultados que reciba paira a súa posterior utilización.
O robot atópase nun momento dado en estado i e quere saber a utilidade desta situación. Cal é a acción que tería que executar nesta situación paira ser a máxima violencia que recibirá no futuro? Esta utilidade será o valor que teña a acción de maior valor Q paira esta situación e só decidirá levar a cabo dita acción.
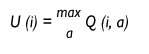
Utilidade da situación i.
Coa información que temos, temos suficiente paira construír un algoritmo de aprendizaxe eficaz. Este algoritmo actualiza continuamente os valores Q da táboa. Este é o seu traballo fundamental, por iso é polo que o robot derive o seu comportamento. O algoritmo modificará os valores da táboa da seguinte maneira:
Q (i (t), a (t)) = r (t) +{ Ou (t+1))

Supoñamos que estamos no momento t, o robot vese en estado i (t) e executa a acción a(t). Como consecuencia, atópase en situación i(t+1) e recibiu un r de violencia. Entón, o algoritmo dirixirase á táboa de valores Q e calculará a utilidade Ou (i (t +1) do novo estado i(t +1), tal e como se indicou anteriormente. Esta utilidade descontarase a través do parámetro{, paira engadila á violencia r (t) que acaba de recibir. Con todo, ten a utilidade da acción a (t) que acaba de executar e a garda na táboa onde corresponda paira a súa posterior utilización. Sabe como foi a acción a en o estado i, en que medida foi boa a súa execución.
Cando o robot empeza a actuar no mundo, os valores Q que garda na táboa non son moi significativos, pero o autor de leste algoritmo, Watkins, demostrou que o algoritmo achégase rapidamente aos valores reais Q. Una vez converxente, o robot aprendeu a moverse por esa contorna e sempre actuará seguindo a mellor estratexia. O algoritmo é dinámico e os valores Q da táboa van cambiando constantemente paira adaptarse a unha contorna potencialmente variable.
Que estás a pensar? A complexidade de computabilidad pode ser enorme? Pois si! Así é. O que non se pode...
O problema da complexidade de computabilidad é enorme. No caso do anterior robot Spanky, o estado de entrada vén expresado en 5 bits, é dicir, é capaz de diferenciar 25 = 32 estados diferentes. Por suposto, Spanky é só un robot de xoguete. Na práctica, o robot recibirá información do estado de entrada a través de máis bits e será capaz de executar máis accións diferentes. De que tamaño deberá utilizar o algoritmo? Tanto no espazo como no tempo, a combinación explótase.
Este algoritmo require que todas as situacións sexan definidas e, como vimos, o espazo requirido é enorme. Desgraciadamente non é o único problema.
Problemática da generalización dos estados de entrada
Analizando o comportamento do ser vivo, aínda que non sabe como actuar en novas situacións, podemos observar que utiliza una experiencia similar. Isto indícanos que Izaki é capaz de xeneralizar. Normalmente hai certa relación entre situacións e hai situacións moi similares. Se sabemos como actuar ante unha situación porque temos experiencia nesa situación, se nos atopamos nunha situación diferente e nova, actuariamos da mesma maneira.
Como pode o robot saber que una situación é similar a outra? Se puidese coñecelo, paira saber como actuar nas novas situacións utilizaría a experiencia de situacións similares paira crear accións similares.
Una forma de solucionar este problema é utilizar a distancia Hamming. A información sobre o estado do robot vén a través de series de bits. Pódese calcular a distancia Hamming entre estas series de bits, como o número de bits diferentes que teñen dúas secuencias de bits.

Xenial! Pódese superar o problema da generalización. Con todo, hai que gardar todas as situacións? O problema da explosión combinacional segue aí!
Paira superalo tamén se utilizaron grupos estatísticos. Con todo, aínda queda moito por facer.
Imos por bo camiño?
Que vos parece? Parece que hai cousas? Aínda que aínda non o mencionamos, hai un problema en todo isto.
En todos os algoritmos descritos supuxemos que o robot se atopa nun estado determinado e que una vez realizada una acción, sen ter en conta outra cousa, sabemos en que situación vaise a atopar no seguinte momento, é dicir, que a transición entre estados é o Markoviano. Pola contra, nunca tivemos en conta a situación na que nos atopamos antes de estar na situación actual e isto pode ser importante.
Supoñamos que o robot é rápido e que vai cara adiante a toda velocidade. Nun momento dado, debido a algún obstáculo na parte dianteira, tomarase a decisión de virar á dereita. En que situación atópase despois de virar? Segundo o noso algoritmo, dicimos que o robot describe o ángulo recto, pero sabemos que non é así. Os robots utilizados até agora son bastante lentos e o problema non foi moi evidente. Pero si seguimos así, darémonos conta de que imos mal, porque o que fai o robot e o que cre que o fai pode ser moi diferente.
Son moitos os problemas. Por suposto. Pero até agora os ensaios foron moi positivos e habemos visto que os robots poden converterse en bos estudantes. Só fai falta un pouco máis de traballo.
Zu idazle
Zientzia aldizkaria

