

¿Los robots son capaces de aprender?
¿Por qué los robots necesitan aprender?
En el día a día realizamos muchas actividades sin apenas tener que pensar. Por ejemplo, nos parece totalmente normal entrar en una habitación que no conocemos y caminar sin tocar los objetos de esa habitación.

Sea cual sea el entorno, el robot también debe ser capaz de conseguir su objetivo si queremos hacer algún trabajo útil. Teniendo en cuenta la alta capacidad de computabilidad de las computadoras actuales, ¿por qué no proporcionar al robot una descripción detallada del entorno? Utilizando esta descripción, el robot será capaz de llevar a cabo su cometido sin necesidad de aprender cómo es y cómo debe actuar en el entorno.
Todo esto podía ser posible en un mundo artificial de juguete, pero no en entornos de vida real. No podremos proporcionar al robot una descripción detallada del entorno, ya que puede resultar demasiado complejo o porque el entorno no lo conocemos previamente. Tal vez querremos que este robot sea capaz de trabajar en más de un entorno. ¿Y si el entorno fuera dinámico o cambiante? ¿Si la gente retrocediera y siguiera allí? ¿Cómo programar el robot para trabajar en estos entornos?
Está claro, por tanto, que para que nos ayude en la vida real, el robot debe ser capaz de adaptarse al entorno en el que va a trabajar, es decir, de aprender a trabajar en ese entorno. Cuando hemos aprendido, queremos decir que el robot debe ser capaz de mejorar su comportamiento haciéndolo más apropiado al entorno en el que se encuentra.
Aprendizaje violento
En inteligencia artificial son muchos los métodos utilizados para aprender. El método de aprendizaje que se pretende analizar aquí es el aprendizaje a través de la violencia, cuyo nombre deriva del valor denominado violencia. Analicemos paso a paso el proceso de aprendizaje para entender qué es la violencia.
Para que el robot adapte su comportamiento al entorno, deberá recibir información sobre el mismo. Esto lo hace mediante sensores: sensores de luz, sensores de contacto, sistema de visión artificial, etc.

Una vez que el robot reciba información del entorno, seleccionará y ejecutará una de las acciones que puede llevar a cabo (Ej: dar un paso hacia delante). En consecuencia, el robot recibirá un dato de la idoneidad de la acción. Este valor se denomina violencia.
Será positivo (premio) si la acción realizada ha conducido al robot a una situación más favorable (siempre mejor respecto al objetivo que debe alcanzar) y negativo (penalización) si lo ha dejado en peor situación que antes de la ejecución de la acción. El robot deberá guardar todas estas experiencias para poder decidir en futuras ocasiones la acción más conveniente.
Aprender es saber decidir cuál es la acción que tiene que ejecutar en cada momento para maximizar el valor violento que va a recibir el robot. Supongamos que tenemos un robot simple que se mueve a través de dos ruedas y que hay una fuente de luz en el entorno, que queremos que el robot se mueva la fuente de luz. Dispone de dos sensores de luz para la recogida de información desde el entorno, uno dirigido a la izquierda y otro a la derecha. El robot puede realizar cinco tipos de actividades: parar, avanzar, retroceder, girar a la izquierda y girar a la derecha. Los sensores permiten distinguir tres situaciones diferentes: la luminosidad general medida por el sensor de la izquierda es mayor, menor e igual que la de la derecha.
Estando en estas circunstancias y con capacidad para ejecutar estas actividades, el robot comenzará a moverse en el entorno. La violencia a la que se enfrenta será un gran positivo si la luminosidad global medida en la nueva situación es superior a la del paso anterior.
Así, la adaptación entre la situación y la acción que debe aprender el robot será:
- Si la luminosidad de la izquierda es mayor que la de la derecha, girar a la izquierda.
- Si la luminosidad de la izquierda es menor que la de la derecha, girar a la derecha.
- Si la luminosidad de la izquierda es la misma que la de la derecha, continuar.
Un algoritmo simple: estimación del intervalo
Este algoritmo se basa en la estadística, concretamente en la distribución de probabilidades de Bernoulli.
En la medida en que el robot actúe sobre el entorno, guardará la información recibida. Para ello utiliza dos tablas bidimensionales, cada una de ellas corresponde a un par de estados/acciones.
- En la primera tabla se muestra el número de veces que se ha experimentado el par estado-acción.
- En el segundo, se recoge el grado de conveniencia o idoneidad del par estado-acción.
Cada vez que ejecute una acción en el entorno actualizará ambas tablas, añadiendo en la primera la situación y el valor de la casilla correspondiente a dichas acciones en 1 no y añadiendo la violencia que reciba (positiva o negativa) en la casilla correspondiente de la segunda tabla.
Con estas dos tablas y utilizando los cálculos estadísticos se puede obtener el intervalo de confianza estimado para la probabilidad de que, estando el robot en una situación, una acción ejecutada consiga un valor violento 1. Con este intervalo, el algoritmo sabrá qué acción ejecutar para que el comportamiento mostrado por el robot sea óptimo.
Robot Spanky
Este robot utiliza el algoritmo de estimación de intervalos. Se mueve con dos ruedas. Dispone de cuatro sensores de luz para obtener información sobre el nivel de luminosidad y otros cinco sensores para detectar objetos del entorno. Además, el robot está rodeado de un sensor circular para detectar posibles choques.
Todos estos dispositivos hacen que el robot reciba información sobre el entorno en 5 bits.
- Bits 0,1: La mayor luminosidad proviene del robot.- 00: por delante - 01: desde la izquierda - 10: desde la derecha - 11: por detrás
- Bit 2: ¿Ha encontrado algún objeto el sensor de impacto de la derecha? Sí o no.
- Bit 3: ¿Ha encontrado algún objeto el sensor de impacto de la margen izquierda? Sí o no.
- Bit 4: ¿Al menos uno de los tres sensores de choque centrales ha golpeado algún objeto? Sí o no.
Según el comportamiento del robot, los violentos que recibirá son:
- Si el robot ha golpeado algo: violencia negativa - Media de la distribución: -2 - Desvío estándar: 0.5.
- Si el robot no se ha opuesto a nada: violencia positiva - Si luz (ahora)> claridad (antes)* Media: 1* Desvío: 0.2- Luminosidad(ahora) Claridad(antes) hora* Media: 0* Desvío: 0.2.
Con todo ello, el robot Spanky intenta no chocar contra los objetos y avanzar hacia la fuente de luz. Spanky se puso en marcha en más de 20 ocasiones. Fue capaz de aprender la mejor estrategia en un intervalo de 2-10 minutos.
Violencia recibida
El algoritmo visto modifica la conducta del robot en función de la violencia recibida tras la acción.
Sin embargo, lo que nos interesa es maximizar la suma de todas las violencias recogidas por el robot, y para ello, además de la violencia recibida tras cada acción, hay que tener en cuenta las que recibirá posteriormente. Quizás por otra acción no se perciba la mayor violencia, pero a largo plazo, si se tiene en cuenta la suma de las violencias que se recibirían, será mayor.
Hay algoritmos para ello. El algoritmo denominado Q estudio es uno de ellos y bastante bueno. El algoritmo se llama aprendizaje Q, ya que guarda los valores Q. ¿Qué indican estos valores Q? El robot está en el momento t y recibe el estado de entrada i. De alguna manera decide ejecutar la acción a en ese momento y recoge la violencia r.
Así las cosas, el robot supone que seguirá actuando con la mejor estrategia y espera recibir a los violentos r (1), r (2)... Estas r (j) que espera recibir más tarde, j = 1..., se tendrán en cuenta, pero cuanto más lejos esté, menor será la incidencia. Esto se consigue gracias al factor de descuento{ Inicialmente, el valor de{ estará próximo a 1 y será cada vez menor acercándolo a 0.
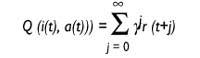
Valor Q: utilidad de la acción a en situación i
donde
t: tiema{: factor de descuento 0 <{ < 1r(t): violencia recibida en el instante t
El valor Q indica la utilidad de ejecutar una acción en un estado.
Guardará un valor de este tipo para cada pareja de estados y acciones. Se irá completando una tabla con la experiencia del robot.
El robot ensayará en el entorno y guardará en su tabla todos los resultados que reciba para su posterior utilización.
El robot se encuentra en un momento dado en estado i y quiere saber la utilidad de esta situación. ¿Cuál es la acción que tendría que ejecutar en esta situación para ser la máxima violencia que recibirá en el futuro? Esta utilidad será el valor que tenga la acción de mayor valor Q para esta situación y sólo decidirá llevar a cabo dicha acción.
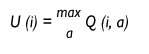
Utilidad de la situación i.
Con la información que tenemos, tenemos suficiente para construir un algoritmo de aprendizaje eficaz. Este algoritmo actualiza continuamente los valores Q de la tabla. Este es su trabajo fundamental, de ahí que el robot derive su comportamiento. El algoritmo modificará los valores de la tabla de la siguiente manera:
Q (i (t), a (t)) = r (t) +{ U (t+1))

Supongamos que estamos en el momento t, el robot se ve en estado i (t) y ejecuta la acción a(t). Como consecuencia, se encuentra en situación i(t+1) y ha recibido un r de violencia. Entonces, el algoritmo se dirigirá a la tabla de valores Q y calculará la utilidad U (i (t +1) del nuevo estado i(t +1), tal y como se ha indicado anteriormente. Esta utilidad se descontará a través del parámetro{, para añadirla a la violencia r (t) que acaba de recibir. Con todo, tiene la utilidad de la acción a (t) que acaba de ejecutar y la guarda en la tabla donde corresponda para su posterior utilización. Sabe cómo ha ido la acción a en el estado i, en qué medida ha sido buena su ejecución.
Cuando el robot empieza a actuar en el mundo, los valores Q que guarda en la tabla no son muy significativos, pero el autor de este algoritmo, Watkins, demostró que el algoritmo se acerca rápidamente a los valores reales Q. Una vez convergente, el robot ha aprendido a moverse por ese entorno y siempre actuará siguiendo la mejor estrategia. El algoritmo es dinámico y los valores Q de la tabla van cambiando constantemente para adaptarse a un entorno potencialmente variable.
¿Qué estás pensando? ¿La complejidad de computabilidad puede ser enorme? ¡Pues sí! Así es. Lo que no se puede...
El problema de la complejidad de computabilidad es enorme. En el caso del anterior robot Spanky, el estado de entrada viene expresado en 5 bits, es decir, es capaz de diferenciar 25 = 32 estados diferentes. Por supuesto, Spanky es sólo un robot de juguete. En la práctica, el robot recibirá información del estado de entrada a través de más bits y será capaz de ejecutar más acciones diferentes. ¿De qué tamaño deberá utilizar el algoritmo? Tanto en el espacio como en el tiempo, la combinación se explota.
Este algoritmo requiere que todas las situaciones sean definidas y, como hemos visto, el espacio requerido es enorme. Desgraciadamente no es el único problema.
Problemática de la generalización de los estados de entrada
Analizando el comportamiento del ser vivo, aunque no sabe cómo actuar en nuevas situaciones, podemos observar que utiliza una experiencia similar. Esto nos indica que Izaki es capaz de generalizar. Normalmente hay cierta relación entre situaciones y hay situaciones muy similares. Si sabemos cómo actuar ante una situación porque tenemos experiencia en esa situación, si nos encontramos en una situación diferente y nueva, actuaríamos de la misma manera.
¿Cómo puede el robot saber que una situación es similar a otra? Si pudiera conocerlo, para saber cómo actuar en las nuevas situaciones utilizaría la experiencia de situaciones similares para crear acciones similares.
Una forma de solucionar este problema es utilizar la distancia Hamming. La información sobre el estado del robot viene a través de series de bits. Se puede calcular la distancia Hamming entre estas series de bits, como el número de bits diferentes que tienen dos secuencias de bits.

¡Genial! Se puede superar el problema de la generalización. Sin embargo, ¿hay que guardar todas las situaciones? ¡El problema de la explosión combinacional sigue ahí!
Para superarlo también se han utilizado grupos estadísticos. Sin embargo, todavía queda mucho por hacer.
¿Vamos por buen camino?
¿Qué os parece? ¿Parece que hay cosas? Aunque todavía no lo hemos mencionado, hay un problema en todo esto.
En todos los algoritmos descritos hemos supuesto que el robot se encuentra en un estado determinado y que una vez realizada una acción, sin tener en cuenta otra cosa, sabemos en qué situación se va a encontrar en el siguiente momento, es decir, que la transición entre estados es el Markoviano. Por el contrario, nunca hemos tenido en cuenta la situación en la que nos encontramos antes de estar en la situación actual y esto puede ser importante.
Supongamos que el robot es rápido y que va hacia delante a toda velocidad. En un momento dado, debido a algún obstáculo en la parte delantera, se tomará la decisión de girar a la derecha. ¿En qué situación se encuentra después de girar? Según nuestro algoritmo, decimos que el robot describe el ángulo recto, pero sabemos que no es así. Los robots utilizados hasta ahora son bastante lentos y el problema no ha sido muy evidente. Pero si seguimos así, nos daremos cuenta de que vamos mal, porque lo que hace el robot y lo que cree que lo hace puede ser muy diferente.
Son muchos los problemas. Por supuesto. Pero hasta ahora los ensayos han sido muy positivos y hemos visto que los robots pueden convertirse en buenos estudiantes. Sólo hace falta un poco más de trabajo.
Zu idazle
Zientzia aldizkaria

