

Els robots són capaços d'aprendre?
Per què els robots necessiten aprendre?
En el dia a dia realitzem moltes activitats sense tot just haver de pensar. Per exemple, ens sembla totalment normal entrar en una habitació que no coneixem i caminar sense tocar els objectes d'aquesta habitació.

Sigui com sigui l'entorn, el robot també ha de ser capaç d'aconseguir el seu objectiu si volem fer algun treball útil. Tenint en compte l'alta capacitat de computabilidad de les computadores actuals, per què no proporcionar al robot una descripció detallada de l'entorn? Utilitzant aquesta descripció, el robot serà capaç de dur a terme la seva comesa sense necessitat d'aprendre com és i com ha d'actuar en l'entorn.
Tot això podia ser possible en un món artificial de joguina, però no en entorns de vida real. No podrem proporcionar al robot una descripció detallada de l'entorn, ja que pot resultar massa complex o perquè l'entorn no el coneixem prèviament. Tal vegada voldrem que aquest robot sigui capaç de treballar en més d'un entorn. I si l'entorn fos dinàmic o canviant? Si la gent retrocedís i seguís allí? Com programar el robot per a treballar en aquests entorns?
És clar, per tant, que perquè ens ajudi en la vida real, el robot ha de ser capaç d'adaptar-se a l'entorn en el qual treballarà, és a dir, d'aprendre a treballar en aquest entorn. Quan hem après, volem dir que el robot ha de ser capaç de millorar el seu comportament fent-lo més apropiat a l'entorn en el qual es troba.
Aprenentatge violent
En intel·ligència artificial són molts els mètodes utilitzats per a aprendre. El mètode d'aprenentatge que es pretén analitzar aquí és l'aprenentatge a través de la violència, el nom de la qual deriva del valor denominat violència. Analitzem pas a pas el procés d'aprenentatge per a entendre què és la violència.
Perquè el robot adapti el seu comportament a l'entorn, haurà de rebre informació sobre aquest. Això ho fa mitjançant sensors: sensors de llum, sensors de contacte, sistema de visió artificial, etc.

Una vegada que el robot rebi informació de l'entorn, seleccionarà i executarà una de les accions que pot dur a terme (Ej: fer un pas cap endavant). En conseqüència, el robot rebrà una dada de la idoneïtat de l'acció. Aquest valor es denomina violència.
Serà positiu (premi) si l'acció realitzada ha conduït al robot a una situació més favorable (sempre millor respecte a l'objectiu que ha d'aconseguir) i negatiu (penalització) si ho ha deixat en pitjor situació que abans de l'execució de l'acció. El robot haurà de guardar totes aquestes experiències per a poder decidir en futures ocasions l'acció més convenient.
Aprendre és saber decidir quina és l'acció que ha d'executar a cada moment per a maximitzar el valor violent que rebrà el robot. Suposem que tenim un robot simple que es mou a través de dues rodes i que hi ha una font de llum en l'entorn, que volem que el robot es mogui la font de llum. Disposa de dos sensors de llum per a la recollida d'informació des de l'entorn, un dirigit a l'esquerra i un altre a la dreta. El robot pot realitzar cinc tipus d'activitats: parar, avançar, retrocedir, girar a l'esquerra i girar a la dreta. Els sensors permeten distingir tres situacions diferents: la lluminositat general mesura pel sensor de l'esquerra és major, menor i igual que la de la dreta.
Estant en aquestes circumstàncies i amb capacitat per a executar aquestes activitats, el robot començarà a moure's en l'entorn. La violència a la qual s'enfronta serà un gran positiu si la lluminositat global mesura en la nova situació és superior a la del pas anterior.
Així, l'adaptació entre la situació i l'acció que ha d'aprendre el robot serà:
- Si la lluminositat de l'esquerra és major que la de la dreta, girar a l'esquerra.
- Si la lluminositat de l'esquerra és menor que la de la dreta, girar a la dreta.
- Si la lluminositat de l'esquerra és la mateixa que la de la dreta, continuar.
Un algorisme simple: estimació de l'interval
Aquest algorisme es basa en l'estadística, concretament en la distribució de probabilitats de Bernoulli.
En la mesura en què el robot actuï sobre l'entorn, guardarà la informació rebuda. Per a això utilitza dues taules bidimensionals, cadascuna d'elles correspon a un parell d'estats/accionis.
- En la primera taula es mostra el nombre de vegades que s'ha experimentat el parell estat-acció.
- En el segon, es recull el grau de conveniència o idoneïtat del parell estat-acció.
Cada vegada que executi una acció en l'entorn actualitzarà totes dues taules, afegint en la primera la situació i el valor de la casella corresponent a aquestes accions en 1 no i afegint la violència que rebi (positiva o negativa) en la casella corresponent de la segona taula.
Amb aquestes dues taules i utilitzant els càlculs estadístics es pot obtenir l'interval de confiança estimat per a la probabilitat que, estant el robot en una situació, una acció executada aconsegueixi un valor violent 1. Amb aquest interval, l'algorisme sabrà quina acció executar perquè el comportament mostrat pel robot sigui òptim.
Robot Spanky
Aquest robot utilitza l'algorisme d'estimació d'intervals. Es mou amb dues rodes. Disposa de quatre sensors de llum per a obtenir informació sobre el nivell de lluminositat i altres cinc sensors per a detectar objectes de l'entorn. A més, el robot està envoltat d'un sensor circular per a detectar possibles xocs.
Tots aquests dispositius fan que el robot rebi informació sobre l'entorn en 5 bits.
- Bits 0,1: La major lluminositat prové del robot.- 00: per davant -
01: des de l'esquerra -
10: des de la dreta -
11: per darrere - Bit 2: Ha trobat algun objecte el sensor d'impacte de la dreta? Sí o no.
- Bit 3: Ha trobat algun objecte el sensor d'impacte del marge esquerre? Sí o no.
- Bit 4: Almenys un dels tres sensors de xoc centrals ha colpejat algun objecte? Sí o no.
Segons el comportament del robot, els violents que rebrà són:
- Si el robot ha colpejat alguna cosa: violència negativa
- Mitjana de la distribució: -2
- Desviament estàndard: 0.5. - Si el robot no s'ha oposat a res: violència positiva - Si
llum (ara)> claredat (abans)* Mitjana:
1*
Desviament: 0.2-
Lluminositat(ara) Claredat(abans) hora* Mitjana:
0*
Desviament: 0.2.
Amb tot això, el robot Spanky intenta no xocar contra els objectes i avançar cap a la font de llum. Spanky es va posar en marxa en més de 20 ocasions. Va ser capaç d'aprendre la millor estratègia en un interval de 2-10 minuts.
Violència rebuda
L'algorisme vist modifica la conducta del robot en funció de la violència rebuda després de l'acció.
No obstant això, el que ens interessa és maximitzar la suma de totes les violències recollides pel robot, i per a això, a més de la violència rebuda després de cada acció, cal tenir en compte les que rebrà posteriorment. Potser per una altra acció no es percep la major violència, però a llarg termini, si es té en compte la suma de les violències que es rebrien, serà major.
Hi ha algorismes per a això. L'algorisme denominat Q estudio és un d'ells i bastant bo. L'algorisme es diu aprenentatge Q, ja que guarda els valoris Q. Què indiquen aquests valoris Q? El robot està en el moment t i rep l'estat d'entrada i. D'alguna manera decideix executar l'acció a en aquest moment i recull la violència r.
Així les coses, el robot suposa que continuarà actuant amb la millor estratègia i espera rebre als violents r (1), r (2)... Aquestes r (j) que espera rebre més tard , j = 1..., es tindran en compte, però com més lluny estigui, menor serà la incidència. Això s'aconsegueix gràcies al factor de descompte{ Inicialment, el valor de{ estarà pròxim a 1 i serà cada vegada menor acostant-ho a 0.
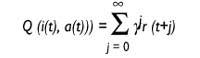
Valor Q: utilitat de l'acció a en situació i
on
t: tiema{: factor de descompte
0 <{ < 1r(t): violència rebuda
en l'instant t
El valor Q indica la utilitat d'executar una acció en un estat.
Guardarà un valor d'aquest tipus per a cada parella d'estats i accions. S'anirà completant una taula amb l'experiència del robot.
El robot assajarà en l'entorn i guardarà en la seva taula tots els resultats que rebi per a la seva posterior utilització.
El robot es troba en un moment donat en estat i i vol saber la utilitat d'aquesta situació. Quina és l'acció que hauria d'executar en aquesta situació per a ser la màxima violència que rebrà en el futur? Aquesta utilitat serà el valor que tingui l'acció de major valor Q per a aquesta situació i només decidirà dur a terme aquesta acció.
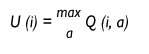
Utilitat de la situació i.
Amb la informació que tenim, tenim suficient per a construir un algorisme d'aprenentatge eficaç. Aquest algorisme actualitza contínuament els valoris Q de la taula. Aquest és el seu treball fonamental, per aquest motiu el robot derivi el seu comportament. L'algorisme modificarà els valors de la taula de la següent manera:
Q (i (t), a (t)) = r (t) +{ O (t+1))

Suposem que estem en el moment t, el robot es veu en estat i (t) i executa l'acció a(t). Com a conseqüència, es troba en situació i(t+1) i ha rebut un r de violència. Llavors, l'algorisme es dirigirà a la taula de valors Q i calcularà la utilitat O (i (t +1) del nou estat i(t +1), tal com s'ha indicat anteriorment. Aquesta utilitat es descomptarà a través del paràmetre{, per a afegir-la a la violència r (t) que acaba de rebre. Amb tot, té la utilitat de l'acció a (t) que acaba d'executar i la guarda en la taula on correspongui per a la seva posterior utilització. Sap com ha anat l'acció a en l'estat i, en quina mesura ha estat bona la seva execució.
Quan el robot comença a actuar en el món, els valoris Q que guarda en la taula no són molt significatius, però l'autor d'aquest algorisme, Watkins, va demostrar que l'algorisme s'acosta ràpidament als valors reals Q. Una vegada convergent, el robot ha après a moure's per aquest entorn i sempre actuarà seguint la millor estratègia. L'algorisme és dinàmic i els valors Q de la taula van canviant constantment per a adaptar-se a un entorn potencialment variable.
Què estàs pensant? La complexitat de computabilidad pot ser enorme? Doncs sí! Així és. El que no es pot...
El problema de la complexitat de computabilidad és enorme. En el cas de l'anterior robot Spanky, l'estat d'entrada ve expressat en 5 bits, és a dir, és capaç de diferenciar 25 = 32 estats diferents. Per descomptat, Spanky és només un robot de joguina. En la pràctica, el robot rebrà informació de l'estat d'entrada a través de més bits i serà capaç d'executar més accions diferents. De quina grandària haurà d'utilitzar l'algorisme? Tant en l'espai com en el temps, la combinació s'explota.
Aquest algorisme requereix que totes les situacions siguin definides i, com hem vist, l'espai requerit és enorme. Desgraciadament no és l'únic problema.
Problemàtica de la generalització dels estats d'entrada
Analitzant el comportament de l'ésser viu, encara que no sap com actuar en noves situacions, podem observar que utilitza una experiència similar. Això ens indica que Izaki és capaç de generalitzar. Normalment hi ha certa relació entre situacions i hi ha situacions molt similars. Si sabem com actuar davant una situació perquè tenim experiència en aquesta situació, si ens trobem en una situació diferent i nova, actuaríem de la mateixa manera.
Com pot el robot saber que una situació és similar a una altra? Si pogués conèixer-ho, per a saber com actuar en les noves situacions utilitzaria l'experiència de situacions similars per a crear accions similars.
Una manera de solucionar aquest problema és utilitzar la distància Hamming. La informació sobre l'estat del robot ve a través de sèries de bits. Es pot calcular la distància Hamming entre aquestes sèries de bits, com el nombre de bits diferents que tenen dues seqüències de bits.

Genial! Es pot superar el problema de la generalització. No obstant això, cal guardar totes les situacions? El problema de l'explosió combinacional segueix aquí!
Per a superar-ho també s'han utilitzat grups estadístics. No obstant això, encara queda molt per fer.
Anem per bon camí?
Què us sembla? Sembla que hi ha coses? Encara que encara no ho hem esmentat, hi ha un problema en tot això.
En tots els algorismes descrits hem suposat que el robot es troba en un estat determinat i que una vegada realitzada una acció, sense tenir en compte una altra cosa, sabem en quina situació es trobarà en el següent moment, és a dir, que la transició entre estats és el Markoviano. Per contra, mai hem tingut en compte la situació en la qual ens trobem abans d'estar en la situació actual i això pot ser important.
Suposem que el robot és ràpid i que va cap endavant a tota velocitat. En un moment donat, a causa d'algun obstacle en la part davantera, es prendrà la decisió de girar a la dreta. En quina situació es troba després de girar? Segons el nostre algorisme, diem que el robot descriu l'angle recte, però sabem que no és així. Els robots utilitzats fins ara són bastant lents i el problema no ha estat molt evident. Però si seguim així, ens adonarem que anem malament, perquè el que fa el robot i el que creu que ho fa pot ser molt diferent.
Són molts els problemes. Per descomptat. Però fins ara els assajos han estat molt positius i hem vist que els robots poden convertir-se en bons estudiants. Només fa falta una mica més de treball.
Zu idazle
Zientzia aldizkaria

