

Les robots sont-ils capables d'apprendre ?
Pourquoi les robots doivent-ils apprendre ?
Au jour le jour nous réalisons beaucoup d'activités sans juste devoir penser. Par exemple, il nous semble tout à fait normal d'entrer dans une pièce que nous ne connaissons pas et marcher sans toucher les objets de cette pièce.

Quel que soit l'environnement, le robot doit également être en mesure d'atteindre son objectif si nous voulons faire un travail utile. Compte tenu de la capacité de calcul élevée des ordinateurs actuels, pourquoi ne pas fournir au robot une description détaillée de l'environnement? En utilisant cette description, le robot sera en mesure d'accomplir sa tâche sans avoir besoin d'apprendre comment il est et comment il doit agir dans l'environnement.
Tout cela pouvait être possible dans un monde artificiel de jouet, mais pas dans des environnements de vie réelle. Nous ne pouvons pas fournir au robot une description détaillée de l'environnement, car il peut être trop complexe ou parce que l'environnement nous ne le connaissons pas auparavant. Peut-être que nous voulons que ce robot soit capable de travailler dans plus d'un environnement. Et si l'environnement était dynamique ou changeant ? Si les gens reculaient et restaient là ? Comment programmer le robot pour travailler dans ces environnements ?
Il est donc clair que pour nous aider dans la vie réelle, le robot doit être en mesure de s'adapter à l'environnement dans lequel il va travailler, à savoir apprendre à travailler dans cet environnement. Lorsque nous avons appris, nous voulons dire que le robot doit être en mesure d'améliorer son comportement en le rendant plus approprié à l'environnement dans lequel il se trouve.
Apprentissage violent
Dans l'intelligence artificielle sont nombreuses méthodes utilisées pour apprendre. La méthode d'apprentissage que l'on prétend analyser ici est l'apprentissage par la violence, dont le nom dérive de la valeur appelée violence. Analysons pas à pas le processus d'apprentissage pour comprendre ce qu'est la violence.
Pour que le robot adapte son comportement à l'environnement, vous devez recevoir des informations sur celui-ci. Cela se fait par des capteurs : capteurs de lumière, capteurs de contact, système de vision artificielle, etc.

Une fois que le robot reçoit des informations sur l'environnement, il sélectionne et exécute l'une des actions qu'il peut effectuer (ex: faire un pas en avant). Par conséquent, le robot recevra une donnée de l'adéquation de l'action. Cette valeur est appelée violence.
Ce sera positif (prix) si l'action effectuée a conduit le robot à une situation plus favorable (toujours mieux par rapport à l'objectif à atteindre) et négatif (pénalité) s'il l'a laissé en pire situation qu'avant l'exécution de l'action. Le robot doit garder toutes ces expériences pour pouvoir décider à l'avenir de l'action la plus commode.
Apprendre est de savoir décider quelle est l'action que vous devez exécuter à tout moment pour maximiser la valeur violente que le robot recevra. Supposons que nous ayons un robot simple qui se déplace à travers deux roues et qu'il y a une source de lumière dans l'environnement, que nous voulons que le robot bouge la source de lumière. Il dispose de deux capteurs de lumière pour la collecte d'informations depuis l'environnement, l'un à gauche et l'autre à droite. Le robot peut effectuer cinq types d'activités : arrêter, avancer, reculer, tourner à gauche et tourner à droite. Les capteurs permettent de distinguer trois situations différentes : la luminosité générale mesurée par le capteur de gauche est supérieure, inférieure et égale à celle de droite.
Étant dans ces circonstances et capable d'exécuter ces activités, le robot commencera à se déplacer dans l'environnement. La violence à laquelle il est confronté sera un grand positif si la luminosité globale mesurée dans la nouvelle situation est supérieure à celle de l'étape précédente.
Ainsi, l'adaptation entre la situation et l'action que doit apprendre le robot sera:
- Si la luminosité de gauche est supérieure à celle de droite, tourner à gauche.
- Si la luminosité de la gauche est inférieure à celle de la droite, tourner à droite.
- Si la luminosité de la gauche est la même que celle de la droite, continuer.
Un algorithme simple : estimation de l'intervalle
Cet algorithme est basé sur les statistiques, en particulier sur la répartition des probabilités de Bernoulli.
Dans la mesure où le robot agit sur l'environnement, il conserve les informations reçues. Pour cela, il utilise deux tables bidimensionnelles, chacune d'elles correspond à une paire d'états/actions.
- Le premier tableau montre le nombre de fois où le couple état-action a été expérimenté.
- Dans le second, il recueille le degré de convenance ou d'adéquation du couple état-action.
Chaque fois que vous exécutez une action dans l'environnement, vous mettrez à jour les deux tables, en ajoutant la situation et la valeur de la case correspondant à ces actions dans 1 non et en ajoutant la violence que vous recevez (positive ou négative) dans la case correspondante du second tableau.
Avec ces deux tables et en utilisant les calculs statistiques on peut obtenir l'intervalle de confiance estimé pour la probabilité que, étant le robot dans une situation, une action exécutée obtienne une valeur violente 1. Avec cet intervalle, l'algorithme saura quelle action exécuter pour que le comportement affiché par le robot soit optimal.
Robot Spanky
Ce robot utilise l'algorithme d'estimation des intervalles. Il se déplace avec deux roues. Il dispose de quatre capteurs de lumière pour des informations sur le niveau de luminosité et cinq autres capteurs pour détecter les objets environnants. En outre, le robot est entouré d'un capteur circulaire pour détecter les chocs potentiels.
Tous ces dispositifs permettent au robot de recevoir des informations sur l'environnement en 5 bits.
- Bits 0,1: La plus grande luminosité provient du robot.- 00: devant -
01: de gauche -
10: de droite -
11: derrière - Bit 2: Le capteur d'impact de droite a-t-il trouvé un objet ? Oui ou non.
- Bit 3: Le capteur d'impact de la rive gauche a-t-il trouvé un objet ? Oui ou non.
- Bit 4: Au moins un des trois capteurs de choc centraux a-t-il frappé un objet ? Oui ou non.
Selon le comportement du robot, les violents que vous recevrez sont:
- Si le robot a frappé quelque chose : violence
négative - Moyenne de distribution : -2
- Déviation standard: 0.5. - Si le robot ne s'est opposé à rien: violence positive - Si
lumière (maintenant) clarté (avant)* Moyenne:
1*
Déviation: 0.2-
Luminosité(maintenant) Clarté(avant) heure* Moyenne:
0*
Déviation: 0.2.
Avec tout cela, le robot Spanky tente de ne pas heurter les objets et avancer vers la source de lumière. Spanky a été lancé à plus de 20 reprises. Il a pu apprendre la meilleure stratégie dans un intervalle de 2-10 minutes.
Violence reçue
L'algorithme vu modifie le comportement du robot en fonction de la violence reçue après l'action.
Cependant, ce qui nous intéresse est de maximiser la somme de toutes les violences recueillies par le robot, et pour cela, en plus de la violence reçue après chaque action, il faut tenir compte de celles qu'il recevra par la suite. Peut-être par une autre action on ne perçoit pas la plus grande violence, mais à long terme, si l'on tient compte de la somme des violences qui seraient reçues, ce sera plus grand.
Il y a des algorithmes pour cela. L'algorithme appelé Q étude est l'un d'eux et assez bon. L'algorithme est appelé apprentissage Q, car il enregistre les valeurs Q. Que signifient ces valeurs Q ? Le robot est au moment t et reçoit l'état d'entrée i. En quelque sorte, il décide d'exécuter l'action à ce moment-là et recueille la violence r.
Ainsi, le robot suppose qu'il continuera à agir avec la meilleure stratégie et espère recevoir les violents r (1), r (2)... Ces r (j) qu'il espère recevoir plus tard, j = 1..., seront pris en compte, mais plus il est loin, plus l'incidence est faible. Ceci est réalisé grâce au facteur d'actualisation de la variable Au départ, la valeur de{ sera proche de 1 et sera de moins en moins proche de 0.
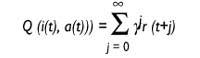
Valeur Q : utilité de l'action a en situation i
où
t: tiema{: facteur
d'escompte 0 polluants 1r(t): violence reçue
à l'instant t
La valeur Q indique l'utilité d'exécuter une action dans un état.
Il conservera une valeur de ce type pour chaque paire d'états et d'actions. Une table avec l'expérience du robot sera complétée.
Le robot testera dans l'environnement et enregistrera dans son tableau tous les résultats qu'il reçoit pour une utilisation ultérieure.
Le robot est à un moment donné dans l'état i et veut savoir l'utilité de cette situation. Quelle est l'action que vous devrez exécuter dans cette situation pour être la violence maximale que vous recevrez à l'avenir? Cet utilitaire sera la valeur que vous avez l'action de la plus grande valeur Q pour cette situation et ne décidera de mener à bien cette action.
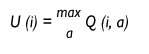
Utilité de la situation i.
Avec les informations que nous avons, nous avons assez pour construire un algorithme d'apprentissage efficace. Cet algorithme met à jour en permanence les valeurs Q de la table. C'est son travail fondamental, d'où le robot tire son comportement. L'algorithme modifiera les valeurs de la table comme suit:
Q (i (t), a (t)) = r (t) +{ U (t+1)))

Supposons que nous sommes au moment t, le robot est vu dans l'état i (t) et exécute l'action a(t). En conséquence, il est en situation i(t+1) et a reçu une violence. L'algorithme sera alors dirigé vers la table de valeurs Q et calculera l'utilitaire U (i (t +1) du nouvel état i(t +1), comme indiqué ci-dessus. Cet utilitaire sera déduit via le paramètre{, pour l'ajouter à la violence r (t) que vous venez de recevoir. Cependant, elle a l'utilité de l'action a (t) que vous venez d'exécuter et la garde dans la table où elle correspond à son utilisation ultérieure. Il sait comment l'action a disparu dans l'état i, dans quelle mesure son exécution a été bonne.
Lorsque le robot commence à agir dans le monde, les valeurs Q stockées dans le tableau ne sont pas très importantes, mais l'auteur de cet algorithme, Watkins, a montré que l'algorithme se rapproche rapidement des valeurs réelles Q. Une fois convergent, le robot a appris à se déplacer dans cet environnement et agira toujours en suivant la meilleure stratégie. L'algorithme est dynamique et les valeurs Q de la table changent constamment pour s'adapter à un environnement potentiellement variable.
Que pensez-vous ? La complexité informatique peut-elle être énorme ? Eh oui! C'est vrai. Ce que vous ne pouvez pas...
Le problème de la complexité informatique est énorme. Dans le cas de l'ancien robot Spanky, l'état d'entrée est exprimé en 5 bits, c'est-à-dire qu'il est capable de différencier 25 = 32 états différents. Bien sûr, Spanky est juste un robot jouet. Dans la pratique, le robot recevra des informations sur l'état d'entrée à travers plus de bits et sera en mesure d'exécuter plus d'actions différentes. De quelle taille l'algorithme doit-il utiliser ? Dans l'espace comme dans le temps, la combinaison est exploitée.
Cet algorithme exige que toutes les situations soient définies et, comme nous l'avons vu, l'espace requis est énorme. Malheureusement ce n'est pas le seul problème.
Problématique de la généralisation des états d'entrée
En analysant le comportement de l'être vivant, même s'il ne sait pas comment agir dans de nouvelles situations, nous pouvons observer qu'il utilise une expérience similaire. Cela nous indique qu'Izaki est capable de généraliser. Normalement, il y a une certaine relation entre les situations et il y a des situations très similaires. Si nous savons comment agir face à une situation parce que nous avons une expérience dans cette situation, si nous nous trouvons dans une situation différente et nouvelle, nous agirons de la même manière.
Comment le robot peut-il savoir qu'une situation est similaire à une autre ? Si je pouvais le connaître, pour savoir comment agir dans les nouvelles situations, j'utiliserais l'expérience de situations similaires pour créer des actions similaires.
Une façon de résoudre ce problème est d'utiliser la distance Hamming. Les informations sur l'état du robot passe par des séries de bits. Vous pouvez calculer la distance Hamming entre ces séries de bits, comme le nombre de bits différents qui ont deux flux de bits.

Super ! Vous pouvez surmonter le problème de la généralisation. Cependant, faut-il garder toutes les situations? Le problème de l'explosion combinationnelle est toujours là !
Des groupes statistiques ont également été utilisés pour le surmonter. Cependant, il reste encore beaucoup à faire.
Allons-nous sur la bonne voie?
Que pensez-vous ? Il semble y avoir des choses ? Bien que nous ne l'ayons pas encore mentionné, il y a un problème dans tout cela.
Dans tous les algorithmes décrits, nous avons supposé que le robot se trouve dans un état donné et qu'une fois une action effectuée, sans tenir compte d'autre chose, nous savons dans quelle situation il va trouver au moment suivant, à savoir que la transition entre les états est le Markoviano. Au contraire, nous n'avons jamais tenu compte de la situation dans laquelle nous nous trouvons avant d'être dans la situation actuelle et cela peut être important.
Supposons que le robot est rapide et il va de l'avant à pleine vitesse. À un moment donné, en raison d'un obstacle à l'avant, la décision sera prise de tourner à droite. Dans quelle situation se trouve après le virage? Selon notre algorithme, nous disons que le robot décrit l'angle droit, mais nous savons que ce n'est pas le cas. Les robots utilisés jusqu'à présent sont assez lents et le problème n'a pas été très évident. Mais si nous continuons ainsi, nous réaliserons que nous allons mal, parce que ce que le robot fait et ce qu'il croit qu'il le fait peut être très différent.
Nombreux sont les problèmes. Bien sûr. Mais jusqu'à présent, les essais ont été très positifs et nous avons vu que les robots peuvent devenir de bons étudiants. Il suffit d'un peu plus de travail.
Zu idazle
Zientzia aldizkaria

