

Genes, neuronas y ordenadores
Ikertzailea eta irakaslea
Euskal Herriko Unibertsitateko Informatika Fakultatea
La naturaleza como fuente de inspiración
Concepto de inteligencia artificial XX. Apareció entre nosotros hacia mediados del siglo XX. En sus inicios se empieza a trabajar con la inteligencia simbólica y los problemas de búsqueda. Un buen ejemplo fueron los jugadores artificiales de ajedrez. El prestigioso ordenador de IBM, Deep Blue, fue el que más éxito obtuvo al imponerse en 1997 al prestigioso jugador de ajedrez Gary Kasparov.
Estas máquinas, sin embargo, no parecían la inteligencia del hombre. Eran capaces de hacer muy bien una cosa concreta, pero no otra. No estudiaban, no eran capaces de generalizar su conocimiento y, si cambiaban ligeramente las reglas del juego, no podían reaccionar. Por ello, los investigadores trabajaron nuevos caminos y trabajaron en un nuevo campo de la inteligencia artificial: el aprendizaje automático.
En este artículo no analizaremos en su totalidad el aprendizaje automático. Nos adentraremos en un área concreta pero atractiva: algoritmos inspirados en la naturaleza y aprendizaje. Nos acercaremos a un proceso muy parecido al modo de aprender humano, combinando redes neuronales y algoritmos genéticos.
Redes neuronales
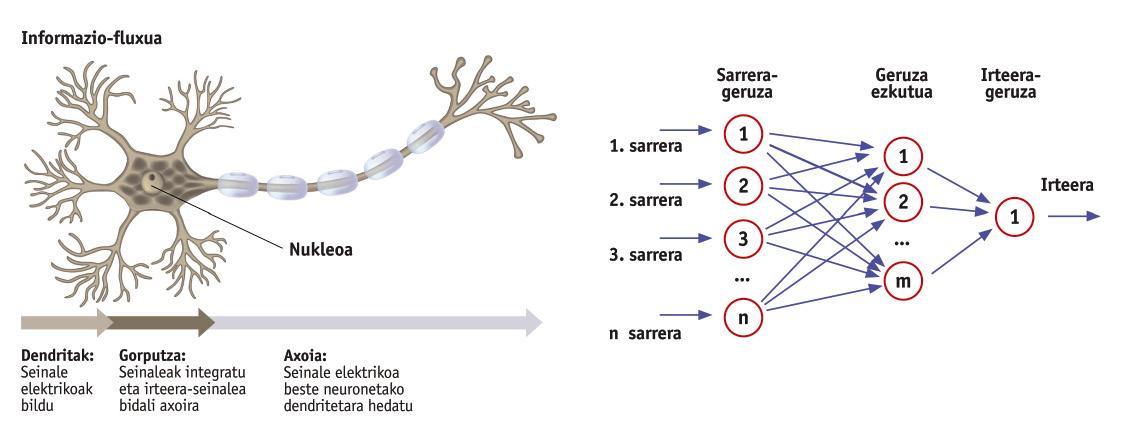
Nuestro cerebro está formado por neuronas, una pila de neuronas interconectadas. Pero si sólo analizamos una de estas neuronas nos sorprenderá su sencillez. Desde el punto de vista de la información, las neuronas reciben una serie de datos de entrada en forma de señal eléctrica y expulsan otra señal (Figura 1). Por tanto, la capacidad de procesamiento de nuestro cerebro se basa en la interacción de estas neuronas simples.
En la mente de esta idea, no parece muy difícil construir redes neuronales artificiales. Y no es difícil. Las primeras redes neuronales artificiales se desarrollaron entre los años 40 y 60 del siglo pasado. Sin embargo, su potencial no quedó patente hasta finales de los 80. Actualmente, las redes neuronales se pueden encontrar en once aplicaciones.
Las redes neuronales son un conjunto de neuronas que convierten algunas entradas de datos en salidas de datos. Como se puede observar en la figura 2, las redes neuronales se organizan en capas: capa de entrada, capa oculta (se pueden ocultar tantas capas como se desee) y capa de salida. Cada capa está formada por neuronas (rollos de la figura) y todas las neuronas de una capa están conectadas a las neuronas de la siguiente capa. Así es la estructura de una red neuronal convencional. Ten en cuenta que pueden existir redes de todo tipo para cumplir diferentes objetivos. Por ejemplo, algunas redes conectan las neuronas de la capa de salida con las capas ocultas para que la red tenga memoria. Pero, de momento, vamos a dejar de lado estructuras complejas.
Las entradas de cada neurona son números. Cuando estos números llegan a una neurona, se multiplican por otros números llamados pesos y se suman a continuación todos los resultados. Esta suma será la salida de la neurona. Como se ve, lo que hace cada neurona es muy sencillo. Pero toda la red, conectando todas las neuronas, es capaz de implementar cualquier función matemática. Este es el poder de la red. Lo que acabamos de decir puede demostrarse matemáticamente, pero eso está fuera de los objetivos de este artículo.
Por tanto, en el comportamiento de una red neuronal cobran especial importancia su estructura (número de capas y naturaleza de las conexiones) y el peso de cada neurona. Para realizar operaciones sencillas basta con una pequeña red en la que se fijan fácilmente todos los pesos y se determina la estructura adecuada. Sin embargo, las aplicaciones complejas requieren de grandes redes en las que es prácticamente imposible determinar manualmente todos los pesos de cada neurona. Por ello, es imprescindible que la propia red neuronal establezca los valores de estos pesos mediante un proceso automático. Este proceso se denomina aprendizaje automático y puede llevarse a cabo de diversas formas. Nosotros aquí veremos el aprendizaje por refuerzo. Para ello, en primer lugar, debemos analizar los algoritmos genéticos.
Algoritmos genéticos
La teoría de la evolución de Darwin nos enseñó cómo se produce la evolución de los seres vivos. Los que mejor se adaptan al medio ambiente son los que tienen más posibilidades de fecundarse y la fecundación combina las características de los padres y abre el camino a la nueva generación. Mediante la combinación de las características de los individuos que mejor se adaptan, de generación en generación, nacen mejores individuos. Los algoritmos genéticos utilizan estas ideas para optimizar problemas complejos.
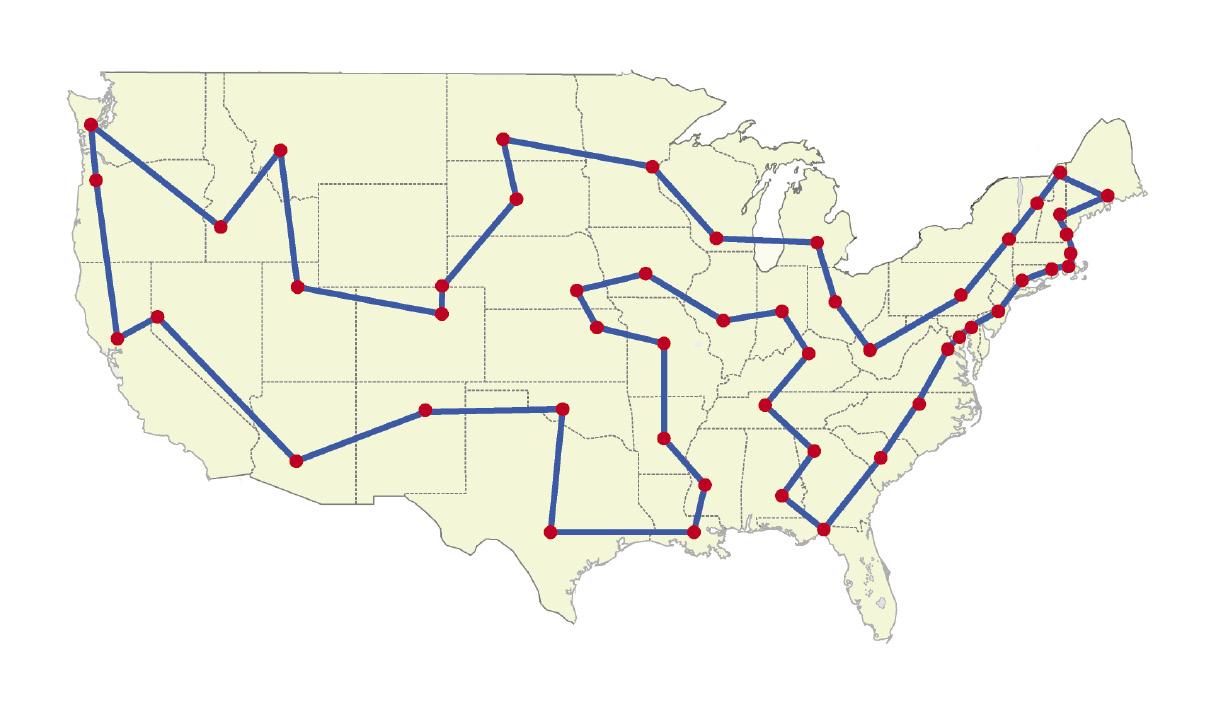
Analicemos este problema. Un viajero quiere visitar n ciudades, pero no de cualquier manera. Para ahorrar dinero, quiere hacer el camino más corto que pasa por estas n ciudades (figura 3). Teniendo en cuenta que sabemos las distancias entre todas las ciudades, ¿cómo podemos planificar el viaje? Parece sencillo: calculemos todos los órdenes de visita de las ciudades, sumemos las distancias y tomemos el más pequeño. Esta solución es correcta, pero cuando n es un gran número de ciudades, un ordenador tarda muchísimo en encontrar la solución. Por tanto, no es una solución práctica.
Los algoritmos genéticos pueden trabajar bien con el problema del viajero. ¿Cómo? Primero se crea la generación inicial y se crean unas combinaciones aleatorias de n ciudades. Estas combinaciones aleatorias se denominan individuos. Se calcula la distancia recorrida por cada individuo, quedando el algoritmo con unos pocos que proporcionan las distancias más pequeñas para cruzarlo. En el caso de las ciudades, por ejemplo, podemos combinar las primeras n/2 ciudades de un individuo con las n/2 de la segunda y crear un nuevo individuo de n ciudades. Los individuos resultantes de los cruces forman una segunda generación.
Otro factor importante es la mutación. Al igual que en la naturaleza, los nuevos individuos pueden nacer con mutaciones. En nuestro caso, el intercambio entre dos ciudades en posiciones aleatorias puede igualarse a una mutación. La mutación es rara pero tiene una función muy importante para encontrar individuos más adecuados.
A medida que el algoritmo genera nuevas generaciones, los individuos aportan mejores soluciones. Al final, aunque no siempre es posible encontrar una solución óptima, el mejor individuo queda muy cerca del óptimo. Así que en poco tiempo puede encontrar una solución muy buena. ¿No es sorprendente?
Aprendizaje por refuerzo
Ahora viene lo más bonito. Imaginemos que tenemos un robot que se puede mover en cualquier dirección. Nosotros queremos mostrar que cuando decimos “derecha” vamos a la derecha y cuando decimos “izquierda” nos movemos a la izquierda. Para ello ponemos un micrófono que detecta nuestra voz. La señal que genera el micrófono es la entrada de una red neuronal. La salida se refiere a las señales de los motores que sirven para mover el robot (figura 4).

El objetivo del robot es obtener los pesos de las neuronas que forman la red neuronal para que haga bien lo que hemos dicho. Entre todos los posibles valores de todos los pesos existen soluciones que responden al estímulo vocal con un movimiento adecuado. Para ello utilizaremos el aprendizaje por refuerzo. Daremos al robot una orden “derecha” o “izquierda” y dependiendo del movimiento que realice le pondremos una nota del 1 al 10. Si dice “derecha” y se mueve a la izquierda le pondremos 1. Pero si se mueve hacia delante haciéndolo un poco a la derecha, igual le ponemos un 5. Claro, cuando se mueve a la derecha, ¡tendrá un 10!
El proceso de aprendizaje funciona como: en primer lugar, el algoritmo genético selecciona soluciones aleatorias, es decir, pesos específicos de la red neuronal. Ejecuta estas soluciones y detecta las mejores en función del premio recibido. Cruza los mejores pisos, a veces aplica la mutación y vuelve a probar con la nueva generación. Con los nuevos premios recibidos se creará una nueva generación que permitirá encontrar una solución con los premios más potentes para todas las órdenes de voz.
Estos experimentos ya se han realizado y se ha comprobado que esta técnica funciona. Pero eso no es magia, sino matemáticas. ?Realmente se está produciendo un proceso iterativo de búsqueda de los parámetros más adecuados de una función no lineal. En nuestra opinión, buscamos los pesos de la red neuronal en un proceso de optimización en el que el objetivo es maximizar el premio obtenido.
Para terminar
El aprendizaje por refuerzo se basa en procesos de aprendizaje de seres humanos y animales. Además, aquí hemos mostrado cómo desarrollar este proceso utilizando redes neuronales y algoritmos genéticos. Ambos tienen su base en la naturaleza. Es fascinante ver que podemos capacitar a las máquinas para aprender. Quizá sea más fascinante saber que esa capacidad de aprender la hemos conseguido imitando procesos que tienen lugar en la propia naturaleza, lo que demuestra la profundidad del conocimiento de la naturaleza que hemos adquirido a través de la ciencia durante muchos años. Hemos podido combinar psicología, biología, neurociencias, matemáticas e informática para que las máquinas aprendan.
Actualmente tenemos varios ejemplos de máquinas capaces de aprender. Cuando compramos en red y valoramos los productos, automáticamente recibimos nuevos consejos porque los sistemas que están detrás aprenden de nosotros. Los buscadores web también utilizan el aprendizaje para ofrecer búsquedas personalizadas. A través de la cámara podemos conocer las caras, conducir los coches de forma autónoma y poner muchos ejemplos del éxito del aprendizaje y la inteligencia artificial.
El camino sigue siendo largo. Sólo hemos empezado. Aunque la inteligencia artificial y el aprendizaje automático han evolucionado mucho, todavía estamos lejos de lo que un ser humano puede hacer. Pero avanzamos.
Bibliografía
"Esta entrada #CulturaCientífica 3. Participa en el festival"

Zu idazle
Zientzia aldizkaria

