

Ce qui nous fait être, pour écrire ce que nous faisons
L’être humain a toujours eu une passion particulière pour transmettre des connaissances aux générations futures, ce qui nous a conduits à découvrir et/ou à développer certaines façons de stocker des informations. Jusqu'à présent, on sait que ses premières preuves sont parmi les falaises d'il y a 40 000 ans. Plus tard, avec la création des langues, nous élaborons les premiers textes écrits. De même, la découverte du rôle et le développement de l'imprimerie ont fait apparaître pendant des années les livres comme source d'information.
Changement de profil, cependant, XX. a eu lieu au milieu du XXe siècle, coïncidant avec l'apparition de l'électronique numérique. En effet, les développements du transistor et de la micropuce ont permis, entre autres, la naissance du stockage numérique des données.
Qu'est-ce que le stockage numérique de données ?
Le stockage numérique de données consiste à stocker des informations numériques par des moyens électroniques. De même, l'information numérique est celle qui est exprimée par le système binaire (en utilisant les 0 et 1). Les valeurs 0 et 1 représentent des situations. Par exemple, 0 correspond à l’état “éteint” et 1 à l’état “allumé”, ou 0 à une tension électrique spécifique et 1 à une autre tension. En tout état de cause, elles représentent deux situations. Dans le système binaire, chacune de ces unités d'état reçoit le nom de bit et un octet est construit avec 8 bits consécutifs. À partir de là, et à travers des milliers d'octets, on construit du texte, des images, des vidéos, des audios et d'autres informations numériques.
Le stockage numérique de données permet de stocker de grandes quantités d'informations dans un espace physique réduit, ainsi que de lire et de modifier plusieurs fois
Spoiler: Le cloud n'existe pas
Non. Le « cloud » est composé de centres de données gérés par des entreprises telles que Google, Amazon Web Services (AWS), Microsoft, etc. Le cloud est donc une métaphore utilisée pour résumer la complexité de ces infrastructures.
Fixons un moment sur la quantité de données générée par jour en 2022: 8,5 millions de recherches sur Google, 720 000 heures sur YouTube, 93 millions de photos sur Instagram, 867 millions sur Txio En utilisant et 333 milliards de courriels, entre autres. Ainsi, nous avons généré et consommé près de 94 cettabytes l'année dernière (1 zettabyte = 1 E + 21 octets). C'est-à-dire que si chaque bit était une pièce d'un euro et que nous accumulons des pièces jusqu'à 1 cettabyte, nous formerions une distance de 1.970 ans de lumière, suffisante pour que Alpha Centauri soleil puisse atteindre 225 rayons plus proches du système izar.
À cet égard, ces centres de données sont parvenus à constituer de gigantesques entrepôts de serveurs qui s'organisent sur une superficie d'environ 10 000 m², sur de nombreuses colonnes et lignes. Ces serveurs ont bien sûr besoin d'un système de froid pour éviter les surchauffes. Si cela n’était pas le cas, et pour que le « cloud » soit opérationnel à tout moment et que l’influence des pannes du réseau électrique ne soit pas perceptible, il y a des générateurs qui alimentent le diesel dans ces zones. Ainsi, une telle zone consomme en un an une énergie équivalente à celle utilisée par 50 000 logements. Face à la tendance croissante du stockage numérique des données, l’énergie nécessaire pour maintenir cette production numérique pourrait dépasser la consommation énergétique actuelle de toute la planète à la fin de ce siècle.
Alternatives?
Une chose est claire, ce n'est pas la voie. Nous devons changer de direction. Trouver une alternative ou plusieurs. Ce n'est pas facile, non, mais demandez à quelqu'un qui sait plus de la survie que nous, à quelqu'un qui a plus d'expérience que nous. Demandez à la nature.
Comment la nature a-t-elle réussi à rappeler de génération en génération l’être humain ou l’arbre ? Comment notre environnement a-t-il changé et la nature a-t-elle changé pour que nous ayons des caractéristiques différentielles à chaque époque et à chaque endroit précis? Fondamentalement, avec une seule molécule: ADN (acide désoxyribonucléique)
Quand nous parlons de l'ADN, nous sommes à l'esprit la vie même, mais pas l'information ni les ordinateurs. Eh bien, le même ADN est un code à 4 lettres pour enregistrer et transmettre des informations dans un organisme. Cette molécule est une hélice à double chaîne composée de quatre nucléotides (adénine (A), thimine (T), guanine (G) et cytosine (C).
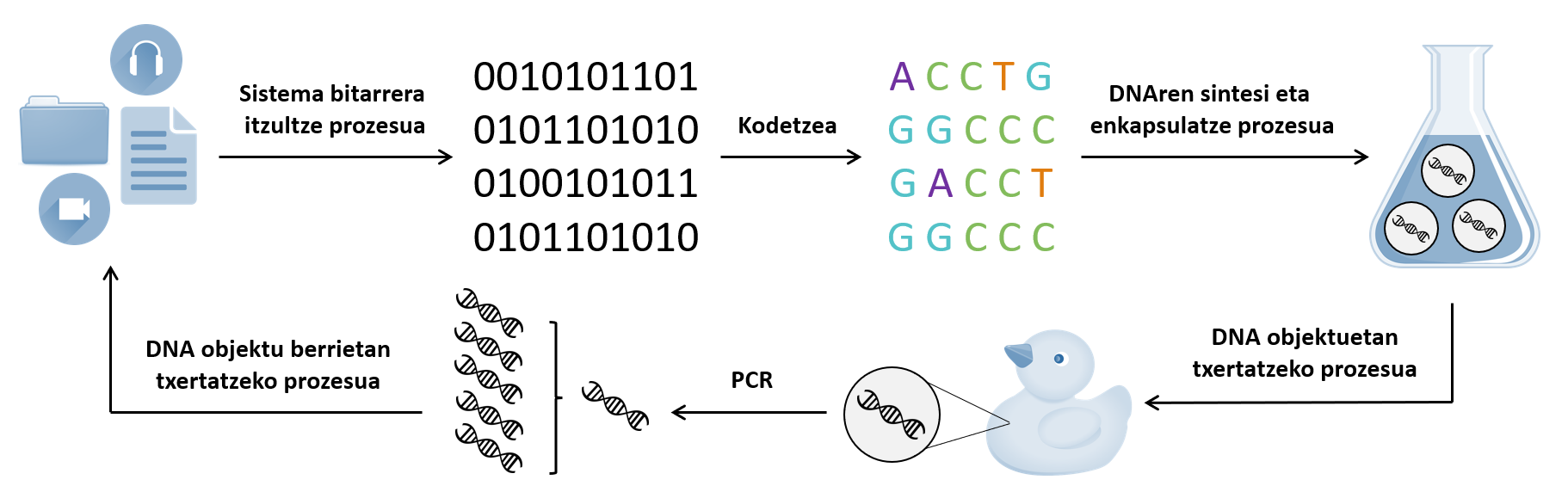
Pour convertir les informations numériques en ADN, la première chose à faire est de coder les données (voir 1. Image). Il existe plusieurs façons de le faire, comme il existe plusieurs langages pour écrire un algorithme. Une option est d'utiliser l'adénine pour exprimer 00 du système binaire, 01 guanine, 10 cytosine et 11 thymine.

L’ADN synthétisé est ensuite stocké. Bien que plusieurs systèmes de stockage aient été développés, deux stratégies peuvent être envisagées. Une alternative serait de geler et de maintenir l'ADN. Cette molécule peut rester stable pendant des millions d'années dans ces conditions. Une autre possibilité est d'encapsuler l'ADN et de l'intégrer dans un autre matériau. Cette stratégie repose sur l’idée de « DNA-of-Things » ou « ADN des choses » et consiste essentiellement à codifier l’information à l’ADN et à la stocker dans les objets quotidiens. Un exemple est le travail effectué en 2019 par des chercheurs suisses et israéliens.
Réalité ou science-fiction ?
Bien que l'utilisation de l'ADN pour stocker des données nous semble étrange, cette idée a de moins en moins de science-fiction. C'est une stratégie qui s'aligne très bien sur les défis que nous avons pour les humains pour ce siècle.
Le stockage d’informations ADN est plus efficace et plus durable sur le plan énergétique que les systèmes existants (voir 3). Image), parce que l'ADN bien encapsulé peut prendre des siècles à température. En outre, vous n'avez pas besoin d'effectuer des tâches d'écriture, et les fichiers ainsi enregistrés peuvent être facilement copiés et répliqués.
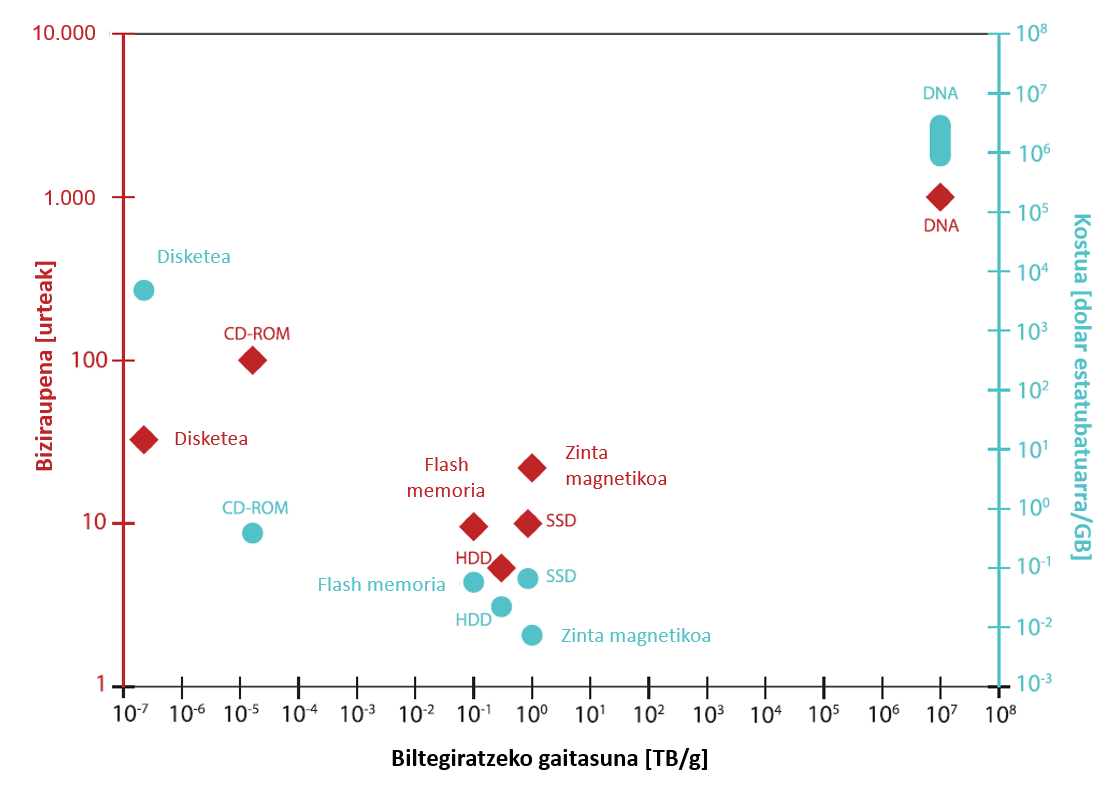
De plus, ce système de stockage est très dense, car le volume occupé par les informations stockées par l'ADN est très réduit. Dans un seul gramme d'ADN, 215 pétaoctets peuvent être mis (1 petabyte = 1 E + 15 octets)
Il convient toutefois de noter que le stockage de données ADN reste coûteux et qu’il faudra au moins quelques décennies pour que les systèmes de synthèse et d’extraction de l’ADN diminuent les prix et commencent à être largement utilisés.
En outre, la récupération à la bonne vitesse des fichiers stockés reste un défi. En fait, chaque capsule utilisée pour stocker l'ADN porte un code ADN correspondant à son contenu comme étiquette. Par conséquent, pour sélectionner et extraire un fichier spécifique, tout en conservant le reste, il faut ajouter l'initiateur correspondant à cette étiquette d'ADN. Avec la technologie actuelle, ce processus est très long. Le stockage de données ADN peut, en principe, être utilisé exclusivement pour la réalisation du “stockage froid”. Autrement dit, utiliser uniquement pour stocker des données inactives ou très peu utilisées
Un regard sur l'avenir
Et maintenant imaginez. Imaginez un tel avenir. Imaginez que vous mangiez de nouvelles lunettes et que toutes les informations sur votre graduation, votre matériau et votre processus de fabrication y soient. Imaginez qu'ils allaient faire l'achat et que le prix de chaque repas soit le produit, sans le code. L'ADN est biodégradable et donc à l'intérieur. Utiliser ce que nous avons imaginé pour écrire ce que nous faisons.
Mais imaginez aussi ce que cela pourrait supposer pour la sécurité et la protection des données. Quelles seraient les conséquences d'une mauvaise utilisation de cette technologie? Que pouvons-nous faire? Quelle est la responsabilité des scientifiques et des ingénieurs dans le développement de cette technologie? Comme tous les progrès technologiques et scientifiques qui ont conduit à un changement de mission, celui-ci non seulement produira des dilemmes éthiques, mais remettra en question d'autres sujets.
Que quand il vient vient et vient comme il vient, au moins ne nous surprend pas.
BIBLIOGRAPHIE
[1] A. Siddiqa, A. Karim and A. Gani, “Big data storage technologies: a survey,” Frontiers of Information Technology & Electronic Engineering, vol. 18, p. 18. 1040-1070, 2017.
[2] I. Voie, O. Ajayi, B. Akanle and R. Ahuja, “An Overview of Data Storage in Cloud Computing,” International Conference on Next Generation Computing and Information Systems (ICNGCIS), pp. 29-34, 2017.
[3] A. A. Khan and M. Zakarya, “Energy, performance and cost efficient cloud datacentres: A survey,” Computer Science Review, vol. 40, 2021.
[4] L. Ceze, J. Nivala and K. Strauss, “Molecular digital data storage using ADN,” Nature Reviews Genetics, vol. 20, pp. 456-466, 2019.
[5] Y. Erlich and D. Zielinski, “ADN Fountain enables à robust and efficient storage architecture,” Science, vol. 355, p. 355. 950-954, 2017
[6] J. Koch, S. Gantenbein, K. Masania, W. J. Stark, Y. Erlich and R. N. Grass, “A DNA-of-things storage architecture to create materials with embedded memory,” Nature Biotechnology, vol. 38, p. 38. 39-43, 2019.
[7] L. C. Meiser, B. H. Nguyen, Y.-J. Chen, J. Nivala, K. Strauss, L. Ceze and R. N. Grass, “Synthetic DNA applications in information technology,” Nature Communications, vol. 13, ez. 352, 2022.
[8] R. Heckel, “An archive written in DNA,” Nature Biotechnology, vol. 36, p. 36. 236-237, 2018.
[9] P. M. Church, Y. Gao and S. Kosuri “Next-Generation Digital Information Storage in DNA,” Science, vol. 337, p. 337. 1628, 2018.
[10] C. Matange, J. M. Tuck and A. J. Keung, “DNA stability: a central design consideration for DNA data storage systems,” Nature Communications, vol. 12, ez. 1358, 2021.
Zu idazle
Zientzia aldizkaria

