

Lo que nos hace ser, para escribir lo que hacemos
El ser humano siempre ha tenido una especial pasión por transmitir conocimiento a las generaciones futuras, lo que nos ha llevado a descubrir y/o desarrollar algunas formas de guardar información. Hasta el momento se sabe que sus primeras evidencias se encuentran entre los acantilados de hace 40.000 años. Más adelante, con la creación de las lenguas, elaboramos los primeros textos escritos. Asimismo, el descubrimiento del papel y el desarrollo de la imprenta, hicieron que durante años los libros aparecieran como fuente de información.
Cambio de perfil, sin embargo, XX. se produjo a mediados del siglo XX, coincidiendo con la aparición de la electrónica digital. De hecho, los desarrollos del transistor y del microchip permitieron, entre otras cosas, el nacimiento del almacenamiento digital de datos.
¿Qué es el almacenamiento digital de datos?
El almacenamiento digital de datos consiste en almacenar información digital por medios electrónicos. Asimismo, la información digital es aquella que se expresa a través del sistema binario (utilizando los 0 y 1). Los valores 0 y 1 representan situaciones. Por ejemplo, el 0 corresponde al estado “apagado” y el 1 al estado “encendido”, o el 0 a una tensión eléctrica concreta y el 1 a otra tensión. En cualquier caso, representan dos situaciones. En el sistema binario, cada una de estas unidades de estado recibe el nombre de bit y se construye un byte con 8 bits consecutivos. A partir de ella, y a través de miles de bytes, se construye texto, imágenes, vídeos, audios y otra información digital.
El almacenamiento digital de datos permite guardar grandes cantidades de información en un espacio físico reducido, así como leer y editar varias veces
Spoiler: La nube no existe
Pues no. La “nube” está formada por centros de datos gestionados por empresas como Google, Amazon Web Services (AWS), Microsoft, etc. Por lo tanto, la nube es una metáfora que se utiliza para resumir la complejidad de estas infraestructuras
Fijémonos un momento en la cantidad de datos generada por día en el año 2022: 8,5 millones de búsquedas en Google, 720.000 horas en YouTube, 93 millones de fotos en Instagram, 867 millones en Txio Usando y 333 mil millones de correos electrónicos, entre otros. Así, hemos generado y consumido cerca de 94 cettabytes en el último año (1 zettabyte = 1 E + 21 bytes). Es decir, si cada bit fuese una moneda de un euro y acumuláramos monedas hasta formar 1 cettabyte, estaríamos conformando una distancia de 1.970 años de luz, suficiente para que Alpha Centauri sol pudiera llegar hasta 225 rayos más cercanos al sistema izar.
En este sentido, estos centros de datos han llegado a constituir unos gigantescos almacenes de servidores que se organizan en unas superficies de unos 10.000 m², en numerosas columnas y líneas. Estos servidores necesitan, por supuesto, un sistema de frío para evitar sobrecalentamientos. Por si esto fuera poco, y para que la “nube” esté operativa en todo momento y no se aprecie la influencia de fallos en la red eléctrica, en estas zonas hay generadores que se alimentan de diesel. Así, una zona de este tipo consume en un año una energía equivalente a la utilizada por 50.000 viviendas. Ante la tendencia creciente de almacenamiento digital de datos, la energía necesaria para mantener esta producción digital llegaría a superar el consumo energético actual de todo el planeta a finales de este siglo.
¿Alternativas?
Una cosa está clara, esto no es el camino. Debemos cambiar de dirección. Encontrar una alternativa o varias. No es fácil, no, pero preguntemos a alguien que sabe más de la supervivencia que nosotros, a alguien que tiene más experiencia que nosotros. Preguntemos a la naturaleza.
¿Cómo ha conseguido la naturaleza recordar de generación en generación al ser humano o al árbol? ¿Cómo ha cambiado y tiene la naturaleza nuestro entorno para que en cada época y lugar concreto tengamos unas características diferenciales? Básicamente, con una sola molécula: ADN (ácido desoxirribonucleico)
Cuando hablamos de ADN nos viene a la mente la propia vida, pero no la información ni los ordenadores. Pues bien, el mismo ADN es un código de 4 letras para guardar y transmitir información en un organismo. Esta molécula es una hélice de doble cadena formada por cuatro nucleótidos (adenina (A), timina (T), guanina (G) y citosina (C).
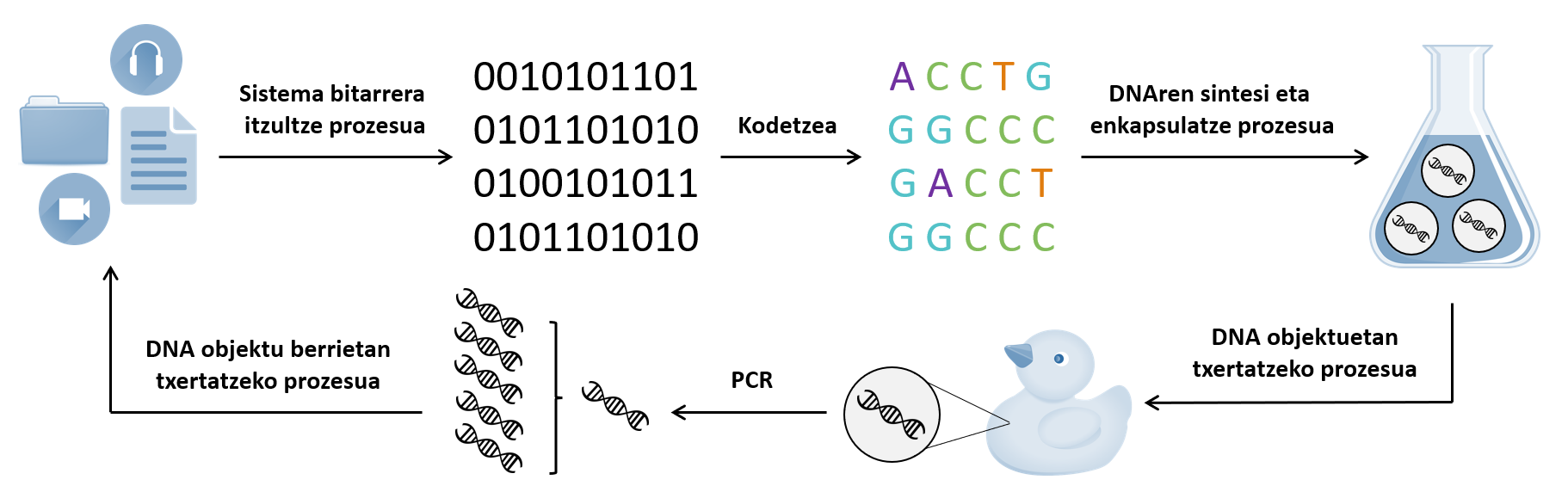
Para convertir la información digital en ADN, lo primero que hay que hacer es codificar los datos (ver 1. Imagen). Existen varias formas de hacerlo, de forma similar a como existen varios lenguajes para escribir un algoritmo. Una opción es utilizar la adenina para expresar 00 del sistema binario, 01 guanina, 10 citosina y 11 timina.

A continuación se almacenará el ADN sintetizado. Aunque se han desarrollado varios sistemas de almacenamiento, se pueden considerar dos estrategias. Una alternativa sería congelar y mantener el ADN. Esta molécula puede mantenerse estable durante millones de años en estas condiciones. Otra posibilidad es encapsular el ADN e integrarlo en otro material. Esta estrategia se basa en la idea de “DNA-of-Things” o “ADN de las cosas” y consiste básicamente en codificar la información al ADN y almacenarla en los objetos cotidianos. Un ejemplo es el trabajo realizado en 2019 por investigadores de Suiza e Israel.
¿Realidad o ciencia ficción?
Aunque el uso del ADN para almacenar datos nos resulta extraño, esta idea cada vez tiene menos de ciencia ficción. Es una estrategia que se alinea muy bien con los retos que tenemos los humanos para este siglo.
El almacenamiento de información por ADN es energéticamente más eficiente y sostenible que los sistemas actuales (ver 3). Imagen), porque el ADN bien encapsulado puede tardar siglos en temperatura. Además, no necesita realizar tareas de escritura, y los ficheros así guardados pueden copiarse y replicarse fácilmente.
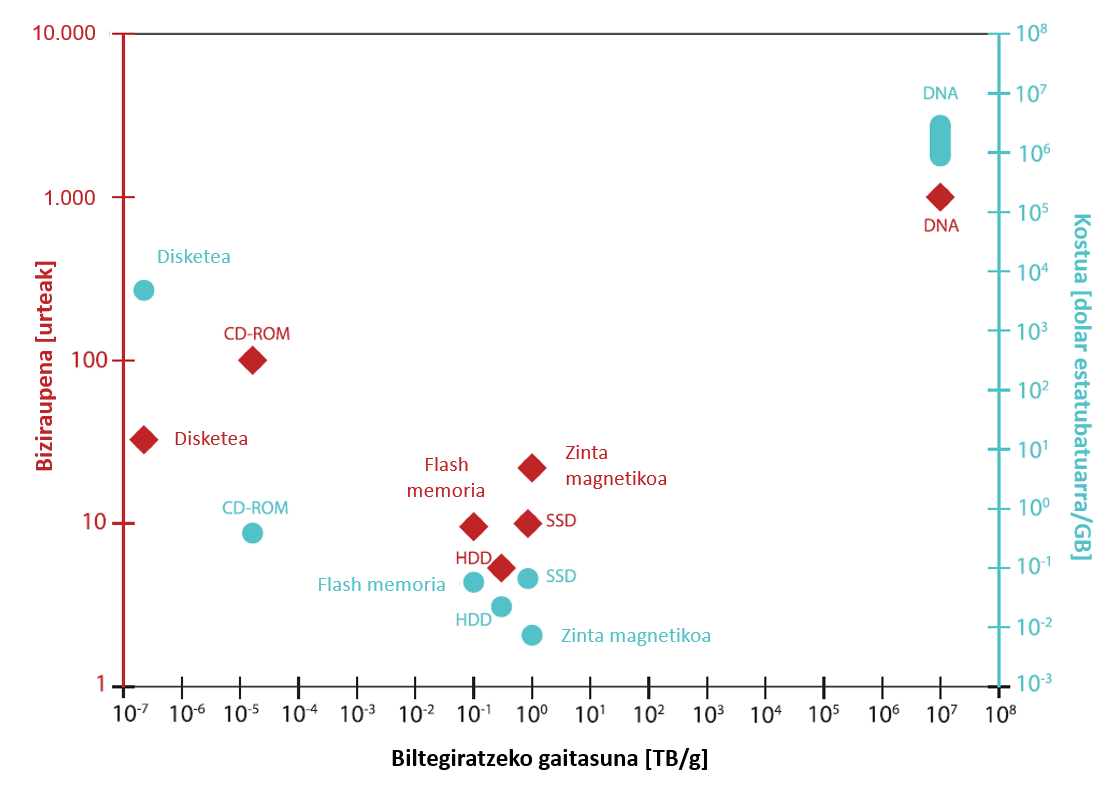
Por si esto fuera poco, este sistema de almacenamiento es muy denso, ya que el volumen ocupado por la información almacenada mediante ADN es muy reducido. En un solo gramo de ADN se pueden meter 215 petabytes (1 petabyte = 1 E + 15 bytes)
No obstante, hay que señalar que el almacenamiento de datos por ADN sigue siendo caro, y que deberá transcurrir al menos un par de décadas desde que los sistemas de síntesis y extracción del ADN bajen los precios y comiencen a utilizarse de forma generalizada
Además, la recuperación a la velocidad adecuada de los ficheros almacenados sigue siendo un reto. De hecho, cada cápsula utilizada para almacenar el ADN lleva un código de ADN que corresponde a su contenido como etiqueta. Por tanto, para seleccionar y extraer un fichero concreto, manteniendo el resto, hay que añadir el iniciador correspondiente a esta etiqueta de ADN. Con la tecnología actual, este proceso es muy largo. El almacenamiento de datos por ADN puede, en principio, utilizarse exclusivamente para la realización del denominado “almacenamiento frío”. Es decir, utilizar únicamente para almacenar datos inactivos o muy poco utilizados
Una mirada al futuro
Y ahora imagínate. Imaginad un futuro como éste. Imaginad que compréis unas nuevas gafas y que toda la información sobre su graduación, material y proceso de fabricación esté en las mismas. Imaginad que fuesen a hacer la compra y que el precio de cada comida fuera el producto, sin el código. El ADN es biodegradable y, por tanto, hacia dentro. Utilizar lo que nos hemos imaginado para escribir lo que hacemos.
Pero imaginad también qué podría suponer esto para la seguridad y la protección de datos. ¿Qué consecuencias tendría el uso incorrecto de esta tecnología? ¿Qué podemos llegar a hacer? ¿Cuál es la responsabilidad de los científicos e ingenieros en el desarrollo de esta tecnología? Como todos los avances tecnológicos y científicos que han llevado a cabo un cambio de misión, éste no sólo va a generar dilemas éticos sino que va a cuestionar otros temas.
Que cuando viene viene viene y viene como viene, por lo menos que no nos sorprenda.
BIBLIOGRAFÍA
[1] A. Siddiqa, A. Karim and A. Gani, “Big data storage technologies: a survey,” Frontiers of Information Technology & Electronic Engineering, vol. 18, pp. 1040-1070, 2017.
[2] I. Vía, O. Ajayi, B. Akanle and R. Ahuja, “An Overview of Data Storage in Cloud Computing,” International Conference on Next Generation Computing and Information Systems (ICNGCIS), pp. 29-34, 2017.
[3] A. A. Khan and M. Zakarya, “Energy, performance and cost efficient cloud datacentres: A survey,” Computer Science Review, vol. 40, 2021.
[4] L. Ceze, J. Nivala and K. Strauss, “Molecular digital data storage using DNA,” Nature Reviews Genetics, vol. 20, pp. 456-466, 2019.
[5] Y. Erlich and D. Zielinski, “DNA Fountain enables a robust and efficient storage architecture,” Science, vol. 355, pp. 950-954, 2017.
[6] J. Koch, S. Gantenbein, K. Masania, W. J. Stark, Y. Erlich and R. N. Grass, “A DNA-of-things storage architecture to create materials with embedded memory,” Nature Biotechnology, vol. 38, pp. 39-43, 2019.
[7] L. C. Meiser, B. H. Nguyen, Y.-J. Chen, J. Nivala, K. Strauss, L. Ceze and R. N. Grass, “Synthetic DNA applications in information technology,” Nature Communications, vol. 13, ez. 352, 2022.
[8] R. Heckel, “An archive written in DNA,” Nature Biotechnology, vol. 36, pp. 236-237, 2018.
[9] P. M. Church, Y. Gao and S. Kosuri “Next-Generation Digital Information Storage in DNA,” Science, vol. 337, p. 1628, 2018.
[10] C. Matange, J. M. Tuck and A. J. Keung, “DNA stability: a central design consideration for DNA data storage systems,” Nature Communications, vol. 12, ez. 1358, 2021.
Zu idazle
Zientzia aldizkaria

