

Mapas de conocimiento de la biodiversidad

Junto a la digitalización de muestras de historia natural acumuladas a lo largo de los siglos, la revolución tecnológica ha traído consigo oportunidades de big data en el campo de la biodiversidad. Para conocer la distribución de las especies se dispone en una sucesión de clics de la información más abundante y detallada de la historia. Sin embargo, la propia cantidad de información puede comprometer la credibilidad de los mapas de biodiversidad.
De la historia natural ? i-natural
Edward O. Wilson propuso el término biofilia para reivindicar la vocación congénita del ser humano hacia los seres vivos. Una vez garantizada la alimentación y la protección, el hombre comenzó a investigar y clasificar a los seres vivos desde una perspectiva inútil [1]. Desde entonces llevamos siglos trabajando en completar y comprender el puzzle de la biodiversidad.
XVII. y XVIII. Los siglos 15 fueron testigos de múltiples exploraciones de la naturaleza. En aquellos tiempos también se iniciaron exposiciones de colecciones biológicas. Ejemplos de ello son el Museo de Historia Natural de París, fundado en 1635, o el Kunstgela, fundado hace unos 300 años por Petri I de Rusia, en el que se expusieron al público colecciones de animales de todo el mundo [2] (incluyendo formas animales poco habituales).
Además de los abundantes descubrimientos de nuevas especies, el XIX nos dejó trabajos pioneros en la comprensión de la distribución de las formas de vida (biogeografía) y del origen (evolución). siglos. Humboldt, Wallace y el propio Darwin se basaron en la observación de la biodiversidad para materializar sus ideas; tratando de responder a preguntas sobre la biodiversidad, convirtiendo la biodiversidad en un beso.
XX. En el siglo XX prosiguió la catalogación de especies y la documentación de su distribución. Para el año 2000, los museos y herbarios contaban con cerca de 3 billones de especimenes [3].
A pesar de que el legado de los siglos es impresionante, la revolución tecnológica de las últimas décadas ha dejado pequeña esta barrera. El desarrollo de repositorios de datos y herramientas digitales (apps, GPS, Smartphones) han permitido una recogida masiva de información, al tiempo que se ha conseguido la “democratización” de la catalogación de la biodiversidad. En la actualidad, la mayor parte de los datos de distribución de las especies son recogidos por voluntarios en una medida diferente a la anterior. Por ejemplo, en el Global Big Day han participado más de 28.000 personas de 170 países y se han registrado 1,6 millones de registros de 6.899 especies de aves (2/3 de las conocidas) [4].
Mapas de biodiversidad a un click
Junto al desarrollo de nuevas formas de recogida de datos, en los últimos años se han producido importantes cambios de paradigma en la propiedad de los datos. Se han abierto millones de datos que estaban recogidos en museos y herbarios, sin límites y de forma gratuita para el usuario. Todo ello ha facilitado el desarrollo de plataformas de intercambio de información [5]. Global Biodiversity Information Facility (GBIF) es la plataforma más conocida a nivel mundial que ha puesto registros unificados y estandarizados de especies de más de 1 reunión para su consulta online.
La utilidad de la información genera nuevas oportunidades en ámbitos como el económico (por ejemplo, a través del turismo de la vida salvaje), el educativo, el etnobotánico y, por supuesto, la conservación de la biodiversidad. De hecho, los mapas de biodiversidad son fundamentales para resolver múltiples cuestiones ecológicas y de conservación, entre ellas: ¿Cómo se distribuyen las especies? ¿Qué papel juegan en este patrón de reparto las condiciones ambientales actuales y pasadas y los factores geográficos y ecológicos? ¿Cuáles son los puntos más calientes de la biodiversidad? ¿Cómo ha cambiado la distribución de una determinada especie (por ejemplo, una especie invasora, amenazada)? ¿Cómo cambiará en el futuro? Por supuesto, todas estas respuestas pueden tener una importancia capital para hacer frente a las consecuencias de los cambios antropogénicos [6].
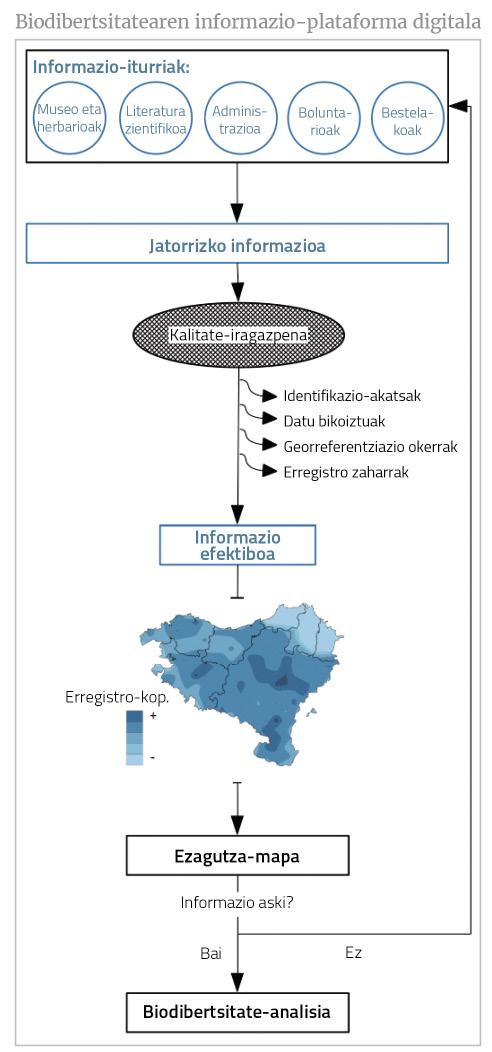
Si bien hasta el momento hemos realizado la apología de la información disponible, el mayor reto es garantizar la calidad de la propia información. Toda entrada de información, bien sea un dato recogido en el monte o proveniente de una antigua fuente de información (incluida la literatura gris), debe ser validada antes de dar el visto bueno a lo digitalizado. La mayoría de las plataformas de información suministradoras siguen protocolos estrictos de detección y limpieza de posibles errores (por ejemplo, taxonómicos, asociados a georreferenciación) y existen numerosas herramientas de apoyo para el postprocesamiento de la información (para lograr una homogeneización taxonómica, para la limpieza de datos duplicados y georreferenciales erróneos, etc.). Sin embargo, no suele ser un trabajo lento conseguir que la información tenga un nivel mínimo de calidad y, en ocasiones, estas operaciones de cribado pueden suponer la exclusión de mucha información. Por lo tanto, además de la cantidad, la calidad limitará el tamaño de la información efectiva (figura 1).
Achaques de Big Data, tendencias de la biodiversidad
Dado que la mayoría de los especímenes y los registros de localización de las especies se han recibido sin planificación, la distribución de la información no es homogénea entre los grupos taxonómicos, ni en el espacio ni en el tiempo [7]. Asimismo, la combinación de diversas fuentes de información puede suponer un aumento de la heterogeneidad, hasta el punto de comprometer la credibilidad de los mapas de biodiversidad.
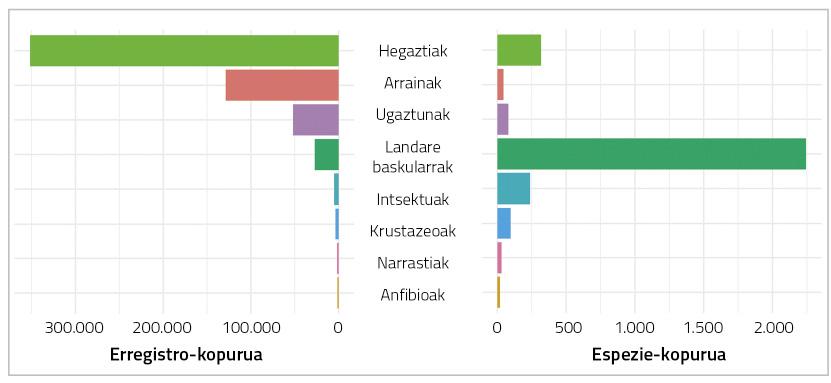
Tradicionalmente, algunos grupos taxonómicos han adquirido mayor atención que otros (figura 2). A pesar de que ambas experiencias pueden ser fascinantes, la gente tiende más a observar las aves que a hacer colecciones de caracoles. Asimismo, en la medida en que especies raras, emblemáticas, amenazadas, etc. son tesoros más apreciados para los amantes de la naturaleza, se documentan con mayor intensidad, tal y como se refleja en el número de registros de plataformas de biodiversidad.
Asimismo, algunas áreas geográficas están mejor muestradas que otras. Salvo excepciones, los puntos de información más calientes son los espacios naturales. Las especies preciadas suelen actuar como cebo, ya que las especies atraen a los amantes de la naturaleza a sus lugares de residencia [8]. En otros casos, las razones logísticas se centran en la cercanía al domicilio del receptor principal de datos, la existencia de una zona de acceso público, la accesibilidad o la existencia de una zona de monitorización a largo plazo [9].
Así, tanto la tendencia taxonómica como la espacial pueden ser variables en el tiempo. Esto permite conocer bien la distribución pasada de una especie, pero no la actual (también al revés). En el caso más grave la información puede quedar obsoleta. Por ello, es recomendable utilizar únicamente registros de un período de tiempo determinado que se ajusten de forma realista al objetivo de investigación, aunque pueda suponer una pérdida importante de información.

Las razones de las tendencias taxonómicas, espaciales y temporales pueden ser muy diversas, según los casos y según la escala. Por razones, es fundamental identificar estas tendencias y valorar su impacto para poder realizar análisis de biodiversidad creíbles. Y en este sentido, analizar el desconocimiento puede ser tan importante como analizar el propio conocimiento.
Credibilidad de los mapas de biodiversidad
El muestreo heterogéneo en biodiversidad por espacio se refleja en las bases de datos: algunas unidades espaciales tienen más registros que otras. En un mapa de biodiversidad mundial, el efecto de este esfuerzo de muestreo será menor debido a que los gradientes de biodiversidad son más marcados. Sin embargo, en una escala media o pequeña, la distorsión del esfuerzo de muestreo será mucho más grave: los puntos más calientes de la biodiversidad se corresponderán con los puntos más profundos, mientras que los fríos se corresponderán con los poco muestreados (Figura 3). Detrás de este resultado se encuentran las curvas de acumulación de especies, que adoptan la forma de las curvas de saturación de las enzimas: en las primeras muestras correspondientes a una unidad geográfica se recogerán muchas nuevas especies; en las siguientes, cada vez menos, hasta que no se encuentren más especies en la unidad (saturación).
Conociendo en qué punto se encuentra el proceso de acumulación de especies, se puede estimar el grado de conocimiento (o grado de desconocimiento) de la lista de especies. Así (u otros métodos no paramétricos, véase [10]) se puede medir si cada unidad geográfica está bien o mal muestrada y, de paso, determinar la credibilidad del mapa de biodiversidad [11]. A partir de estas mediciones se puede crear un mapa de conocimiento que nos ayude a juzgar si la información es útil para responder a la pregunta que nos ocupa. En algunos casos, los análisis de biodiversidad podrán limitarse a unidades “bien” muestradas [12], mientras que en otros casos será evidente la necesidad de más datos.
Para completar las lagunas de información se ha propuesto utilizar modelos de distribución de especies. Sin embargo, los modelos no son en absoluto perfectos y, en la mayoría de los casos, no parece la mejor alternativa incorporar más incertidumbre a un mapa con un alto grado de incertidumbre [8]. Entonces, ¿qué? Digitalizar nuevos datos (sólo el 1% de los datos de herbarios y museos están georreferenciados [13] o sólo queda ir a buscar datos al monte, una realidad bruta. Sin embargo, hay buenas noticias, los mapas de conocimiento pueden ser una herramienta eficaz para planificar y optimizar nuevos muestreos. De hecho, la promoción de muestreos en lugares poco conocidos permite maximizar las aportaciones de los nuevos registros para elaborar mapas de biodiversidad fiables [14].
En la era del Big Data tan importante como garantizar el acceso a la información es fomentar su uso crítico. La medición del conocimiento puede ser el punto de partida para enjuiciar la credibilidad de los mapas de biodiversidad, así como para diseñar muestreos para completarlos. Sin embargo, los usuarios no especializados (gestores, profesionales, investigadores de ciencias naturales, etc.) deberían realizar graves ejercicios de programación y modelización para producir este tipo de mapas. Es hora, por tanto, de romper ese cuello de botella y de extender el uso de mapas de conocimiento a diferentes ámbitos. Para ello, pueden resultar útiles herramientas que permitan visualizar la estimación del nivel de muestreo y su distribución espacial (p.ej. aplicaciones web interactivas).
Conocer cuántas piezas y dónde nos faltan para completar el puzzle de la biodiversidad puede ser un punto de partida sólido para avanzar en el conocimiento, así como un ejercicio sincero de rechazo a objetivos demasiado ambiciosos.
Bibliografía
Zu idazle
Zientzia aldizkaria

