

Mapas virtuais de idiomas
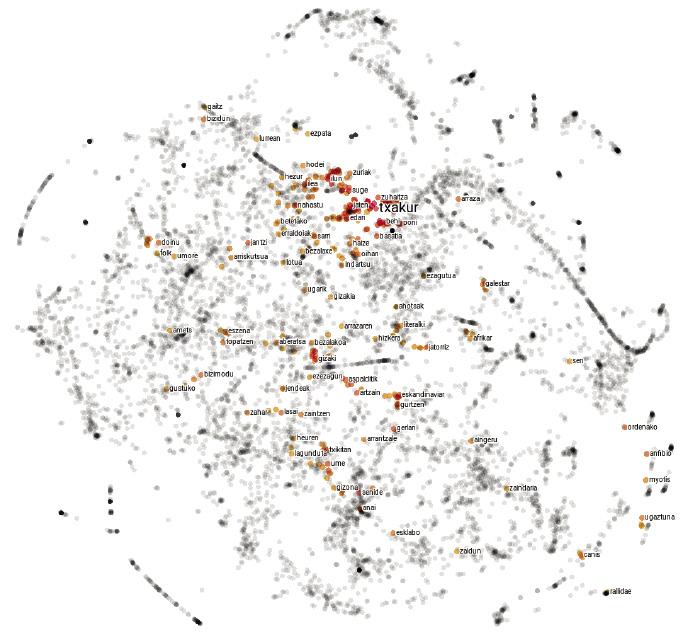
É curioso o idioma. Tanto na escritura como na pronuncia, as palabras porco e piollos son moi similares, mentres que as palabras porco e xabaril son completamente diferentes. Entre os animais, con todo, os porcos están moito máis preto dos xabarís que dos piollos. En definitiva, a relación entre as palabras dunha lingua e os seus significados é arbitraria, e as relacións entre os conceptos de porco, piollo e xabaril só viven na nosa mente.
Con todo, ao facer una procura en Google ou falar con Siri, o que temos tan interiorizado convértese nunha gran dificultade paira as máquinas. E do mesmo xeito que cando nos perdemos no monte ou na estrada, as máquinas utilizan mapas paira avanzar no labirinto de linguas. Estes mapas denomínanse Embedding e, a través deles, o procesamiento da linguaxe hase internalizado en terreos que parecían impensables. Imos facer esa viaxe paso a paso.
De mapas de cidades a mapas de palabras
Antes de penetrarnos no territorio da lingua, paremos momentaneamente paira fixarnos nos nosos mapas comúns. Basicamente, os mapas que coñecemos son representacións gráficas dun territorio, por exemplo, que asignan un punto a cada cidade en cada caso. Loxicamente, para que os mapas teñan sentido, estes puntos non están dispersos de calquera xeito, senón que a localización do mapa respecta as distancias que temos na realidade. Así, nun mapa, París apareceranos máis preto de Bruxelas que de Moscova, porque na realidade a capital francesa está máis preto da belga que da rusa.
Os mapas de idiomas non son moi diferentes. En lugar de explicar as cidades, cada punto representa una palabra e as distancias entre elas dependen da semellanza semántica das palabras. Por tanto, nun mapa deste tipo, o punto correspondente á palabra porco estará máis cerca do correspondente ao xabaril que ao piollo, xa que a similitude semántica entre as palabras porco e xabaril é maior que entre as palabras porco e piollos.
Pero non todo é tan sinxelo: paira captar correctamente a complexidade da linguaxe, as 2 dimensións do papel quedan curtas, e estes mapas normalmente teñen unhas 300 dimensións. Pero que non che asusten os grandes números! Como hai un salto dunha soa dimensión da recta ás dúas dimensións do cadrado, e un salto das dúas dimensións do cadrado ás tres do cubo, podes imaxinar que existe un salto parecido desde as tres dimensións do cubo ás catro do tesón, e así poderiamos seguir até chegar ás 300 dimensións citadas.
Pero como construír un mapa de 300 dimensións se vivimos en tres dimensións? Non te preocupes, non imos empezar! En realidade, estes mapas non son físicos senón obxectos matemáticos que viven na memoria dos computadores. De feito, todos os mapas poden ser reproducidos mediante números. Paira iso adóitase acordar un sistema de referencia, indicando cada punto en función da súa posición respecto dos diferentes eixos. Así, segundo a distancia angular con respecto ao ecuador e ao meridiano de Greenwich, as coordenadas de París (48.86, 2.35) son as de Bruxelas (50.85, 4.35) e Moscova (55.75, 37.62). Estas coordenadas permítennos, entre outras cousas, calcular matematicamente as distancias entre cidades. O mesmo faise cos mapas de idiomas, pero como en lugar de ter 2 dimensións, son necesarios 300 números paira describir cada punto. Pois cada una desas secuencias de números que representan una palabra é o que chamamos embedding.
Partindo do texto e cartografiando as máquinas
A realización de mapas é un traballo laborioso. Os cartógrafos recompilan e analizan diversas fotografías, medicións e estatísticas, e elaboran representacións gráficas que coinciden con estes datos. A descrición das linguas tamén foi realizada polo home: aí están, entre outros, os dicionarios que nos son tan comúns. Pero os mapas que nos ocupa non son manuais. Analizando textos longos, as máquinas créanas automaticamente e é una receita sinxela e eficaz.
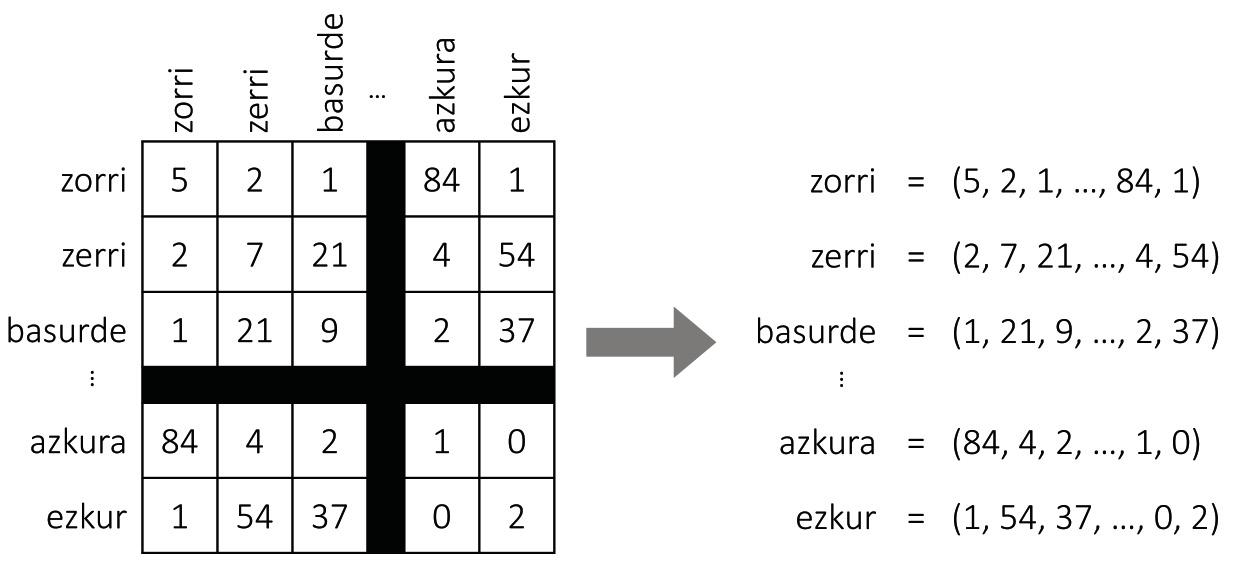
Como se mostra na Figura 2, supoñamos que construímos una táboa xigante con todas as palabras dunha lingua. Paira cada palabra teremos una fila e una columna, de forma que cada cela adáptese a un par de palabras. Paira encher a táboa, tomaremos un texto longo e contaremos o número de frases que aparecen simultaneamente cada parella de palabras. E voilà, temos o noso mapa! Paira cada palabra colleremos a lista de números da fila correspondente, que serán as coordenadas da palabra.
Aínda que pareza mentira, esta simple aproximación xera mapas bastante sensatos. De feito, segundo a hipótese distributiva da semántica [8, 7], palabras similares adoitan ter patróns de representación similares, polo que o procedemento anterior asignaralles coordenadas similares. Tamén paira o noso exemplo inicial, as palabras xabaril ou porco aparecerán con frecuencia xunto á palabra landra e poucas veces á beira da palabra picor, e coa palabra zorri ocorrerá ao revés. Por tanto, os porcos e azulexos terán unhas coordenadas similares e quedarán próximos entre si no mapa. As coordenadas dos piollos serán bastante diferentes, polo que se afastará delas.
Pero hai algo que falta nesta receita. E é que, aínda que as 300 dimensións mencionadas anteriormente parecían moito, este procedemento xeraría mapas de decenas de miles de dimensións, xa que os idiomas formarán as súas coordenadas con tantas palabras como números. Como reducir o número de dimensións? A resposta non nos é moi estraña: os nosos mapas comúns adoitan ter dúas dimensións, aínda que na realidade fálase dun mundo tridimensional. De feito, á hora de crear mapas, adoita excluírse a dimensión da altura, xa que non é moi significativa á hora de calcular distancias entre cidades. Algo parecido faise cos mapas das linguas: utilizando diferentes técnicas matemáticas identifícanse os eixos de maior variabilidade (os máis significativos) e exclúense do mapa o resto de dimensións. A pesar dalgunhas adaptacións paira corrixir o efecto da frecuencia, esta é a idea básica que subxace nas técnicas de cálculo paira o estudo das embeddings [3]; téñase en conta que as técnicas baseadas na aprendizaxe automática [11, 4] seguen o mesmo procedemento de forma implícita [10].
Xogando con mapas
A pesar da súa sinxeleza, os nosos mapas comúns ocultan máis secretos do que en principio parece. Aínda que non foron pensados paira iso, tamén serven paira apreciar, por exemplo, a temperatura que se produce en calquera parte do mundo. De feito, os puntos que se atopan en latitudes extremas, os máis próximos aos polos, adoitan ser máis fríos, mentres que os puntos máis próximos ao ecuador son máis calorosos. Así como o eixo da latitude relaciónase coa temperatura, nos mapas das linguas tamén se poden identificar eixos similares que relacionan a polaridad das palabras (grao de positividad e negatividad) con outras características [12]. Grazas a eles, as aplicacións de análise automática de opinións adquiriron gran forza nos últimos tempos.
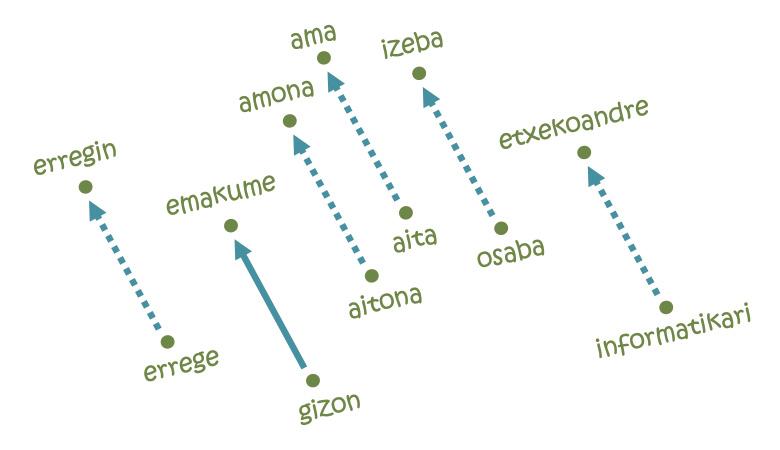
Pero o que fixo as embeddings tan populares foi a resolución de analogías [11]. A idea non pode ser máis sinxela: Paira ir desde París a Bruxelas é necesario percorrer 222 km ao Norte e 144 km ao Leste; así mesmo, en cada un dos eixos do mapa da lingua necesitarase una certa distancia desde a palabra home até a palabra muller, por exemplo. Pois se empezamos pola palabra rei e seguimos os mesmos pasos, chegamos á palabra erregin! De feito, a traxectoria estudada codifica a relación home-muller e trasládaa ao seu equivalente feminino a partir de calquera palabra masculina. Analogamente, pódense realizar analogías equivalentes paira as relacións pais-capital, singular-plural, presente e pasado.
Pero non todo é tan bonito: se empezamos pola palabra informática seguindo a mesma traxectoria de homes e mulleres, por exemplo, chegariamos a falar de amas de casa [5]. Noutras palabras, segundo o mapa, a informática é cousa de homes, e as tarefas domésticas son de mulleres. Que ver, aprender aquilo: as embeddings baséanse en textos escritos por seres humanos e reflicten as mesmas tendencias discriminatorias arraigadas na nosa sociedade. De feito, segundo varios expertos, afrontar este tipo de comportamentos inxustos será un dos retos futuros da intelixencia artificial.
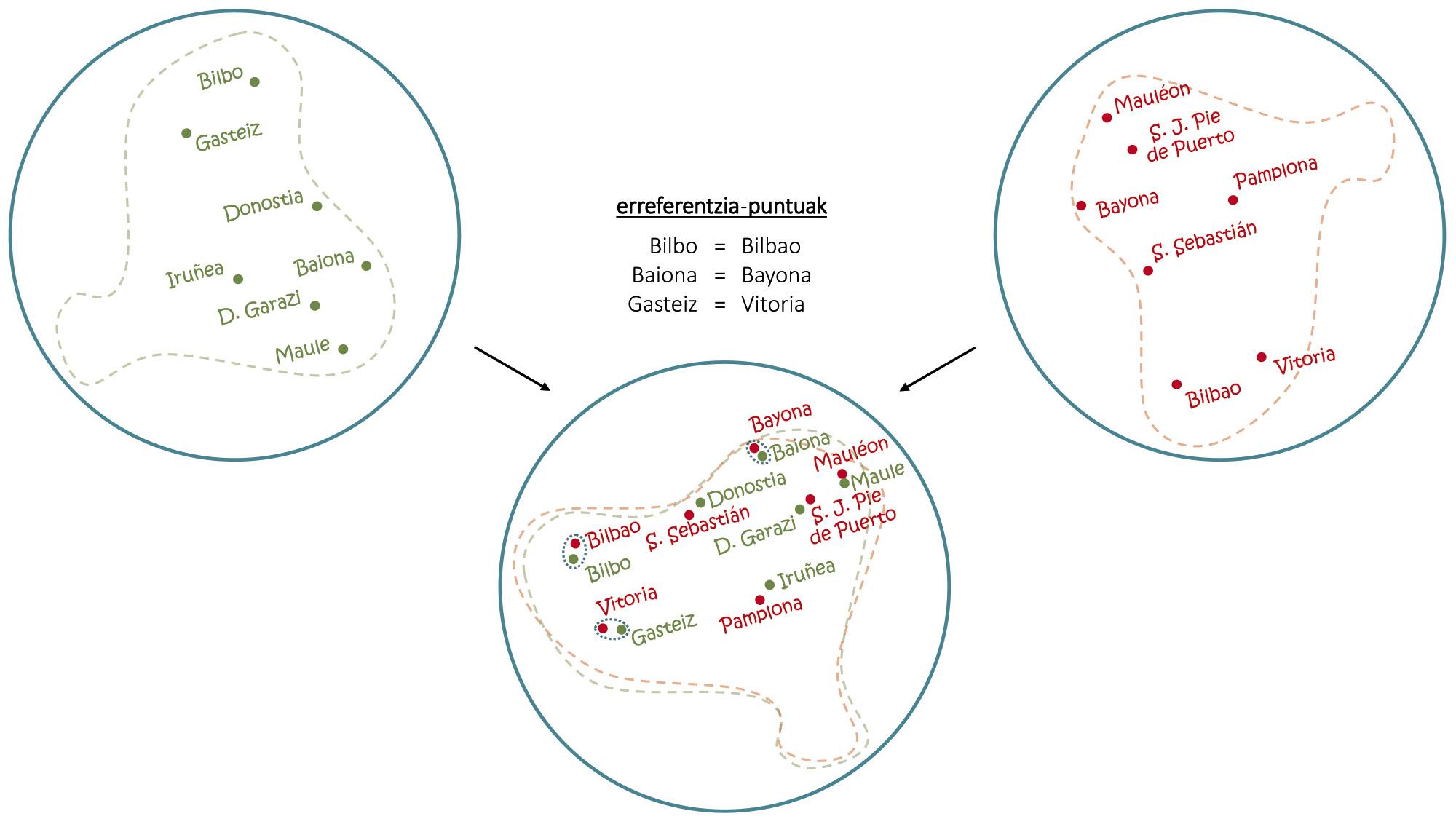
A pesar dos problemas, si cunha soa lingua pódense facer estes trucos, combinando mapas de varios idiomas conseguíronse cousas aínda máis sorprendentes. Tal e como se observa na figura 4, do mesmo xeito que coa superposición de senllos mapas en eúscaro e en castelán pódense extraer as contraprestacións en castelán das capitais vascas, coas embeddings utilízase o mesmo principio básico paira inducir traducións de palabras comúns [1, 6]. Neste sentido, recentemente desenvolvéronse tradutores automáticos capaces de aprender sen ningún tipo de condución humana [2, 9], de ler textos longos en varios idiomas e de realizar traducións entre eles sen outras axudas.
Novos destinos
Aínda que a nosa viaxe está a piques de chegar ao final, o camiño percorrido polas embeddings parece infinito. Xunto á mellora das técnicas de estudo e o desenvolvemento de novas aplicacións, os intentos de abordar frases ou textos máis longos a partir de mapas de palabras cobraron forza nos últimos tempos. Até onde nos levará ese camiño, pero non aparece en ningún mapa e, con novas metas no horizonte, o futuro non podía ser máis emocionante.
Referencias
Traballo presentado aos premios CAF-Elhuyar.
Zu idazle
Zientzia aldizkaria

