

Futura voz

Hace unos meses, con motivo de la creación de una base de datos de voz en euskera, Telefónica convocó la grabación de 10.000 voces de vascos. Para ello se puso un número de teléfono gratuito al que el llamante debía repetir frases y números que decía un ordenador. Lo que iba a decir el ordenador fue preparado por el Departamento de Filología Vasca de la UPV/EHU con la intención de recoger todos los sonidos habituales en euskera. Para ello se analizó un macrotexto proporcionado por UZEI. A pesar de que los responsables del proyecto necesitaban al menos 5.000 llamadas, recibieron cerca de 19.000, a pesar de que resultaron útiles –que repetieron todo lo que habían dicho el ordenador– 11.200. El proyecto contó con la participación de EITB, que grabó todo lo que decía el ordenador el personal local y realizó una campaña de captación de voz.
La información recogida en las llamadas telefónicas se recogió en Leioa, Departamento de Electricidad y Electrónica de la Universidad del País Vasco. La información digital recopilada ahora debe ser procesada y posteriormente constituirá la base de datos. Esta base de datos que se crea se podrá utilizar con los conocedores de la voz, por lo que podrán seguir investigando en esta materia. Por su parte, la Facultad de Filología también podrá aprovechar la información recibida para realizar investigaciones sobre la fonología del euskera actual. Si se avanza en el camino previsto, este proyecto permitirá en breve acceder a nuevos servicios en euskera: marcas telefónicas por voz, telelectura de contadores, validación de tarjetas de crédito, banca electrónica, compras telefónicas….
Sistema de reconocimiento automático de membranas
Lo que parece una cuestión de futuro son el pan de cada día en el Departamento de Electricidad y Electrónica de la UPV, ya que el equipo de Conocimiento de la Voz dedica horas y horas a ello. Los ordenadores llegarán a hablar, parece que no hay duda de ello. ¿Cómo se les hace hablar? ¿Cómo se les enseña?
Nuestro cerebro construye un mensaje en su interior siguiendo las reglas del lenguaje. A continuación, utilizando el sistema de creación de la voz del cuerpo, produce una onda muy rica en armónicos, la señal de voz. Esta señal acústica tiene varias características: energía, armónicos reducidos en la banda de frecuencia de 7-8 kHz, frecuencia básica, etc. En esta señal hay ruidos. Estos sonidos, según las reglas del lenguaje, constituyen unidades léxicas. Cada ruido tiene sus características acústicas. Por tanto, estos elementos, sonidos y unidades léxicas que aparecen codificados en la señal de voz, deben ser descodificados para conocer el mensaje generado.

Para poder utilizar la señal de voz en el ordenador es necesario muestrearla. Para ello, la señal analógica se convierte en digital. A continuación se parametriza la señal digital para reducir la información redundante de la voz, es decir, se extraen las características más características de la señal: energía, frecuencia básica, ciertos parámetros relacionados con las frecuencias, etc.
El reconocimiento de la voz se realiza mediante dos técnicas, una basada en palabras aisladas o silenciosas, y la otra es la denominada membrana continua. En ambos casos, para que el sistema entienda el mensaje, debe disponer de un descodificador de modelos acústicos: en el caso de palabras aisladas se utilizan modelos de palabras y en el caso de la lengua continua, modelos de sonidos y unidades léxicas.
En el primer caso, el funcionamiento del sistema es muy sencillo: se compara la señal con los modelos de palabras que se han estudiado y se elige el modelo de palabra más parecido. En cuanto al conocimiento del lenguaje continuo, el proceso se divide en dos fases: la descodificación acústico-fonética y la modelización del lenguaje. En la fase de descodificación acústico-fonético se obtiene la cadena de sonidos de la señal de voz. A continuación, en la fase de modelización del lenguaje, se obtienen las unidades léxicas y, utilizando reglas sintácticas y semánticas, se descodifica el mensaje que contiene la señal. En ese momento ya el ordenador es capaz de conocer el idioma.
El proceso se lleva a cabo mediante diferentes métodos matemáticos. En cuanto a los modelos acústicos, las aproximaciones estructural-estocásticas, modelos ocultos de Markov. Por otro lado, para aprender modelos y conocer el mensaje, otros algoritmos: Baum-Welch, Viterbi.
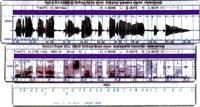
Y es que para que el sistema funcione correctamente tiene que conocer cada ruido. Por tanto, debe aprender diferentes muestras de cada sonido, ya que los sonidos producidos por una y otra persona son diferentes. Por ello, en esta fase de conocimiento automático del lenguaje es imprescindible contar con una gran base de datos, ya que cuantos más hablantes haya, más características podrá recoger y conocer el sistema. Es decir, para que el sistema pueda conocer cada uno de los sonidos necesita una gran cantidad de muestras de cada uno de ellos.
¿Euskera especial?
Hasta la fecha, y también en la UPV, se ha trabajado mayoritariamente con modelos en castellano, pero el trabajo del grupo de reconocimiento automático de la lengua va a llegar pronto, ya que desde hace años se está trabajando mayoritariamente con el euskera. Desde el punto de vista de las características de la lengua, el euskera puede tener peculiaridades. "En cuanto a los sonidos, dice Karmele Lopez de Ipiña, integrante del Grupo de Reconocimiento Automático Mintzo, no parece que sea más difícil que el resto de lenguas, porque en eso no hay nada raro. En cuanto al léxico, el euskera es especial, ya que la lengua es pegatina. Por ejemplo, para nosotros la palabra casa es casa, pero para ellos lo que es de casa —la palabra no cambia— para nosotros es de casa, y eso es una palabra nueva. El euskera tiene un gran futuro en el campo del conocimiento oral automático, sobre todo por el interés que ha despertado en la comunidad científica gracias a sus características específicas".
La base de datos de Telefónica ha tenido eco, pero en el Departamento de Electricidad y Electrónica de la UPV/EHU de Leioa han colaborado con el apoyo del Departamento de Filología Vasca de Vitoria-Gasteiz y con la subvención del Gobierno Vasco. "Desde hace muchos años nuestro grupo comenzó a desarrollar un sistema de reconocimiento automático de la lengua vasca. En concreto, se han diseñado dos bases de datos de voz, una para su uso en aplicaciones telefónicas y otra para el desarrollo de sistemas de cualquier tipo. Con ello, en lo que respecta a las bases de datos fonéticas, hemos conseguido equipararlas a otras lenguas. Si nos fijamos en las personas que trabajan en este campo en el mundo, podemos decir que no estamos tan mal, estamos en un par".
Zu idazle
Zientzia aldizkaria

