

OCR en euskera
Las vías de acceso, análisis y recogida de información van cambiando. En un tiempo el mejor modo de recibir la información era el libro impreso, pero hoy en día, por el contrario, exigimos alternativas como la búsqueda, copia y movimiento de la información, la clasificación, modificación y manipulación de la misma. Todas ellas son opciones que no nos daban los textos tradicionales conocidos hasta ahora, pero en la sociedad digital actual las cosas son muy diferentes.
El uso de la OCR está muy extendido en el mercado vasco, si bien ello supone una importante labor de corrección posterior. En Euskal Herria tenemos muchos periódicos, revistas y editoriales, y en la mayoría de los casos su fondo documental no está guardado en formato digital. La difusión de Internet, sin embargo, ha hecho necesario que todos estos fondos documentales estén debidamente digitalizados y recogidos para organizar sistemas de catalogación y búsqueda más rápidos.
El OCR (Optical Character Recognition) es el conocimiento por ordenador de los caracteres de texto escritos o impresos. Esto significa que cuando usamos el software OCR escaneamos cada carácter como si fuera una foto, y después analizamos esa imagen escaneada y la volvemos a un código de caracteres normal (por ejemplo, ASCII).
La precisión del sistema OCR está limitada por tres factores: la calidad del documento original, la calidad de la imagen creada por el escáner y la interpretación que sobre este último hace el software OCR. Aquí hablaremos de la última.
Lo que hace el OCR, en pocas palabras, es convertir la imagen escaneada en texto. Para ello, analiza los diferentes puntos que componen la imagen y distingue los huecos que hay entre ellos. Este proceso se denomina segmentación y se realiza en tres pasos: se separan las primeras líneas (segmentación en línea), se realiza el aislamiento de las palabras (segmentación de palabras) y finalmente se distinguen los caracteres (segmentación de caracteres). Esta última fase es más sencilla si todos los caracteres son de la misma anchura, y se complica mucho si se tocan entre sí, si se mezclan con otras marcas de puntuación o si el ancho depende de la forma del carácter.
Para realizar el conocimiento de carácter es necesario que el sistema OCR conozca todos los caracteres del idioma del texto escaneado. Si surgieran dudas con los caracteres, esperaría a que se complete la palabra, proceso en el que será útil disponer de un diccionario de esa lengua para poder equipararla. Así, mediante un juego de probabilidades y evaluando si se trata de una palabra del diccionario, el sistema seleccionará uno u otro carácter.
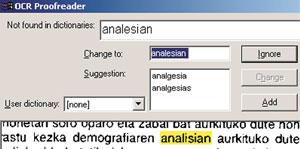
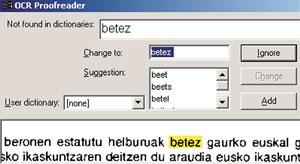
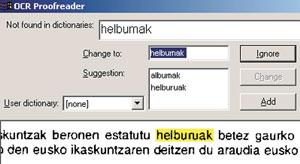
Al parecer, la existencia de un alfabeto y un diccionario en esa lengua sería suficiente para aplicar correctamente el OCR, pero en el caso del euskera no es así. En este caso no se puede proporcionar una lista completa de palabras posibles, es decir, no se puede crear un diccionario, ya que al ser una lengua declinada, de cada una de las raíces de palabras se extraen demasiadas formas de palabra. Las herramientas lingüísticas van a ser una gran ayuda en este paso, es decir, trabajando las principales características del euskera podemos conseguir grandes mejoras en el desarrollo de un sistema OCR. Por ejemplo, las agrupaciones de caracteres o palabras (ts, tz, tx, o rayas) que se realizan en euskera son menos habituales en el resto de las lenguas europeas.
Con la mayoría de los software OCR que se utilizan actualmente, cuando queremos analizar un texto en euskera, debemos utilizar el vocabulario de una lengua en castellano. Sin embargo, en estos casos es preferible no utilizar vocabulario que el de otra lengua para no cometer más errores en el texto. Por ejemplo, si estamos utilizando un diccionario en inglés, casi seguro que sustituirá la mayoría de las apariciones de seis palabras por el set. Si se está usando el castellano, la aparición de la palabra energía la sustituirá por la palabra energ (tilde).
El resultado del proyecto desarrollado en ELEKA es que al software OCR más utilizado en la actualidad, el programa Omnipage, se ha añadido una corrección en euskera junto con la información morfológica del euskera. Este programa, para el caso del euskera, está preparado para dar el paso de convertir la imagen escaneada en un carácter. Hasta la fecha, sin embargo, no estaba preparada para la fase posterior de verificación y corrección de las palabras (aunque está destinada a las lenguas mayoritarias: inglés, alemán). Las siguientes intenciones consistirán en añadir un corrector OCR como Xuxen para los procesadores de textos Microsoft Word y OpenOffice, para poner a disposición de los usuarios que no utilicen Omnipage el sistema OCR en euskera.
Por tanto, a través de la incorporación de herramientas lingüísticas en euskera se ha desarrollado la herramienta que mejor digitaliza los textos en euskera. Es decir, ELEKA ha desarrollado una herramienta que entiende y dirige el euskera de forma automática a la hora de digitalizar los textos. Para el desarrollo de este proyecto ha contado con la colaboración de la Viceconsejería de Política Lingüística del Gobierno Vasco, que se encargará de la distribución de esta aplicación.
Zu idazle
Zientzia aldizkaria

