

Elhuyar développe un système multilingue pour extraire le sentiment des messages des réseaux sociaux
Sur les réseaux sociaux, les utilisateurs fournissent des informations sur des entités, des entreprises ou des sujets particuliers. Les systèmes d'extraction d'information permettent aux entreprises de connaître, par exemple, le prestige qu'elles ont dans la société; ou aux institutions publiques, de connaître l'attitude de la société face à ses politiques.
Il existait déjà des systèmes d'élaboration en plusieurs langues, mais pas en basque. Et la chercheuse a rappelé que près de 15% des tweets écrits en Euskal Herria sont en basque (un total de 2,5-2,8 millions de tweets par an). Les autres sont principalement en espagnol et en français, et certains (dans une moindre mesure) en anglais. Saint Vincent a donc développé dans ces quatre langues les ressources qui composent le système pour analyser le sentiment des messages sur les réseaux sociaux.
«La première étape a été de créer des lexiques de polarité», a expliqué Saint Vincent, c’est-à-dire de créer des listes de mots qui ont eux-mêmes un sentiment positif ou négatif: mauvais, mauvais et bon… «Ce faisant, il faut tenir compte du contexte», a averti le chercheur. En fait, selon le contexte, un même mot peut avoir une polarité différente: « Baisser les ventes est mauvais, alors que baisser le chômage est bon. La polarité des descentes varie donc selon le contexte”. Il faut aussi tenir compte des négatives (non, mais oui…) et de l'ironie.
L'écriture informelle propre à Twitter génère également des problèmes. « Sur Twitter, beaucoup font une sorte de transcription du langage oral ou mélangent deux langues sur un même site. Parfois, pour accentuer un mot, on répète la dernière voyelle et on utilise les émoticônes pour exprimer des sentiments ». En outre, il existe des particules renforçantes et réductrices, très peu… qui ont été considérées dans l'élaboration du lexique.
Apprentissage automatique
La prochaine étape a été l'intégration du lexique dans les systèmes d'apprentissage automatique. Des milliers d'exemples ont été utilisés pour former ces systèmes, classés manuellement : positif, négatif ou neutre. «Avec eux, nous enseignons au système un modèle mathématique, de sorte que quand un nouvel exemple viendra, il dira s’il est positif, négatif ou neutre sur la base des précédents.»
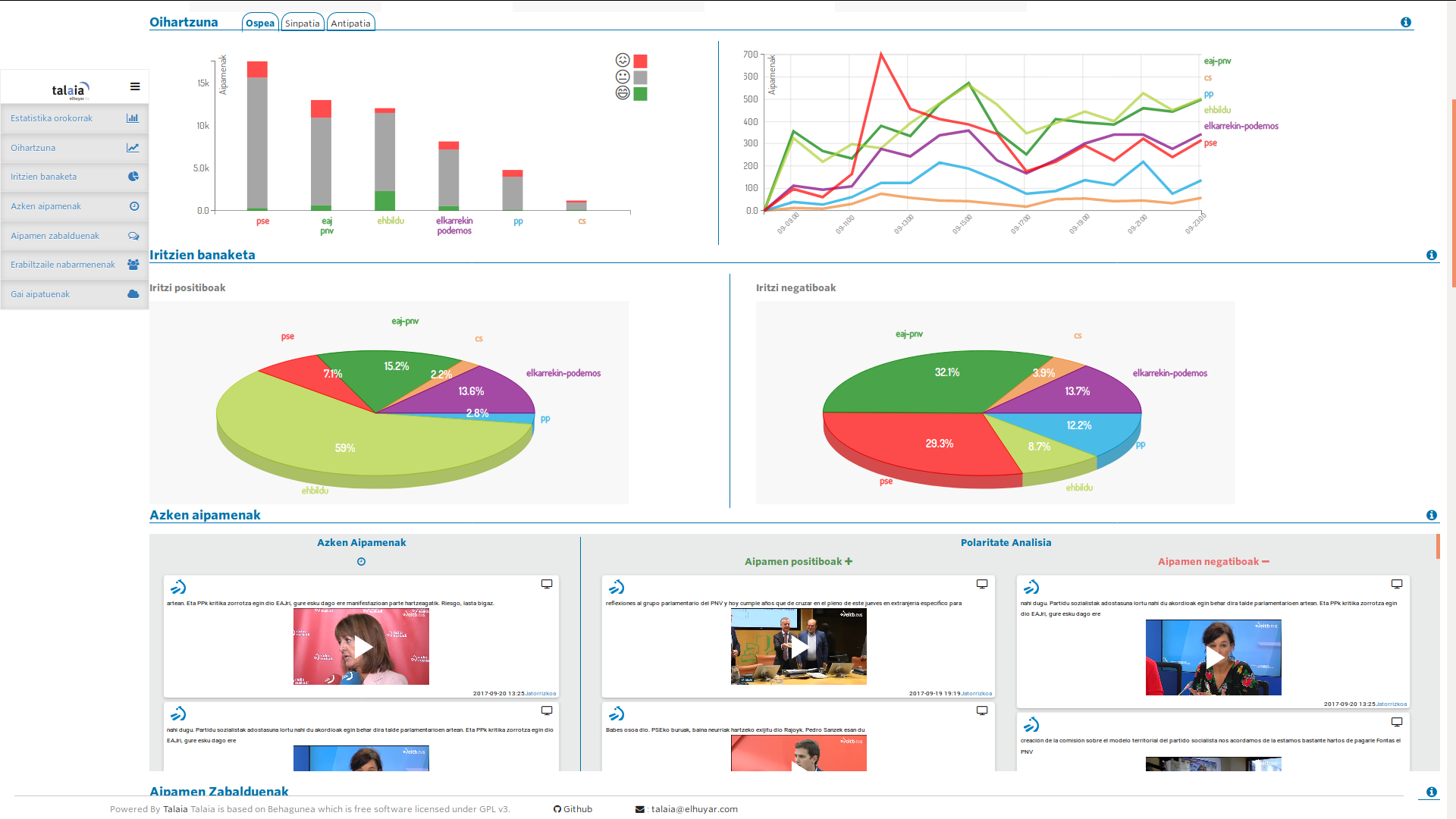
«Nous avons obtenu que le taux d’invention du classement en basque soit similaire à celui des autres langues», a souligné saint Vincent. Actuellement, le taux d'invention est d'environ 75%, mais les membres d'Elhuyar travaillent à améliorer le résultat en se basant sur des réseaux neuronaux. De même, bien qu'au début, le système n'ait extrait que les opinions des textes, il est maintenant capable d'analyser des vidéos et des audios et de détecter les opinions qui y sont présentes.
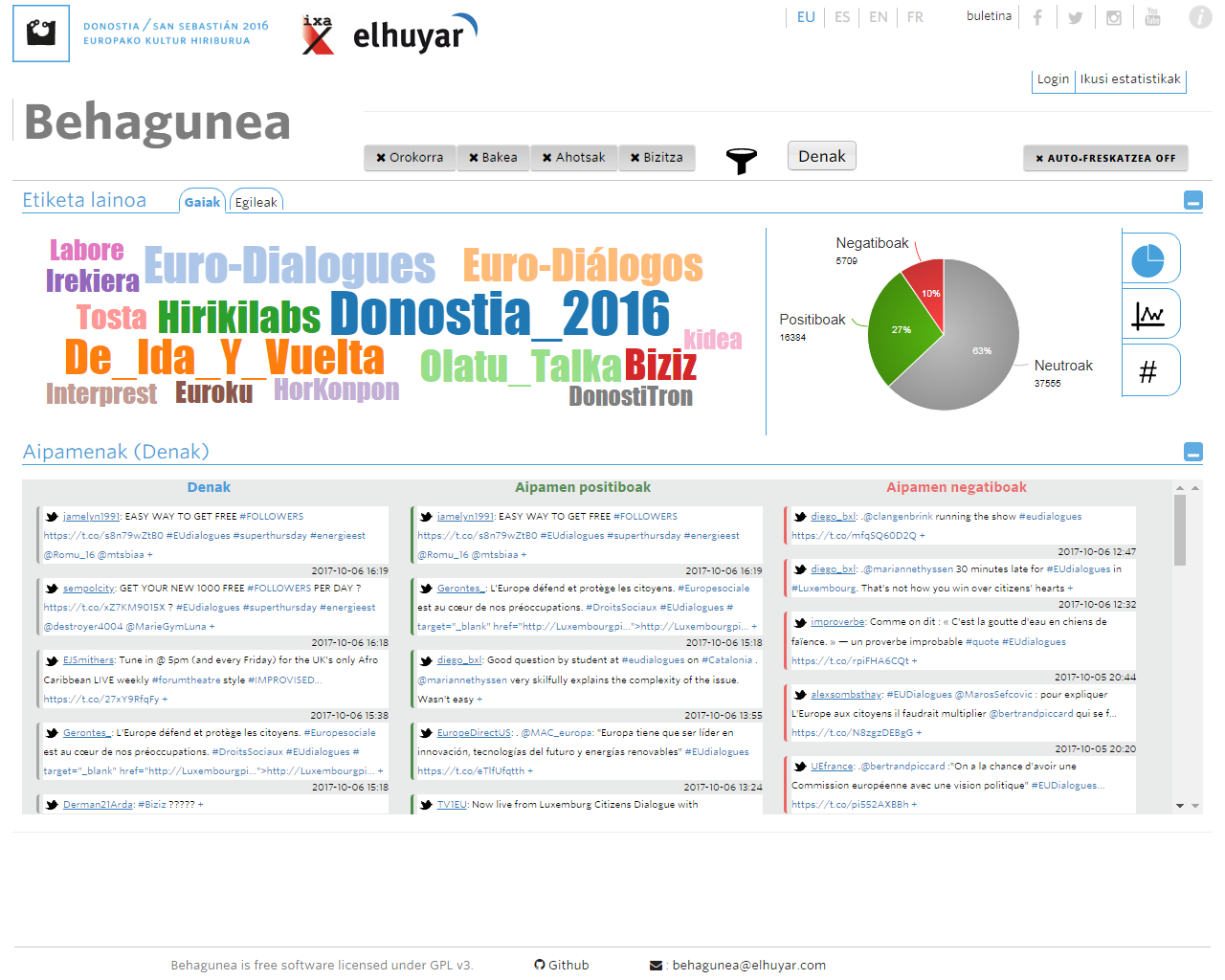
Ils l'ont déjà utilisé dans des cas réels. Par exemple, à travers Behagunea on a réalisé le suivi des projets de la Capitalité Donostia 2016. Avec la nouvelle, la campagne électorale pour le Parlement basque 2016 a été suivie et en 2018, avec l'Institut de criminologie de l'UPV, l'attitude des victimes du terrorisme sur les réseaux sociaux a été analysée.
Le travail de recherche a été réalisé en collaboration avec le groupe IXA et tous les résultats sont disponibles sur le site Elhuyar de Technologies Linguistiques.
Zu idazle
Zientzia aldizkaria

