

Elhuyar desarrolla un sistema multilingüe para extraer el sentimiento de los mensajes de las redes sociales
En las redes sociales, los usuarios aportan información sobre entidades, empresas o temas concretos. Los sistemas de extracción de información permiten a las empresas conocer, por ejemplo, el prestigio que tienen en la sociedad; o a las instituciones públicas, conocer la actitud de la sociedad ante sus políticas.
Ya existían sistemas de elaboración en varios idiomas, pero no en euskera. Y la investigadora ha recordado que cerca del 15% de los tweets escritos en Euskal Herria son en euskera (un total de 2,5-2,8 millones de tweets al año). El resto son principalmente en castellano y francés, y algunos (en menor medida) en inglés. Por tanto, San Vicente ha desarrollado en estas cuatro lenguas los recursos que conforman el sistema para analizar el sentimiento de los mensajes en las redes sociales.
“El primer paso fue crear léxicos de polaridad”, ha explicado San Vicente, es decir, crear listas de palabras que por sí mismas tienen un sentimiento positivo o negativo: malo, malo y bueno… “Al hacerlo hay que tener en cuenta el contexto”, ha advertido el investigador. De hecho, según el contexto, una misma palabra puede tener distinta polaridad: “Bajar las ventas es malo, mientras que bajar el paro es bueno. Por tanto, la polaridad de los descensos varía según el contexto”. Además hay que tener en cuenta las negativas (no, pero sí…) y la ironía.
La escritura informal propia de Twitter también genera problemas. “En Twitter muchos realizan una especie de transcripción del lenguaje oral o mezclan dos lenguas en un mismo sitio. A veces, para dar énfasis a una palabra, se repite la última vocal y se utilizan los emoticonos para expresar sentimientos”. Además, existen partículas reforzantes y reductoras, muy pocas… que han sido consideradas en la elaboración del léxico.
Aprendizaje automático
El siguiente paso ha sido la integración del léxico en los sistemas de aprendizaje automático. Para entrenar este tipo de sistemas se han utilizado miles de ejemplos, clasificados manualmente: positivo, negativo o neutro. “Con ellos enseñamos al sistema un modelo matemático, de manera que cuando venga un nuevo ejemplo, dirá si es positivo, negativo o neutro en base a los anteriores”.
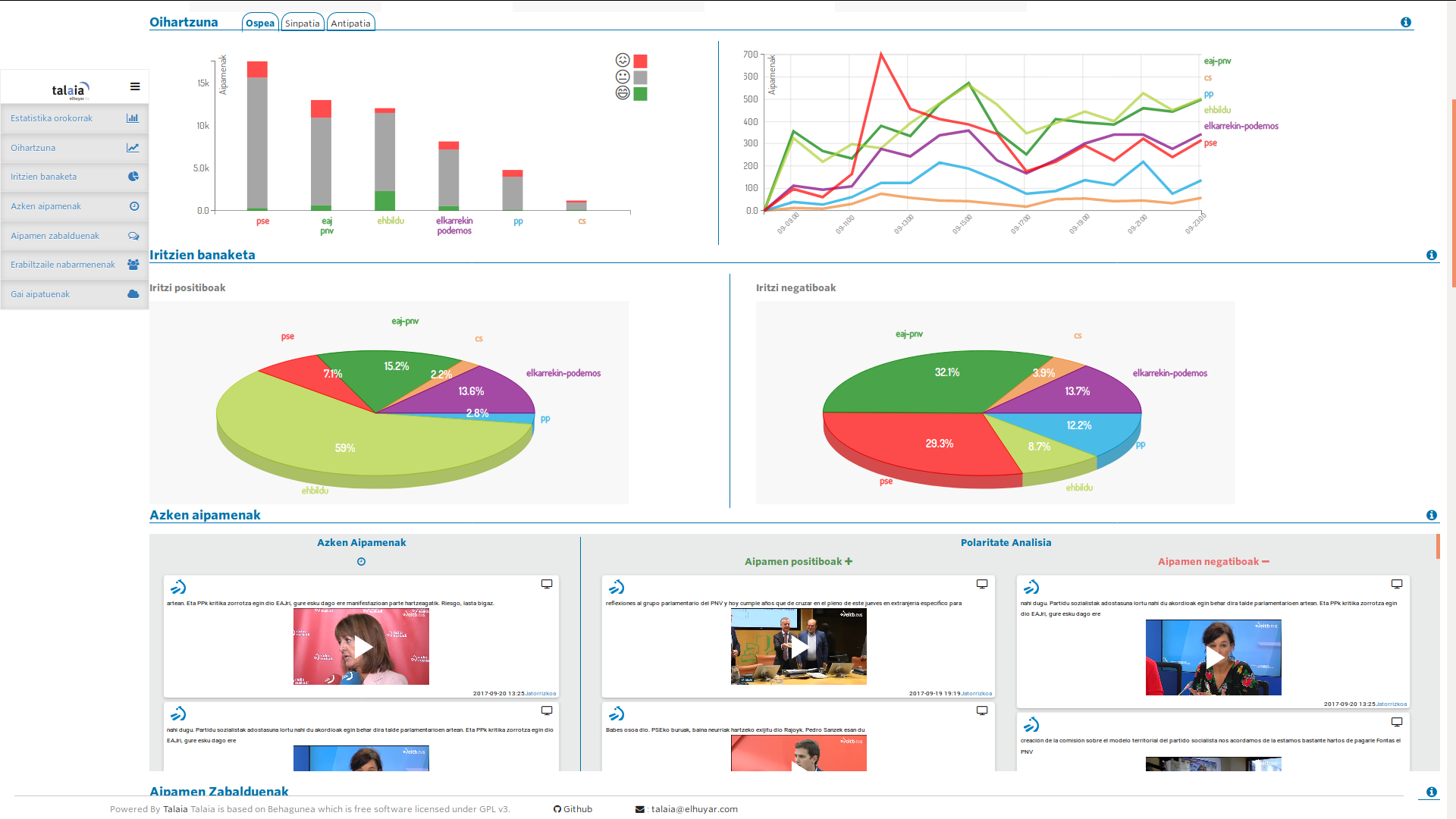
“Hemos conseguido que la tasa de invención de la clasificación en euskera sea similar a la de otras lenguas”, ha señalado San Vicente. En la actualidad, la tasa de invención se sitúa en torno al 75%, pero los miembros de Elhuyar están trabajando para mejorar el resultado basándose en redes neuronales. Asimismo, aunque en un principio el sistema sólo extraía las opiniones de los textos, ahora es capaz de analizar vídeos y audios y de detectar las opiniones presentes en ellos.
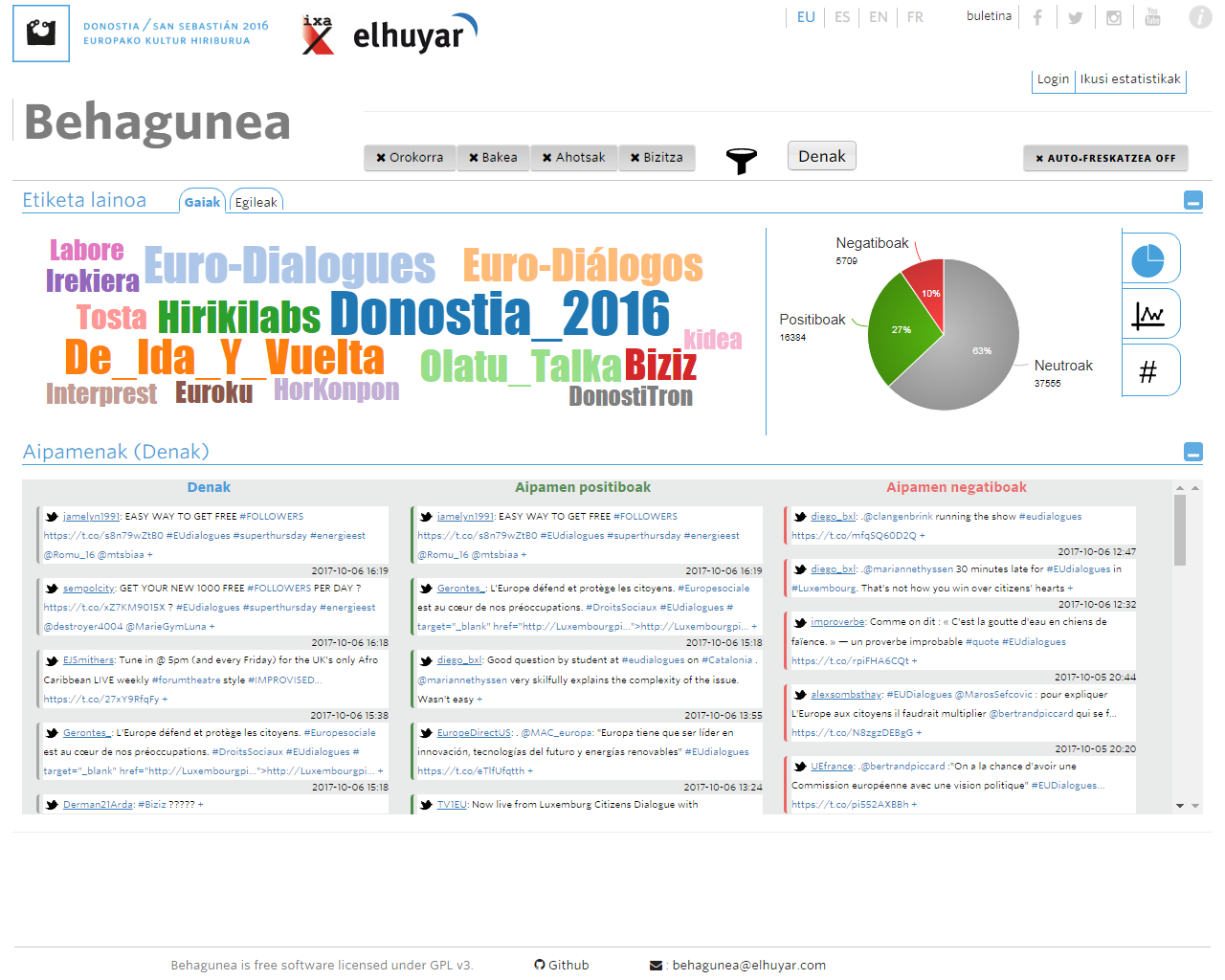
Ya lo han utilizado en casos reales. Por ejemplo, a través de Behagunea se realizó el seguimiento de los proyectos de la Capitalidad Donostia 2016. Junto a la noticia, se siguió la campaña electoral para el Parlamento Vasco 2016 y en 2018, con el Instituto de Criminología de la UPV, se ha analizado la actitud de las víctimas del terrorismo en las redes sociales.
El trabajo de investigación se ha realizado en colaboración con el grupo IXA y todos los resultados están disponibles en la web de Elhuyar de Tecnologías Lingüísticas.
Zu idazle
Zientzia aldizkaria

