

Macroordenadores y grupos de ordenadores

¿Qué es un macroordenador? Una definición es: "Ordenador de alta capacidad que se conecta a otros ordenadores. Su tamaño depende de la memoria; los mayores tienen una memoria principal de varios gigabytes y varios terabytes de memoria de disco". Desde el punto de vista actual, es posible que estas máquinas grandes se definan con otra idea: un ordenador que hace cosas que no se pueden hacer con el ordenador de casa. Sin embargo, ambas definiciones no son muy concretas.
El primer macroordenador (si es posible) fue construido en 1975 por el informático estadounidense Seymour Cray, que le dio su nombre: Cray 1. Aporta ideas arquitectónicas innovadoras; fue el primer ordenador vectorial, es decir, tenía registros que trabajaban con vectores (matrices unidimensionales). Esta idea es muy útil para programarla en lenguaje FORTRAN, que era el lenguaje más adecuado para el software de la ciencia, ya que con las matrices los cálculos eran fáciles. Además, disponía de procesadores en paralelo.
Empresas como Alliant, Ardent o Convex fabricaron ordenadores más pequeños de la misma filosofía y se han fabricado muchos nuevos modelos de Cray. En la actualidad, los 'sucesores' del ordenador Cray 1 ocupan aproximadamente el 10% del mercado de supercomputación. Sin embargo, cada una de estas macroodenadoras tiene una capacidad de operación limitada, si se necesita una mayor capacidad se deben formar equipos de ordenador.
Grupos de ordenadores

Éxito de los ordenadores interconectados. Y es que los macroordenadores son máquinas muy caras y para el mantenimiento también se necesita mucho dinero. Sin embargo, cualquier empresa puede instalar, gestionar y utilizar la red de ordenadores 'pequeños' para realizar estos gigantescos trabajos. Por ello, en lugar de utilizar un ordenador con más de un procesador, se trabajó la forma de trabajar en paralelo para muchos ordenadores de un mismo procesador.
Cada ordenador de un grupo recibe el nombre de nodo y puede tener cientos conectados a dicha red. También se pueden conectar equipos. La estructura que agrupa a 16 grupos se llama constelación. A la vista de todo ello, se entiende fácilmente que un macroordenador no tenga la misma capacidad de cálculo que varios grupos. Por otra parte, un equipo de ordenadores es accesible para una empresa, tanto desde el punto de vista de la máquina como del mantenimiento, si se conecta a redes de otras empresas el coste se distribuye.
Política de cálculo
En los años 80, los gobiernos pusieron en marcha muchos centros de supercomputación con macroordenadores. A las empresas que no podían pagar este tipo de máquinas se les daba la posibilidad de conectarse a estos centros. Por tanto, los gobiernos gestionaban las mayores necesidades informáticas de las empresas.

Pero en esos años se desarrollaron los ordenadores más pequeños (ordenadores personales, entre otros) y la idea de grupos de ordenadores. Poco a poco se abarataron los recursos necesarios para formar las redes. A finales de la década de 1990 las empresas habían perdido la tendencia a los centros de supercomputación. Los grupos tenían importantes ventajas: los gestionaba uno mismo, desaparecía la dependencia del gobierno y, además, el ordenador no debía compartirse. En consecuencia, la capacidad de cálculo era mayor.
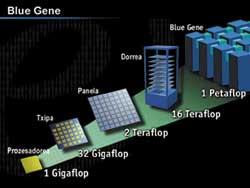
Los gobiernos recurrieron a reducir el número de centros. En la actualidad, en muchos Estados hay pocos de ellos porque todavía son necesarios para ciertas tareas (el ejemplo es el proyecto Blue Gene). Algunos centros se han convertido en bases de datos públicas, pero la tendencia de la mayoría de los grupos de investigadores es la de contar con equipos de ordenador privados. ¿Cuál será la principal oportunidad de futuro? En un par de décadas la situación puede cambiar.
Blue Gene : aplicación para quemar chips
Más allá de la informática teórica, merece la pena analizar cómo se aplica la enorme capacidad de los macroordenadores. La puesta en marcha de estas máquinas es costosa, por lo que hay que aprovecharlas, por ejemplo, teniendo en cuenta que estos ordenadores requieren sistemas especiales de aire acondicionado.
¿Qué hay que calcular en estas máquinas grandes? El proyecto Blue Gene que puso en marcha IBM en 1999 es un buen ejemplo. Este proyecto se puso en marcha para investigar uno de los problemas más importantes de la bioquímica: el plegado de proteínas. Para abordar este trabajo se ideó un ordenador con una nueva arquitectura, cuyo segundo objetivo es analizar la eficacia de la nueva arquitectura.
¿Por qué hay que investigar cómo se doblan las proteínas? Es fácil, porque las proteínas son responsables de las reacciones químicas del cuerpo. Si las proteínas se "deterioran" se producen enfermedades graves que a menudo se deterioran por un mal plegado. Sabemos que enfermedades como el Alzheimer, la hemofilia y otras tienen que ver con proteínas mal plegadas.
Problema de conformado
En general, las proteínas son cadenas de aminoácidos. Existen 20 tipos de aminoácidos de los que la proteína presenta características químicas según su secuencia. Pero la química no sólo la determina la secuencia, sino que es muy importante la localización espacial de los aminoácidos. Los aminoácidos muy alejados de la cadena deben estar físicamente cerca para poder cumplir su función, es decir, la cadena debe plegarse en tres dimensiones adecuadamente. Si se toma una conformación equivocada, la proteína no podrá trabajar.

Pero a medida que la proteína se sintetiza, ¿cómo sabe cuál es su conformación? ¿Qué patrón sigue para plegar proteínas? Si lo supiéramos, inventaríamos proteínas para producir la reacción química deseada con la simple definición de la secuencia. Blue Gene trata de encontrar estos patrones.
Números grandes
Las proteínas contienen cientos de aminoácidos. Por ejemplo, la hemoglobina, una proteína que transporta oxígeno en la sangre, contiene 612 aminoácidos. El ángulo diedro entre tres aminoácidos consecutivos puede tener muchos valores, por lo que la proteína puede contener millones de estructuras espaciales. Sólo una de ellas es adecuada
Los científicos proponen patrones del proceso de plegado de proteínas, pero la capacidad de cálculo y la memoria necesarias para demostrar que están o no son correctas. El trabajo de un macroordenador es imprescindible. La empresa IBM diseñó un gran ordenador con una arquitectura singular: Blue Gene. En este proyecto se trabajará el modelo de una proteína de tamaño medio que contiene 300 aminoácidos.
Lectores rápidos
Blue Gene se diseñó para ser 500 veces más rápido que el ordenador más rápido del mundo. ¿Cómo se ha conseguido? En muchos ordenadores, el mayor tiempo necesario para acceder a los datos de las chips de memoria. El proyecto Blue Gene ha diseñado chips para hacer frente a este problema.
Cada chip consta de dos procesadores: uno de cálculo y otro de comunicación. Cada grupo de chips se encarga de parte del cálculo completo. Esta estrategia acelera enormemente la capacidad de cálculo. En el caso de las proteínas, por ejemplo, los ficheros de trabajo deben ser muy grandes (ficheros que permanecen durante los cálculos), y la duración del trabajo depende en última instancia del tiempo que buscamos los datos que necesitamos.
En aplicaciones complejas, los ordenadores deben realizar millones de operaciones aritméticas en el menor tiempo posible. Para ello, hace unos cuarenta años, los informáticos inventaron ordenadores vectoriales. Estos ordenadores, en lugar de utilizar números sencillos, utilizan vectores, es decir, listas de números (para informáticos, matrices unidimensionales).
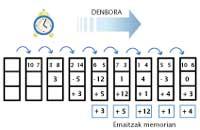
Los ordenadores vectoriales utilizan líneas de pipes para un cálculo rápido. La idea de estas pipe-line es muy sencilla, es el mismo principio que la fabricación de series. Con un ejemplo se entiende fácilmente. Supongamos que tenemos que calcular la diferencia entre los datos de dos listas de números, para ello hay que seguir cuatro pasos: a) tomar un número de cada lista, b) restar c) si el resultado de la resta es negativo, cambiar el signo y d) almacenar el resultado en memoria. Si cada paso se realiza en un microsegundo, para tratar un par de números se necesitan cuatro microsegundos.
Los listados que utilizaremos son: 10, 3, 2, 6, 7, 1, 5, 10, … y 7, 8, 14, 5, 3, 4, 5, 6, …
En cambio, en una pipe-line, cuando el primer par de números ha terminado el primer paso, se va al segundo, pero un segundo par de números entran en el primer paso. Así, en cada microsegundo, las paredes interiores avanzarán un paso y se incorporará un par en el primer paso libre. De este modo, la operación del primer par requerirá tres microsegundos, pero el del segundo par finalizará en el cuarto microsegundo (y no en el sexto, como si se realizaran uno a uno).
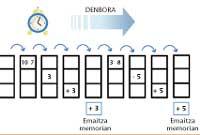
Ha sido un ejemplo sencillo, pero hay que tener en cuenta que los ordenadores realizan operaciones aritméticas con números de coma móvil. (La escritura de coma móvil para representar un número utiliza una mantis y una característica, es decir, es una escritura de tipo 0,233 x 10 3).
La aritmética de estos números requiere más pasos que los números enteros. Los macroordenadores vectoriales incorporan sistemas pipe-line de cálculo con coma móvil. Además, al combinar vectores completos con registros para el tratamiento de números simples, pueden realizar operaciones aritméticas extremadamente rápidas. El más famoso de los primeros macroordenadores de este tipo, Cray 1, data del año 1976.
Muchas veces, un grupo de pequeños ordenadores puede trabajar en un ordenador vectorial. Esa es la filosofía principal de los grupos de ordenadores. No obstante, todos los ordenadores que componen el grupo deben estar conectados de alguna manera a una red. A cada ordenador participante se le denomina nodo. Pero, ¿dónde está el software que necesitan todos los nodos? ¿Utilizarán la memoria conjunta o cada nodo utilizará la suya? Desde el punto de vista arquitectónico de todo el sistema existen tres formas de organización. Discos compartidosEste tipo de ordenación es muy utilizada. La red dispone de dispositivos generales de entrada y salida, accesibles desde cada nodo. Estos dispositivos incluyen archivos y bases de datos. Así, el sistema no necesita compartir memorias de nodos. El principal problema de este sistema es la disponibilidad de todos los nodos. En un momento dado, todos los nodos pueden escribir o leer simultáneamente en los discos generales. Para poder controlar todo esto es necesario un mecanismo de sincronización: el gestor del bloqueo. El deterioro de un nodo en estos sistemas no afecta a otros. Esto proporciona una gran disponibilidad al sistema, aunque en ocasiones esta característica ralentiza el trabajo debido a los estrechamientos que genera la actividad del gestor del bloqueo. Sistemas sin comparticiónEn estos sistemas no hay discos disponibles para los nodos. Por ello, en estos sistemas el número de nodos no está tan limitado como en ocasiones anteriores. Estos sistemas tienen cientos de nodos. Sistemas espejosAunque en estos sistemas los datos están almacenados en un disco general, se copian a un segundo para aumentar la disponibilidad. Normalmente no se trabaja en esta copia, salvo que se estropee el disco original. Si se estropea, esta organización recupera los datos muy rápidamente. Estos sistemas normalmente sólo tienen dos nodos. Muchos de los servidores que soportan la red Internet son sistemas de este tipo. |
Dos veces al año, durante los meses de junio y noviembre, se organizan congresos de supercomputación para dar a conocer lo sucedido en este ámbito. El último congreso, de noviembre del año pasado, tuvo lugar en Estados Unidos, Denver, y el anterior, de junio, en Heilderberg, Alemania. En estos congresos se recogen los datos de los centros de supercomputación y se actualiza el listado Top500. En este listado se analizan los 500 centros de mayor capacidad y sus características. Los cambios entre las diferentes versiones del listado se pueden consultar en la siguiente página web: http://www.top500.org/ |
En cuanto a los grandes centros de cálculo, en el País Vasco la tendencia es la misma que en el resto del mundo. En el pasado, cuando se impulsaban centros de funcionamiento de macroordenadores, la Viceconsejería de Industria del Gobierno Vasco y el centro tecnológico Labein firmaron un convenio para la instalación de un centro de computación. Se decidió ubicar este centro en el Parque Tecnológico de Zamudio.

Se puso en marcha un macroordenador Convex que podía ser utilizado en varias empresas de Euskal Herria. Las empresas a las que se iba a conectar pertenecían principalmente al ámbito de la ingeniería, con el objetivo de realizar en este gigantesco ordenador los grandes cálculos necesarios para el diseño.
La mejor configuración de esta máquina convex fue el ordenador paralelo de 8 procesadores vectoriales. En un principio, algunas empresas tuvieron un gran interés. Sin embargo, en lugar de ser un centro de supercomputación, la tendencia general fue a buscar otras soluciones (por ejemplo, grupos de ordenadores gestionados por uno mismo). Durante algunos años fue utilizado por varios grupos de investigadores de la Universidad del País Vasco, pero finalmente se suspendió el centro de supercomputación.
Zu idazle
Zientzia aldizkaria

