

Recursos lingüísticos en Internet
Los programas que realizan el tratamiento del lenguaje a través del ordenador son cada vez más numerosos. La comunicación con los ordenadores a través de las lenguas naturales (en euskera en nuestro caso) será cada vez más frecuente. Por otro lado, el ordenador se convierte en una persona especial para paliar los desplazamientos de esta sociedad multilingüe entre las lenguas.
Además, el enorme avance experimentado en las telecomunicaciones (sobre todo los fenómenos de Internet) ha incrementado la necesidad de un tratamiento automático del lenguaje. De hecho, a través de la red se puede obtener mucha información, pero no es fácil encontrar ese dato concreto que necesitamos. En este trabajo el tratamiento lingüístico no es más que auxiliar.
El campo de investigación sobre el tratamiento automático del lenguaje lo denominamos Procesamiento del Lenguaje Natural (LNP). Se está creando toda una nueva industria en torno a la lengua, cuyo objetivo es tratar el lenguaje a través del ordenador. Ya se habla de tecnología lingüística, ingeniería lingüística. Sus principales campos de aplicación son cuatro: i) Edición de textos o gestión textual (correctores ortográficos y estilísticos, ayudas a la creación y uso de textos multilingües, consultas de diccionarios, ...); ii) Tratamiento y gestión de grandes masas de texto (búsqueda de conceptos, clasificación documental, extracción de información y creación automática de textos); iii) Traducción automática o traducción asistida, y iv) Conocimiento y creación de la lengua.
En el grupo IXA hemos trabajado durante diez años en esta materia, siempre desde el punto de vista del euskera. Sumando los miembros de la Facultad de Informática de Donostia de la UPV-EHU y los de UZEI somos un total de 21 personas. Nuestra estrategia nunca ha sido hacer un sistema muy complejo, por ejemplo, hacer un sistema de traducción. Hemos preferido empezar por objetivos sencillos pero fundamentales, como la morfología, entendida como un problema demasiado simple para otras lenguas, y construir en ese camino unas bases lingüísticas amplias y sólidas.
Más tarde hemos acometido proyectos más complejos como la lematización, la sintaxis o el uso de diccionarios, pero trabajar sobre una base amplia construida con anterioridad nos ahorra tiempo y da consistencia a nuevos productos. Dado que nuestros recursos lingüísticos pueden ser también de utilidad para otros colectivos, decidimos difundir la “exposición electrónica”, que es el objetivo del proyecto que presentamos en este artículo. El proyecto fue aprobado en la convocatoria de 1997 de proyectos de investigación Universidad-Empresa del Gobierno Vasco (referencia UE97/8) y se desarrollará durante los años 1998-99.
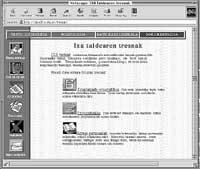
Los recursos que queremos ubicar en Internet a medio plazo son la base de datos lexical, el corrector ortográfico, el analizador morfológico, el lematizador y el analizador sintáctico. Pero en este primer paso sólo aparecerán las tres primera.El proyecto está en marcha y ya se pueden realizar pruebas con corrector ortográfico en la dirección http://ixa.si.ehu.es/tresna (ver las pantallas de ordenador que aparecen en este mismo artículo o verlas directamente en tu ordenador).
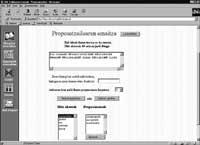
Prueba a introducir tus palabras desconocidas en tu vocabulario personal y comprueba que a partir de ahí también conocerá otras formas de declinación de esas palabras.
Para finalizar, explicaremos qué es la Base de Datos Lexical del Euskera (EDBL) que se menciona en nombre del proyecto. La base de datos lexical es un gran almacén de léxico. Se trata de una especie de diccionario electrónico, concebido para el tratamiento automático de la lengua y, por tanto, organizado teniendo en cuenta las exigencias de ese objetivo de automatizar el tratamiento de la lengua. Esto exige, por supuesto, que la organización del léxico se realice teniendo en cuenta el uso que se va a hacer posteriormente, y una sistematización de la descripción léxica: utilización de un sistema de categorías de ingresos unificado y homogéneo, la definición de las características necesarias para describir correctamente los elementos de cada categoría, etc.
En el caso del euskera, la necesidad de este tipo de almacén de léxico surgió cuando comenzamos la preparación del corrector ortográfico Xuxen en el grupo IXA. Como se ha comentado anteriormente, este corrector era más básico por nosotros como subproducto del analizador morfológico, y tampoco quisimos organizar la base de datos lexical como un diccionario o una simple lista de palabras para ese corrector, sino como base lexical sólida para cualquier otra herramienta o aplicación en el ámbito del tratamiento automático del euskera en el futuro. Y así surgió el EDBL, la Base de Datos Lexical del Euskera, que desde entonces ha sido la base lexical para nuestros trabajos, que se ha ido actualizando constantemente, y que hoy o mañana abrirá sus puertas a una comunidad más amplia, con el fin de que las bases se vean también aprovechadas por otros.
A la hora de diseñar la base de datos se le dio gran importancia, pues, a ser lo suficientemente flexible para aceptar posibles ampliaciones futuras y, en particular, a describir de la forma más neutral posible la información lingüística contenida en la misma, es decir, de la manera más independiente posible de los formalismos o teorías lingüísticas.
EDBL agrupa en la actualidad cerca de 70.000 entradas, clasificadas en tres grandes apartados: entradas de diccionario (nombres, adjetivos, verbos, etc.). ), verbos (formas verbales jugadas) y morfemas no independientes (sufijos, prefijos, etc. ).
Se registran las características o atributos predefinidos de cada categoría de entrada, describiendo en todos los casos, como ya se ha mencionado anteriormente, la morfología de entrada (información morfotáctica) mediante un formalismo a dos niveles ampliamente utilizado en la morfología computacional.
Actualmente el EDBL está bajo un sistema comercial de gestión de bases de datos que ofrece al lingüista las facilidades habituales en este tipo de sistemas, ya que son los lingüistas sus principales usuarios: una interfaz agradable para el trabajo, facilidades para mantener la información al día y garantizar su consistencia, posibilidades de filtrar adecuadamente la información para las aplicaciones necesarias, etc. La base de datos se ha convertido también en una herramienta imprescindible para mantener actualizados los últimos acontecimientos acaecidos en el proceso de unificación del euskera, especialmente las decisiones de Euskaltzaindia, y una de las tareas importantes que puede desempeñar en el futuro EDBL puede ser ser ser la herramienta que dé cuenta de las últimas decisiones.
- Título del proyecto: Entorno de uso público de la Base de Datos Lexical del Euskera (EDBL).
- Objetivo del proyecto: Difusión en Internet del uso de algunos productos del grupo IXA para su incorporación al euskera.
- Director: Xabier Artola Zubillaga.
- Equipo de trabajo: Grupo IXA E. Agirre, I. Aldezabal, I. Alegria, O. Ansa, X. Arregi, J.M. Arriola, X. Artola, A. Díaz de Ilraza, N. Ezeiza, K. Gojenola,J.M. Intxausti, M. Lersundi, A. Maritxal,M. Maritxalar, M. Oronoz, K. Sarasola, A. Soroa, R. Urizar y M. Abedul.
- Departamento: Lenguajes y Sistemas Informáticos
- Centro: Informática de la UPV-EHU (Donostia)
Zu idazle
Zientzia aldizkaria

