

CorpEus: Combinando internet, corpus y euskera
Hoy en día, todas las lenguas necesitan corpus. Los corpus son colecciones de textos etiquetados en formato electrónico y lingüísticamente --el etiquetado lingüísticamente significa que a cada palabra se le otorga su correspondiente lema, categoría, etc.- y se utilizan en la investigación lingüística y en el desarrollo de tecnologías lingüísticas. Son recursos muy importantes para el desarrollo de tecnologías lingüísticas, elaboración de diccionarios, etc. La elaboración de corpus es un trabajo caro, laborioso y difícil de mantener siempre actualizado. Por ello, los corpus en euskera son escasos y pequeños en comparación con otros idiomas.
A través de internet
Pero ahí está Internet o la telaraña, una enorme colección de textos, al alcance de todos, mucho más texto que cualquier otro corpus en euskera. También es un corpus, aunque no está etiquetado lingüísticamente. Estaría bien poder consultarlo o explotarlo como corpus. Es lo que hace CorpEus.
Ya existen en la red herramientas como WebConc o WebCorp, pero también hay otras herramientas y buscadores de Internet que tienen dos problemas con el euskera: por un lado, sólo pueden buscar una forma concreta y no todas las formas de una palabra o lema a la vez --por ejemplo, nos interesa buscar tierra, tierra, tierra, tierra, etc.-, y por otro lado, si la forma en euskera no es demasiado sulfúrica, y pueden dar resultados en un software, por ejemplo.
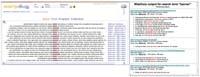
CorpEus nace para superar estos límites. Esta herramienta, desarrollada por el grupo de I+D de la Fundación Elhuyar, con la colaboración del Grupo IXA de la Facultad de Informática de la UPV/EHU, permite utilizar Internet como corpustzat en euskera. Y es que Internet es un corpus gigante, mucho más grande que cualquier corpus en euskera. Además siempre se está actualizando y añadiendo contenido, por lo que se pueden consultar las palabras más recientes.
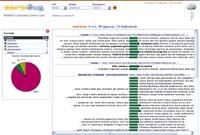
CorpEus utiliza las APIs de los buscadores de Internet (puede moverse con Google, Yahoo o Microsoft) para saber en qué página aparece una palabra --las funciones que ofrece el servicio APIs (Application Programming Interface) para utilizarla desde otro programa-. A continuación, muestra, en su contexto, todas las manifestaciones de la palabra contenida en dichas páginas. También muestra el número de apariciones.
Puede ordenar los resultados en función de diversos factores, mostrando el análisis lingüístico de los resultados. Funciona con varios tipos de documentos (HTML, XML, RSS, RDF, TXT, DBF, DOC, RTF, PDF, PPT, PPS, XLS). Además, la búsqueda se realiza solucionando los dos problemas del euskera: busca según el lema y sólo ofrece páginas en euskera, según nos ha explicado Igor Leturia, responsable del proyecto CorpEus y investigador del grupo de I+D de la Fundación Elhuyar.
Utilizan una herramienta desarrollada por el Grupo IXA de la Universidad del País Vasco/Euskal Herriko Unibertsitatea para mostrar una forma concreta y todas las posibilidades que se derivan de su lema. De esta forma se solicitan todas las formas al API utilizando el operador OR. Por ejemplo, si el usuario pregunta por la palabra casa, al buscador se le pondrá: etxe OR etxea OR a OR... Se ha solucionado el primer problema. Por supuesto, los buscadores no admiten tantas opciones como deseen, por lo que no se envían todas las declinaciones, pero sí lo suficiente para obtener resultados significativos.

Resultados en euskera
Como ya se ha mencionado anteriormente, no existe ningún buscador que sólo refleje los resultados en euskera. Esto es un problema si la palabra que queremos encontrar se dice igual en otras lenguas. Es lo que ocurre con palabras técnicas como la anorexia, el sulfuroso y el byte, con palabras cortas -- gato y la leche, por ejemplo - y con nombres propios -- Fiji y Newton, entre otros. De hecho, las búsquedas de palabras técnicas son muy habituales y útiles en los corpus en euskera, ya que la terminología no está suficientemente normalizada en euskera.
Para obtener únicamente los resultados en euskera, CorpEus utiliza filtros. Los investigadores del grupo de I+D de la Fundación Elhuyar han colgado como filtros las palabras más utilizadas en euskera, todas ellas relacionadas con una AND. Para conocer las palabras más utilizadas se ha utilizado un corpus.
Desgraciadamente, las palabras más utilizadas en euskera ( y, es, no, ) son cortas, se utilizan con frecuencia en otras lenguas y, en ocasiones, pueden ser abreviaturas y acrónimos. Por lo tanto, no hay palabras mágicas, es decir, palabras que sólo aparezcan en textos en euskera y que puedan utilizarse como filtro. Es y es la palabra más utilizada en euskera. Pero ETA es también un acrónimo que se utiliza frecuentemente en los medios de comunicación en muchas lenguas. Otra de las palabras más utilizadas es el verbo, pero en ruso sí.

Por lo tanto, ¿cuántas de estas palabras hay que utilizar como filtro para realizar la búsqueda únicamente en páginas en euskera? Según Igor Leturia, "cuantos más palabras uses, más concreta será la búsqueda y, por lo tanto, menos resultados que no sean en euskera. No obstante, tampoco mostrará algunos resultados en euskera, ya que alguna o algunas de estas palabras no aparecen en ellas".
Algunos límites
CorpEus complementa a los corpus hasta ahora. Sin embargo, además de ventajas, tiene algunas desventajas. Por un lado, como ya se ha mencionado anteriormente, al tratarse de Internet no etiquetada lingüísticamente, siempre tendrá cierta incertidumbre con palabras con más de un lema. En la búsqueda de la palabra pelotari, por ejemplo, ya que es un dativo de la palabra pelota y una persona que juega a pelota. Otro inconveniente es que, en gran medida, no se ha peinado -sobre todo blogs, foros, contenido personal, etc.-, aunque puede verse como una ventaja (por ejemplo, porque se da un modelo cercano al lenguaje oral), también es una desventaja, ya que puede ser de peor calidad y defectuosa.
Por otro lado, nunca se podrá ver todo lo que hay, ya que normalmente los buscadores tienen un límite de mil páginas, por lo que sólo se pueden mostrar los resultados de estas páginas. Y por último, CorpEus es dependiente de los buscadores: por un lado, los resultados de la herramienta dependen del orden de sus resultados y, por otro, de los cambios que realizan en los APIs y de las limitaciones que ponen a los APIs.

En cualquier caso, CorpEus ha sido el primer intento que ha unido internet, corpus y euskera. Seguramente no será la última. De hecho, en otras lenguas también se necesitan corpus cada vez más grandes para las tecnologías lingüísticas, para lo que la tendencia a utilizar Internet está creciendo de forma notable.
Página web del proyecto CorpEus: http://www.corpeus.org
Zu idazle
Zientzia aldizkaria

