

Modernización tecnológica del vocabulario

Uno de los cuatro departamentos principales de Elhuyar es el de Lengua y Tecnología. Dentro de ella se subdividen en servicios de traducción, lexicografía y tecnologías lingüísticas. Las tecnologías lingüísticas son muchas y son útiles en muchos ámbitos. Y nosotros también investigamos, desarrollamos y comercializamos aquellos que son útiles para muchos campos, pero, como es normal, trabajamos especialmente aquellos que son útiles para otras áreas de Elhuyar. Por ejemplo, en los servicios de traducción trabajamos la traducción automática y las tecnologías de memorias de traducción que pueden aportar una ventaja competitiva, así como muchas tecnologías de interés para el vocabulario.
Facilitando el proceso de trabajo
Uno de los trabajos a realizar en la elaboración de diccionarios es la selección de palabras. Hemos desarrollado herramientas de apoyo a ello, mediante la aplicación de corpus textuales, combinando técnicas lingüísticas y estadísticas que extraen las palabras, términos o localizaciones más significativas de las mismas.
Uno de ellos es Erauzterm. Tras ofrecer un corpus especializado en una determinada área del euskera, Erauzterm detecta los términos que aparecen en ella. No es perfecto en la medida de las herramientas automáticas, pero tiene una interfaz para realizar un repaso manual.
ElexBI hace algo parecido pero en bilingüe. A partir de un corpus paralelo (recopilación de textos que son traducciones entre sí, alineados a nivel de frase), extrae sus equivalencias de términos, es decir, los pares de términos de ambas lenguas. Esta herramienta se ha habilitado como servicio web con el nombre de Itzulterm. Y con esta herramienta se ha elaborado el diccionario de Formación Profesional.
AzerHitz hace lo mismo que Elexbi, pero en lugar de tomar como materia prima corpus paralelos (ya que los corpus paralelos no están tanto como se quiera o no son tan grandes como se quiera, sobre todo en áreas especializadas o en determinados pares de idiomas) utiliza corpus comparables. Estas son colecciones de textos multilingües que tratan un mismo tema sin tener que traducirlos entre sí. AzerHitz es capaz de extraer una terminología bilingüe de este tipo de corpus.
Otro de los instrumentos para extraer información lexicográfica de los textos es el Konemat. Este extrae de los textos en euskera las combinaciones, encolaciones, fraseología, etc. De momento, saca las combinaciones más usuales de nombres, adjetivos y nombres.
Tenemos también la herramienta PopLex, que crea nuevos diccionarios utilizando dos diccionarios y un lenguaje puente. Se publicaron cinco diccionarios en euskera online creados con él en el portal de diccionarios construidos automáticamente, tal y como os contamos en julio.
Materia prima de trabajo, corpus
Como habéis visto, muchas de estas tecnologías necesitan de corpus, y por eso es una de las áreas en las que trabajamos mucho la corpus digital. Junto con el Grupo IXA de la UPV/EHU creamos el Corpus de Ciencia y Tecnología; para la Fundación Eroski formamos el corpus multilingüe de la revista Consumer; y para Euskaltzaindia, estamos formando el Corpus del Observatorio del Léxico junto con el Grupo IXA y UZEI.
Sin embargo, dado que la elaboración de corpus es costosa, en los últimos años estamos creando herramientas para poder utilizar la web para formar corpus. Para poder consultar Internet como corpus, hace unos años lanzamos el servicio CorpEus online. Y desde la web tenemos también herramientas para crear automáticamente grandes corpus generales, corpus especializados, corpus paralelos y corpus comparables. A través de un gran corpus general en euskera construido automáticamente desde la web, un gran corpus paralelo euskera-castellano y las combinaciones extraídas del gran corpus general a través de la herramienta antes mencionada, se pusimos a consulta en el Portal de corpus Web, tal y como os comentamos en febrero.
Nueva web de Elhuyar Hiztegiak
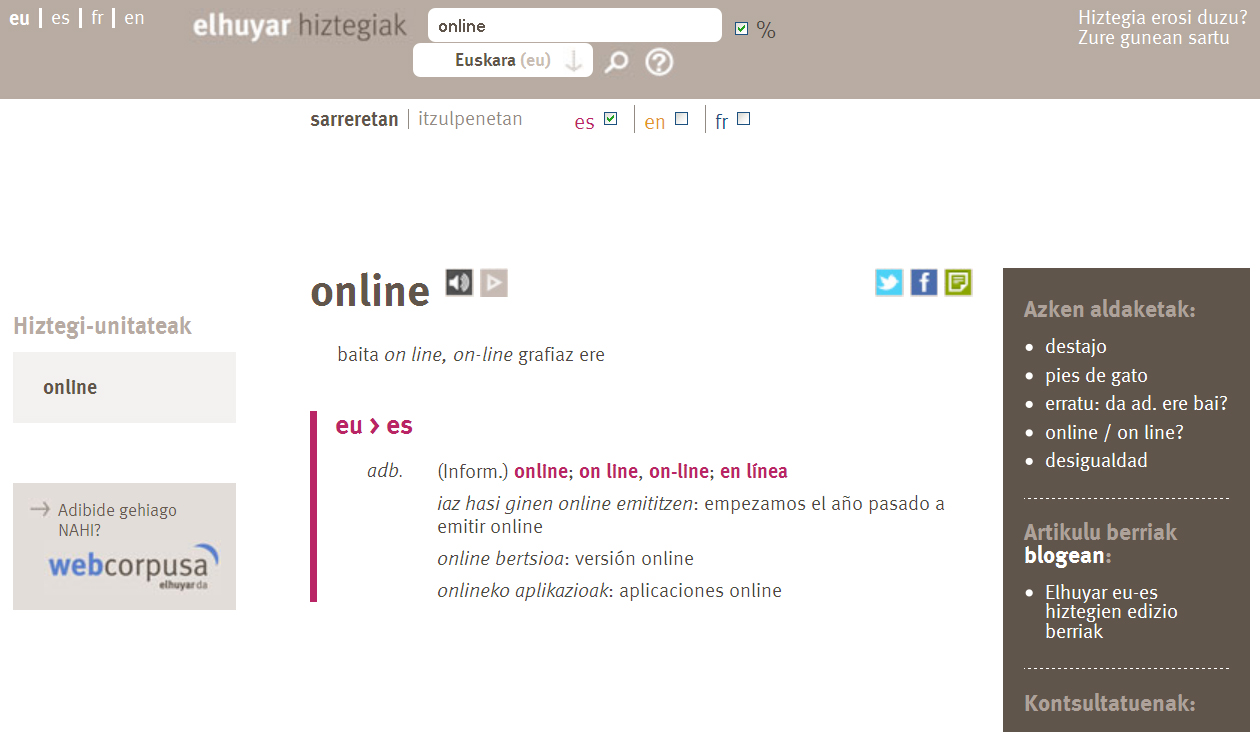
Además de facilitar el proceso de trabajo de elaboración de diccionarios y suministrar corpus electrónicos para materias primas, la tecnología en general y las tecnologías lingüísticas en particular pueden mejorar considerablemente la experiencia de los usuarios del diccionario. Desde que hace unos años comenzaron a colocar los diccionarios en la web, en la mayoría de los casos se ha ofrecido la opción de las cajas de búsqueda para poder realizar búsquedas rápidas en lugar de ir a buscar en una lista ordenada alfabéticamente (aunque ya existen las que simplemente se limitan a poner online los PDFs de los diccionarios). Pero los resultados que se ofrecen tras la búsqueda son similares a los que ofrecen los diccionarios en papel. En la nueva web de Elhuyar Hiztegiak (http://hiztegiak.elhuyar.org/), que cuenta con diccionarios euskera-castellano, euskara-francés y euskara-inglés, hemos querido ir más allá y ofrecer opciones más avanzadas.
Por ejemplo, se puede escuchar cómo se pronuncia una palabra buscada a través de dos opciones: A través de los audios grabados por los usuarios en la web Forvo, o mediante la tecnología TTS (text-to-speech o síntesis de voz), es decir, a través de la voz sintética creada por el ordenador. El sistema TTS que utilizamos es el desarrollado por el Grupo Consultab de la UPV y que comercializamos.
Además, cuando queremos buscar una palabra, a medida que vamos tecleando la palabra, nos muestra la lista de palabras que tienen ese inicio, evitando así tener que escribir todo y reduciendo las posibilidades de escribir erróneamente.
Por otro lado, en lo que se refiere a los ejemplos de palabras, además de los habituales introducidos por los autores en el diccionario, esta nueva web permite visualizar los ejemplos que se encuentran en el corpus paralelo euskera-castellano extraído de la web anteriormente mencionada. Estos ejemplos no son sólo de la lengua de destino, sino de pares de frases que son traducciones entre sí.
Además, además de la búsqueda habitual de entradas de la lengua de origen, se ofrece la posibilidad de buscarlas en las entradas de la lengua de destino. Y se quiere ofrecer la posibilidad de buscar en futuros ejemplos.
También se ofrecen opciones para personalizar el diccionario, como guardar las últimas búsquedas realizadas, guardar algunas búsquedas en una lista de favoritos personales, etc.
A pesar de que por el momento hemos publicado estas novedades, en el futuro está previsto introducir más cosas poco a poco. Por ejemplo, la posibilidad de ir directamente al buscador de combinaciones antes mencionado, mostrar también los resultados de otros diccionarios y corpus, proponer una palabra correcta cuando se ha escrito mal, mostrar las declinaciones o inflexiones de la palabra buscada…
¡Y más futuro!
Además, en los próximos años queremos tecnologizar aún más nuestra sección de vocabulario. Seguimos trabajando en la construcción de corpus para mejorar y crear nuevas herramientas de construcción automática de corpus, con las que cada vez se forman más corpus, más grandes y de nuevos pares de lenguas. Nuestra intención es que estos nuevos corpus se coloquen también online en el Portal de Corpus Web.
Pero la principal novedad vendrá del ámbito de la automatización del vocabulario. La mayoría de este tipo de tecnologías que hemos trabajado hasta ahora extraían de los corpus palabras y términos para el diccionario y sus contraprestaciones, pero además un diccionario necesita definiciones, sentidos y ejemplos. Pues bien, ahora también hemos empezado a trabajar en la forma de obtenerlos de forma automática, es decir, en la extracción automática de definiciones, acepciones y ejemplos adecuados de textos y/o webs.
Siguiendo con la explotación de las tecnologías lingüísticas que ya teníamos y desarrollando las que acabamos de poner en marcha, queremos que el diccionario de Elhuyar sea puntero para que en un mundo cada vez más globalizado el euskera pueda seguir en contacto con otras lenguas.Zu idazle
Zientzia aldizkaria


